
26 Oct 2022 What is Matillion and How Does It Work?
Over the last couple of years, cloud-based ETL tools have been gaining in popularity, providing a fresh perspective on the traditional ETL frameworks and promising faster and easier development, as well as better integration with modern platforms.
One of the more prominent tools is Matillion, a data integration tool built specifically for the cloud. Matillion follows the ELT approach, loading source data directly into a database and offering data transformation and preparation for analytics using the power of a cloud data architecture.
We wanted to see what it offers so we carried out a proof of concept, experimenting with some of the tool’s features, and this is what we found.
About Matillion
Matillion ETL currently comes in five editions, each using one of the cloud data warehouses/lakes as its main data platform: Snowflake, Amazon Redshift, Google BigQuery, Azure Synapse, and Delta Lake on Databricks. For the purposes of our Proof of Concept (PoC), we chose the Snowflake edition, with Microsoft Azure as our cloud provider.
While researching Matillion online, we noticed that one of its most mentioned features is the intuitive user interface which makes coding optional, significantly reducing the maintenance and overheads associated with hand-coding. The GUI follows the standard for ETL tools, and all the components are easy to find and have a built-in documentation panel for quick reference during development.
Another highly praised feature is the option to use the many pre-built connectors for the most popular applications and databases, or to quickly develop a custom connector, making it possible to connect Matillion to virtually any data source.
Going through the list of over 70 available connectors, it is clear that Matillion is focused on semi- or non-structured data sources. Some of the popular services are Gmail, LinkedIn, Twitter, Salesforce, LinkedIn, PayPal, Kafka, and Hadoop; however, Matillion also offers connectors to some more traditional data sources, such as IBM Netezza, MySQL, Postgres, IBM DB2, and Oracle – it can connect to almost anything!

Data Transformations
In our PoC we went through what we consider to be the most important aspects of an ETL tool, as well as trying out the functionalities we use every day to build ETL pipelines.
Extract
The first point of this process was to explore the ways data can be loaded into the Staging area. Apart from loading the data straight from our Snowflake tables, we used the Database Query component and components for CSV loading and API extraction.
Using the API Query component, we successfully extracted data from an open API endpoint; we used the Query Profile interface to define the API endpoint and then used the GET method to load the data.
The flat file we used to test the CSV component was stored in our AWS S3 bucket. As previously mentioned, our cloud provider was Microsoft Azure, which made it easy to use the built-in credential manager to connect to AWS.
When testing the Database Query component, we used Oracle Autonomous Database. After some issues with SSL authentication, the data was finally loaded into Snowflake as well.
Transform
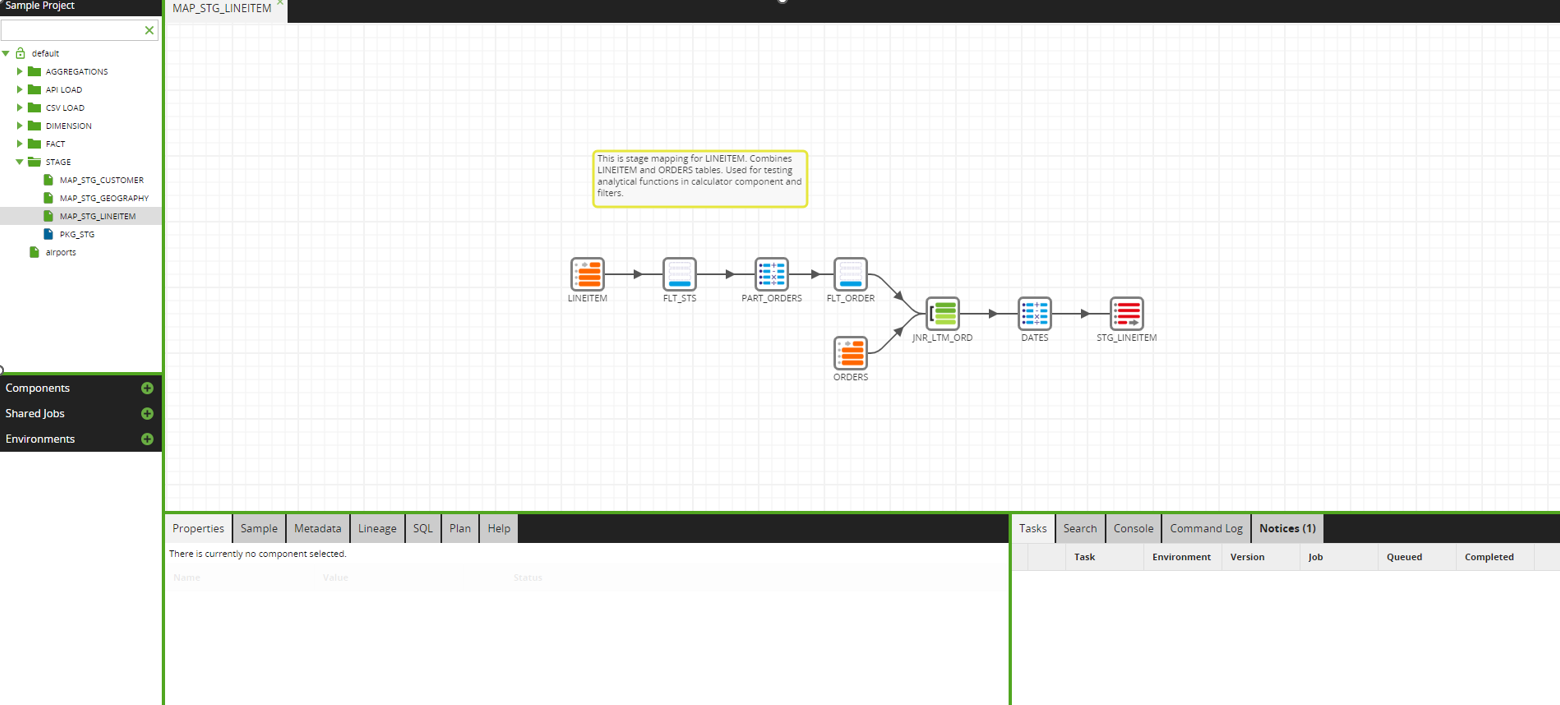
Once the data had been loaded into our Snowflake environment, it was time to create several transformation jobs and use the Data components which are more oriented towards data manipulation and transformation. All the available components are pictured below:
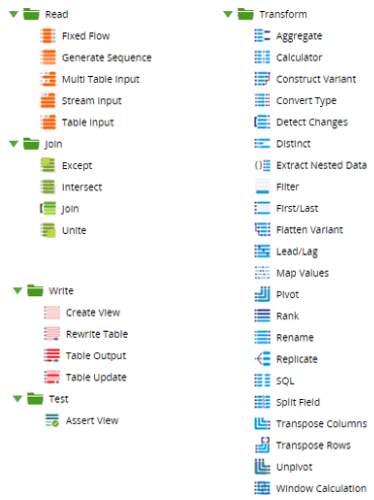
We focused on testing the following components:
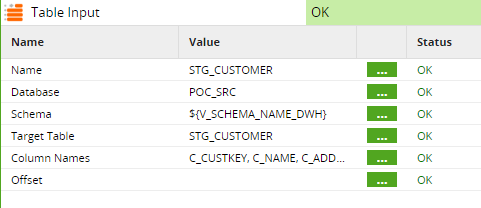
Table Input – read chosen columns from an input table or view in the job. To be able to read data from one schema and write to another, an environment variable must be created and point to a schema different from the source/target schema.
Table Output – insert data into the target table.
Table Update – merge data into the target table.
Join – join two or more sources with all standard types of join.
Calculator – create expressions and new columns.
Detect Changes – scan two separate (but similar) tables and insert a new column detailing if data has been inserted, deleted, changed, or even if the data is unchanged (C, D, I, N).
Filter – filter the data based on an expression.
Replicate – replicate one dataset into two branches.
SQL – query data in a database (DB) and use the result as a table.
Window Calculation – a list of available analytical functions (Average, Sum, Minimum, Maximum, etc.).
All the components are customisable up to a point, providing a balance between flexibility and the fool-proof implementation of common transformations. Using some of these components reduces the need to hardcode functions into expressions, making it easier to debug and keep track of the flow. However, a purely graphical tool has its limitations too, and that won’t sit well with advanced users – you cannot write more complex filters, expressions or joins than those anticipated by the tool. For example, it doesn’t allow the user to write queries in any component rather than the Query component itself.
Besides Data components, the tool offers a set of Orchestration components, which define the behaviour of the Matillion flow. These components are connectors, iterate mechanisms, scripts, DDLs, variables, and other ETL objects.
Slowly Changing Dimensions
Thanks to Matillion’s extremely intuitive UI, we encountered very few issues while creating the transformation jobs and using the available components. However, we encountered some issues when trying out the options to create a job for the Slowly Changing Dimension (SCD). The standard algorithm for the most common SCD2 type is to invalidate the old row and insert a new one with up-to-date information, so the entire history is recorded and can easily be replicated if needed.
There are several ways to approach this in an ETL tool, and we decided to utilise the Detect Changes component which would divide our flow into two branches, marking the rows which need to be updated and those that need to be inserted.
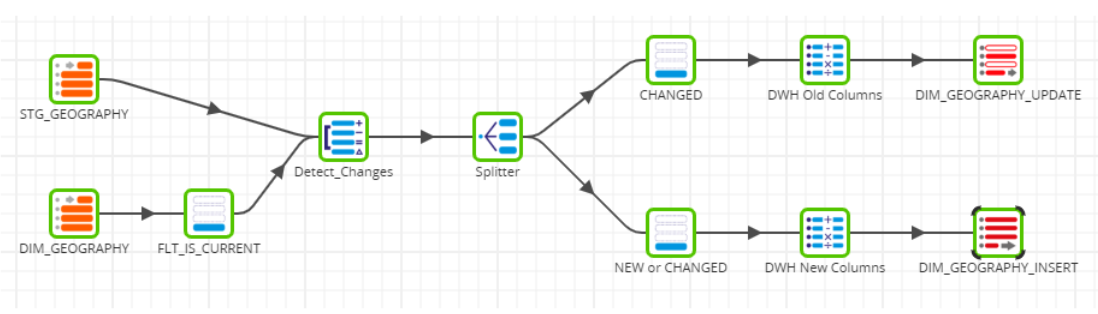
After we ran this job a couple of times, we noticed that there was no control over the branch execution order, which meant that sometimes the newly inserted rows got marked as invalid. In order to work around this issue, we split the branches into separate jobs and created an orchestration job which defined the exact order of execution:
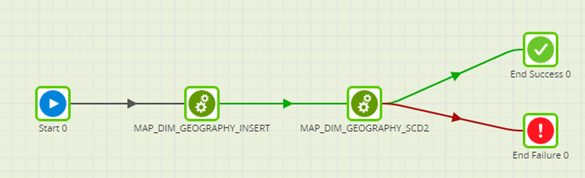
The first job inserts all the new rows in the target table and the second job executes the SCD2 algorithm. This solution gives us full control over the job.
Load
For the loading phase of our POC, we wanted to test several things apart from the basic job execution.
Error Handling
We tested error handling in Matillion by creating an orchestration job with three transformation jobs, simulating an error in the MAP_STG_CUSTOMER. Our expectation was that once the job had failed, the rows inserted in the first step would be rolled back.
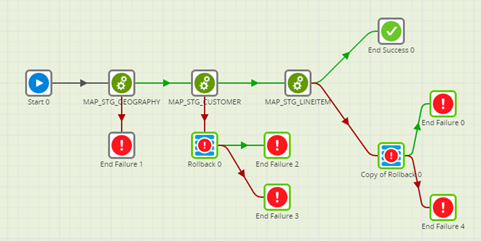
Unfortunately, that didn’t happen; this resulted in an inconsistency in the data. When checking the execution logs, we concluded that there must have been an implicit commit between the first and second jobs.
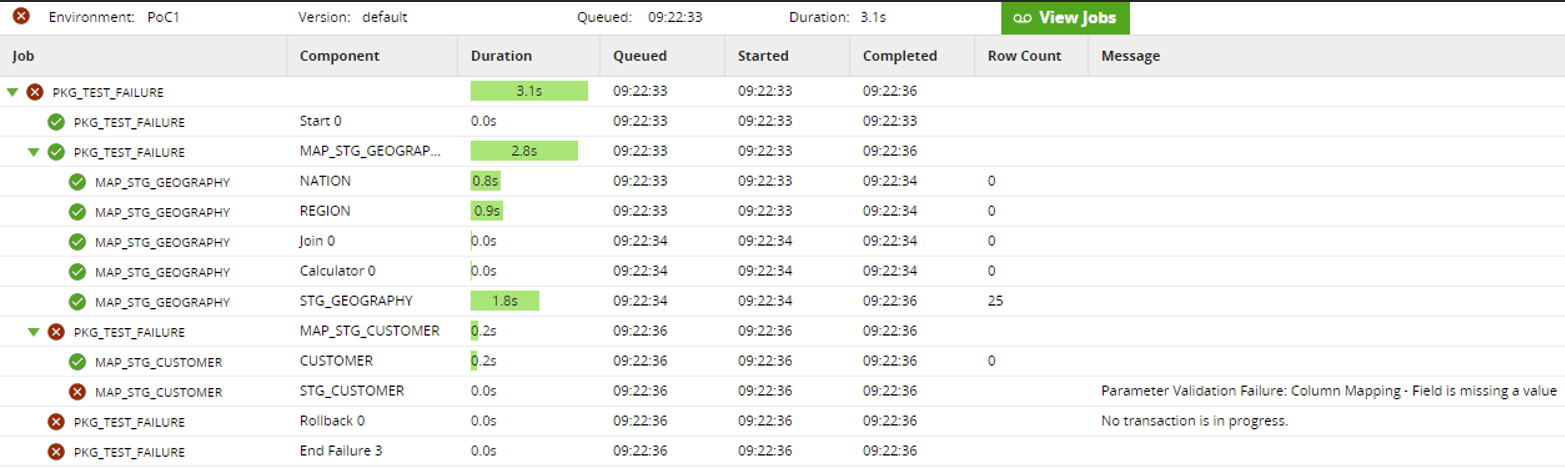
This lack of control over the precise moment a transaction is rolled back or committed inside the orchestration job was slightly disappointing, since it’s an important part of making sure the flow is atomic and easily restarted if there’s an error.
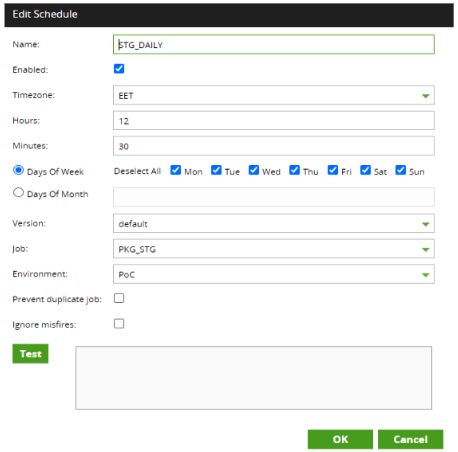
Scheduling
Being able to schedule the automatic execution of a job is another important process in creating an ETL pipeline. Matillion offers a simple wizard which makes it easy to create schedules for executing jobs:
Switching Between Environments
Matillion supports multiple types of variables – Environment, Automatic, Job, and Grid. We used environment variables to save the schema names in our different environments. This was especially useful to test how the jobs executed with differently sized datasets. For this purpose, we used the Snowflake sample dataset which comes in four sizes with different orders of magnitude.

Using the environment variable as a value for the schema name instead of hardcoding the value avoids the need to manually change the schema name for every table in the job whenever we need to run it in a different environment.
Performance Tests
Using the environment variables made it both quick and easy to repeat the job executions and evaluate how scalable the tool really is. Most of the transformations were simple, but the most complicated featured several resource-consuming components, such as the Window function, where the amazing performance of Matillion and Snowflake shone, as the tool continued to work seamlessly while executing everything in the background.

Versioning and Documentation
The final phase of our PoC was to try out the functionalities to manage the objects and metadata in the environment; this included GIT integration and automatic documentation generation.
GIT
The main purpose of trying to connect to GIT was to see if it can be used to enforce version control and object propagation between environments, whilst making it easier to collaborate with other team members.
There are four main GIT commands in Matillion:
GIT COMMIT – to save changes in your local repository.
GIT FETCH – to pull the job from the remote repository.
GIT PUSH – to upload the job to a remote repository.
GIT MERGE – to merge branches.
Matillion GIT integration is well-documented and performed as expected. It enabled us to create a repository with all our objects, helping to track changes, and it was also handy for keeping a backup of the entire environment.
Documentation
The last test we did was to try out the built-in functionality which enables the user to generate the documentation for each job. The documentation is created as an HTML file containing an overview of the job, separate explanations for every component, including the parameter values, and additional notes or descriptions provided by the developer. This was very useful when we wanted to reference or analyse a mapping, as it provided a clear and structured document about every object involved in the process.
Conclusion
After spending some time working with Matillion, our conclusion is that it is very simple to use and works amazingly with Snowflake. Because the UI is very intuitive, the user does not need to have extensive coding knowledge in order to get started and set up a simple ETL pipeline. On the other hand, the simplicity of the tool can sometimes be a downside since it does not support some advanced techniques, and it would be useful if in the future there was better control over commits, rollbacks, and the code being executed.
Taking everything into account, we found that Matillion is a promising contender in the new generation of low-code ETL tools, and we are excited to see what the future holds for this new wave of cloud-based tools. If you’d like to know more about what ETL tool would be best for your technology stack, contact us and our team of expert consultants will be happy to help you!
