30 Ene 2025 Tackling Data Quality in Cloudera with Great Expectations
Data Quality (DQ) is a critical component of Data Governance (DG), guaranteeing that the data used for analysis, reporting, and decision-making is reliable and trustworthy. Poor data quality might lead to incorrect conclusions and decisions. This is true regardless of the tech stack being used, and more and more tech vendors are adding services and solutions to their offerings to manage both DQ and DG. Today, we’ll focus on Cloudera.
Cloudera has recently been adding interesting DG capabilities to its Cloudera Data Platform (CDP), an example of which is the revised Data Catalog. As we saw in our previous blog post, in addition to “typical” cataloguing and classic Atlas features, Cloudera Data Catalog introduces new elements like data profiling. However, whilst this feature allows you to calculate some statistical metrics of the catalogued datasets (such as min, max and average values), it does not offer a direct way to define and run validation rules to periodically check (and report) the data quality of your datasets.
So today we want to present an approach to solve this: how to implement a DQ framework within Cloudera – no matter whether you are running on private or public cloud!
There are two common ways to go about this: one is to use commercial software that is compatible with Cloudera and that complements its missing features in the DQ domain, whilst the other is to build a DQ framework from scratch to tackle your DQ requirements. The obvious pros and cons of both approaches are that, by using a commercial approach, you speed up time-to-value, but with an economic impact due to extra licensing fees. On the other hand, by building a DQ solution from scratch, you save on licensing fees, but at same time need to invest time in building, testing and getting the solution up to the required standards.
Which one is better for you will depend on budget, timelines, team skillsets, exact requirements, current architecture, and so on. Today, we want to focus on the second way – building a DQ framework from scratch – since it just got much easier. Because, thanks to what you will read next, you don’t really have to build it from scratch!
Enter Great Expectations
Numerous open-source data quality tools are available in the market these days, and amongst them, Great Expectations (GX) stands out as a winner.
In this article we’ll see how, using GX, it is possible to build a framework for tackling DQ in your Cloudera environment. First, we’ll introduce GX, describe how it works and explain which of its features make it an excellent choice for DQ. Then, we’ll describe how to create a robust DQ framework for Cloudera with GX, using our simple plug-and-play templatised scripts that can be customised to your requirements, whilst also offering a standardised DQ validation output to facilitate the monitoring and reporting process. Finally, we’ll dive into a demo to showcase all of the framework capabilities and benefits.
Note: the approach we present in this post is built upon the work done by Santiago Merchan.
What is Great Expectations?
Great Expectations (GX) is a platform for data quality. The original offering is called GX OSS, and it is a robust open-source Python framework that lets you set and validate rules, known as expectations, for your data, ensuring it meets your defined quality standards. GX is also offered as a SaaS platform, GX Cloud. In this blog post, and for our proposed approach, we are focusing on GX OSS.
In addition to allowing the setting and validating of rules (expectations), other key aspects of GX include automatically creating expectations based on an analysis of your data by leveraging the Data Assistants feature; automatically generating reports that track your data changes; and crucially, the ability to integrate with various data platforms. These include relational databases, file formats, NoSQL stores, and cloud data warehouse solutions such as Databricks, Snowflake, Athena, and Google BigQuery. Additionally, GX supports Python data structures like Pandas DataFrames and dictionaries, which can originate from almost any source system. In the context of Cloudera, this could include a Hive/Impala table, a Solr collection, or an HBase table, amongst others.
We recommend you read the official GX documentation for more details. Now let’s review the key aspects of GX that need to be borne in mind when using it within Cloudera.
Expectations
Expectations are the main building blocks of GX. An expectation is a defined validation over a column of a dataset. GX’s built-in library includes more than 50 common expectations, such as:
- expect_column_values_to_not_be_null
- expect_column_values_to_be_between
- expect_column_values_to_be_unique
- expect_column_to_exist
- expect_table_column_count_to_equal
Note there are also expectations designed for a set of columns, or for entire tables, such as expect_table_row_count_to_equal; you can also create your own custom expectations.
Execution Engines
A key concept to cover, specifically in the context of Cloudera, is the Execution Engine, which determines where validations are run and which compute resources are used.
GX supports the following execution engines: Pandas, SQLAlchemy, and Spark.
- The Pandas execution engine relies on the same Python engine that runs GX, so compute resources are limited to those available on the server hosting GX.
- The SQLAlchemy execution engine allows computations to be pushed down to the underlying SQL engine, which is very handy for data residing on SQL databases.
- The Spark execution engine uses Apache Spark to validate the defined expectations. This engine is key in the context of Cloudera, as it integrates seamlessly with CDP and can handle DQ checks for large datasets.
Data Quality Framework for Cloudera with Great Expectations
Now that we are familiar with GX and the relevant features, let’s see how we can tackle DQ on Cloudera with GX:
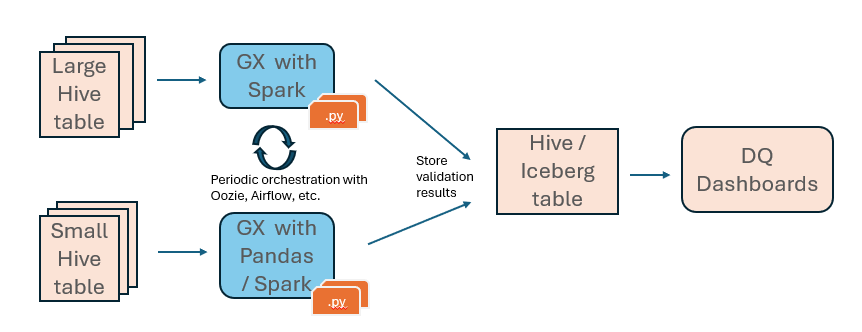
Figure 1: A high-level representation of our DQ framework
Let’s review the main concepts behind our proposed DQ framework:
Target Tables: Typically, DQ validation focuses on curated data that is exposed to business users or applications. For example, in a medallion architecture, this would mean targeting tables in the silver and gold layers.
Engine: Obviously, some of these tables might be larger than others. Our approach here is to use the Spark engine for big tables (via PySpark scripts), whilst for smaller tables, we use the Pandas engine to save some cluster resources.
Grouping: We suggest grouping the various validations into different jobs/scripts, depending on their nature and the target tables. For example, you could use one script to run basic null and unique checks on all silver tables or to check personal data across all customer tables at once. This approach simplifies scheduling, monitoring, and auditing processes and minimises computational overhead, especially for Spark jobs. The specific grouping will depend on your needs, but we offer templates that can be extended and customised.
Scheduling and Orchestration: Thanks to the flexibility of Spark and Python jobs, you can use the orchestration tool of your choice. In Cloudera, that could be Oozie if you are using a base cluster, or Apache Airflow if you are using the Cloudera Data Engineering Data Service. Third-party orchestration tools are also an option, provided they support Spark and Python.
Output: A key part of our proposed framework is to standardise how validation results are stored. By default, GX writes results in JSON files or similar formats. Our proposal is to store them as Hive tables, making them accessible as sources for DQ dashboards. Iceberg is an even better option, if available, as it enables historical views of results through its time travel feature – check out our blog post here to learn more. While GX ships with basic visualisation features, these are limited to simple reporting and require further configuration for advanced use cases.
Although we are focusing on Hive/Impala tables, other data structures such as HBase tables and Solr collections may also exist in a Cloudera environment, and our framework is still applicable. For PySpark, we would need to use the available HBase and Solr connectors.
Demo
Now let’s dive into a quick demo to showcase the proposed framework in action!
We will validate data from a dummy dataset stored in two Hive tables: employee_monthly_salary and customer_churn. More specifically, we will evaluate the following three DQ aspects for the values of a few columns:
- That they are not null
- That they fall within a specified range
- That certain values are unique
Please note that we are using a dummy dataset and a few simple expectations, but, as we mentioned above, everything that we’re presenting and demonstrating in this blog post can be extended and customised to fit your needs. So don’t hesitate to contact us to see how we can adapt this framework to your requirements.
Setting up Great Expectations
Let’s start by setting up our environment. First of all, we make sure we have the following:
- Python (3.8 to 3.11)
- A running PySpark environment with Hive support
- A virtual environment for GX installation
- A Python-specific IDE like PyCharm, Jupyter Notebooks, or VS code, to write our code
Now we create a directory in our virtual environment:
python -m venv greatexpectation
After this, we can proceed to install GX. We use pip, but if you prefer you can use conda:
python -m pip install great_expectations
To verify the installation, we run the following command:
great_expectations --version
With the required applications installed and the setup completed, we’ll now go through the step-by-step process of integrating Great Expectations into our PySpark code.
Initialise Great Expectations and Spark
Before we begin working with GX, we need to initialise a few building blocks for our Spark code.
The Data Context is the primary entry point for a Great Expectations deployment. The get_context() method initialises, instantiates and returns a Data Context object:
import great_expectations as gx # Initialize Great Expectations context context = gx.get_context()
Next, we need to define a data source. The data source object offers a unified API for accessing and interacting with data from diverse source systems in a standardised way. Internally, each data source utilises an execution engine (such as SQLAlchemy, Pandas, or Spark) to connect to and to query data, but the engine’s specific API is abstracted through the data source interface. In our case, we create a data source for Spark:
# Define data source
datasource = context.sources.add_or_update_spark("my_spark_datasource")
Finally, we can initialise our Spark session:
spark = SparkSession \
.builder \
.appName("hive_datasource") \
.config("spark.sql.DataQualityImplementation", "hive") \
.enableHiveSupport() \
.getOrCreate()
Create Data Assets and Batches
Let’s create a data frame containing the data to which we want to apply validations:
# create a dataframe
sampleDF = spark.sql(f"SELECT * FROM {dbname}.{table_name}")
The next step is to add the data frame to a data asset which involves organising the data into batches, allowing us to create a validator and to define an expectation object to validate the dataset effectively.
Data assets define how Great Expectations will structure data into batches:
name = "my_df_asset" data_asset = datasource.add_dataframe_asset(name=name)
Create a Batch
A batch offers a way to describe specific data from any data source, acting as a direct link to that data:
# Create batch request for Great Expectations batch_request = data_asset.build_batch_request(dataframe=sampleDF)
Define Expectation Suite
An Expectation Suite is a set of testable statements about data:
# Define and update expectation suite
expectation_suite_name = f"analyse_{table_name}"
context.add_or_update_expectation_suite(expectation_suite_name=expectation_suite_name)
Create Expectations
As discussed above, expectations are the main building blocks of GX. To create expectations, we need a validator object.
The validator is the core functional component of Great Expectations, responsible for executing an expectation suite on a batch request:
# Create validator
validator = context.get_validator(
batch_request=batch_request,
expectation_suite_name=expectation_suite_name,
In this use case, we are creating data frames for a set of tables. For each data frame, we create a batch request and define expectations. The expectations for each table may vary, depending on their schema and specific data requirements:
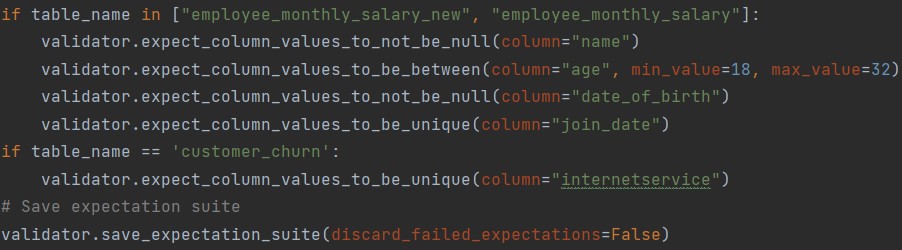
Figure 2: Define Expectations
Note: If we want to run expectations for a new column, we must add the corresponding validator rule for that column:
………………………………………………………………………………………………………………………………. validator.expect_column_values_to_not_be_null(column="new_column_name")
Create Checkpoints
Checkpoints offer a streamlined approach to validate batches against expectation suites. We define a checkpoint and run it by calling run(), which validates the data against the defined expectations:
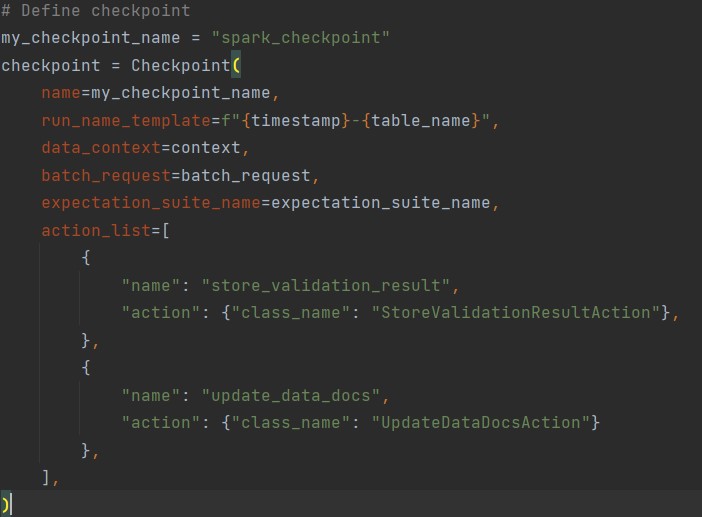
Figure 3: Checkpoint
# Add or update checkpoint context.add_or_update_checkpoint(checkpoint=checkpoint) # Run checkpoint checkpoint_result = checkpoint.run()
Store Expectations results
The results are stored in a JSON file and later read back to extract validation details:
# Write validation result to file
with open(f"{PATH}/{table_name}_validation_check_{timestamp}.json", 'w') as f:
json.dump(checkpoint_result_serializable, f, indent=4)
Below is the list of JSON files generated for each PySpark job run:

Figure 4: Output File List
The JSON file contains the detailed data quality check information, including metrics like element_count, unexpected_count, unexpected_percentage, etc.
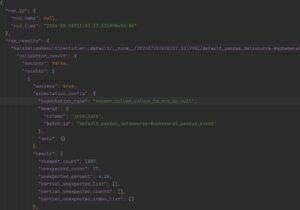
Figure 5: JSON Output
The data quality check results can be viewed in HTML format by utilising the local_site fields in the JSON, which provide the path to the corresponding HTML file containing the validation results:
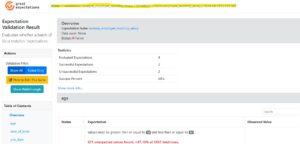
Figure 6: Expectation Results
Next, we’ll read the contents of the JSON file mentioned above and store the resulting data frame in the final Hive table for further analysis:
# Read the file
with open(f"{PATH}/{table_name}_validation_check_{timestamp}.json", 'r') as file:
data = json.load(file)
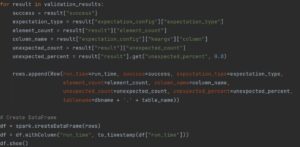
Figure 7: Parse Required Field from JSON
These details are then stored in a Hive table for further analysis:
# Write DataFrame to Hive table
df.write.mode('append').format("hive").saveAsTable("datawash.greatexpectation_result")
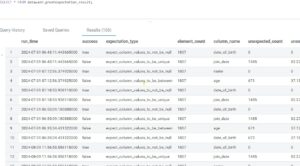
Figure 8: Final Expectations Metrics
Sample Dashboard for PySpark Data Validation with Great Expectations
We’ve imported the validation results from the Hive table into Power BI to perform a more in-depth analysis and to create a dashboard that highlights key insights.
This dashboard will display the unexpected_count and total_count for the age field, based on our job run_time. This analysis focuses on the expectation expect_column_values_to_be_between, enabling us to pinpoint employees between 18 and 32 years old. In our dataset, there were a total of 1,807 records on 31st July 2024. Out of these, 671 records were unexpected (accounting for 37.1% of the dataset):

Figure 9: Age Compliance Monitoring by Job Run Time
After revisiting the data, the team re-ran the job on August 1st, 2nd, and 3rd, 2024, successfully reducing the unexpected_count to 607, 523, and 467 respectively, representing 33.59%, 28%, and 25.82% of the total records:

Figure 10: Age Compliance Monitoring by Job Run Time on August 3rd
Here we can see a slight improvement in our data quality trend.
Now we’ll create another dashboard to highlight the expect_column_values_to_not_be_null expectation. Like the previous dashboard, this will also display unexpected_count and total_count, but this time for the join_date field. This will help us to understand how many employees are tagged with a null join_date. In our dataset of 1,807 employee records, some employees are missing their join date. In the job run on July 31st, 795 employees were marked with a null join_date, accounting for nearly 44% of the total employee records:

Figure 11: Null Join_Date Compliance Monitoring by Job Run Time
The team fixed the data and re-ran the job on August 2nd, 4th, 8th, and 9th. As a result, the unexpected_count percentage was reduced to 38.07%, 29%, 4.2%, and finally 0%:

Figure 12: Null Join_Date Compliance Monitoring by Job Run Time on August 9th
These data quality dashboards can then be used by data stewards to identify and address any detected issues.
Job Execution
When it comes to executing a Great Expectations Spark job, there are various options. You can manually submit the job, or use Oozie, Airflow, NiFi, or other orchestration tools, depending on your requirements. In this section, we’ll focus on two methods: manual job submission and scheduling with Oozie. Each approach has its own benefits, with manual submission being straightforward, while Oozie offers automation and integration within a broader workflow.
Manual Job submission
Manual job submission using the spark3-submit command is a straightforward way to run Spark jobs without any orchestration. By executing the following command:
spark3-submit hdfs:///tmp/greatexpectation_spark_dq_db1.py
You can perform your GX data quality checks on the Spark cluster; this method is ideal for testing and running ad hoc jobs. However, it requires manual intervention for each run, making it less suitable for production environments or workflows requiring automation. For larger-scale operations or automated scheduling, tools like Oozie or Airflow are more practical.
Creating Oozie Workflow and Schedule
Now let’s automate this process using Oozie, available in our CDP cluster. To do this, we need to create a script file (sparksubmit_GX_DQ.sh) containing the necessary Spark submit command:
spark3-submit hdfs:///tmp/greatexpectation_spark_dq_db1.py --deploy-mode cluster --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.minExecutors=1 \ --conf spark.dynamicAllocation.maxExecutors=20 \ --executor-cores 5 --driver-cores 3 --executor-memory 18g \ --driver-memory 12g
This script must then be placed in an HDFS location. Ensure that the spark-submit script file has all the necessary configurations:
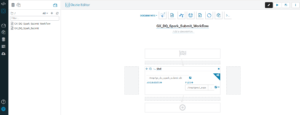
Figure 13: Oozie Workflow Job
Now that the Oozie workflow is set up, we can schedule it to run, for example, daily at 12 am using a CRON expression:
Figure 14: Oozie Schedule
About the Framework
If you’re using a lakehouse solution (Hive/Impala or any other data warehouse) and want to ensure the accuracy of all the data in your tables, this PySpark framework is an efficient way to integrate GX into your data validation process.
What It Does
- The framework begins by creating a Spark session with Hive support and initialising the GX environment. It then connects to a specified Hive database, fetches the list of tables, and iterates over them one by one.
- For each table, the framework loads the data and generates a batch request in GX, defining a set of expectations (data quality rules) for validation.
- A checkpoint is created to validate the data against the defined expectations. The results of the validation, including any discrepancies, are saved to a JSON file, making it easy to review and track data quality over time.
- The validation results are then converted into a PySpark DataFrame and returned to a Hive table, providing a structured way to store and query them. These results can be visualised using Power BI or other BI tools.
Key Features
- The framework is designed to handle multiple tables with varying schemas by customising the expectations for each table. You can easily add new expectations based on the specific data quality requirements.
- This flexible framework can be scaled to handle larger datasets and more sophisticated validation scenarios.
- You can schedule this script to run at regular intervals by using a scheduler like Oozie, Airflow, or NiFi, automating the data quality monitoring process and ensuring the ongoing reliability of your data.
- This script can be integrated into existing ETL pipelines, providing a seamless way to add data validation steps before or after data processing tasks.
Conclusion
In this blog post, we’ve explored how Great Expectations can significantly enhance data quality by validating and documenting large datasets using PySpark and Hive. By centralising data validation, Great Expectations improves data reliability and governance. It establishes and enforces expectations, supporting advanced analytics and fostering seamless team collaboration. These capabilities empower organisations to effectively utilise their data assets, unlocking innovative insights, gaining competitive advantages, and making well-informed decisions.
We hope this post has provided you with a clear understanding of how to leverage Great Expectations in your lakehouse solution for data quality assurance. If you’re interested in implementing a similar data quality solution by integrating Great Expectations with Spark and Hive, we’re here to help. Simply get in touch with us and we’ll get back to you right away!
