18 Jan 2016 BI system on Amazon Cloud | Amazon Web Services
Introduction
The purpose of this blog is to explain how to configure a BI system on cloud using Amazon Web services (AWS). Our system will include an ETL server (pentaho data integrator AKA Kettle), a reporting server (Tableau) and a data warehouse (Redshift). Every of these components will be based on one AWS, these services will be detailed below.
Amazon provides a set of web services completely hosted on cloud in a single account, these services are easy to manage through the AWS console. The services are paid on demand, this helps us to scale up the resources needed and create a budget plan that can be managed and modified easily. It allows the flexibily to remove or add new on demand services.
For payments, AWS provides also a set of dashboards, where we can review the detailed amount broken down by service.
From the variety of the AWS, some of them are enough to create the infrastructure we need to create our BI system completely hosted on cloud.
In this blog article I will explain 3 AWS to create a complete BI system:
- EC2 (used to host the servers, ETL and reporting)
- S3 (used to store and send files to Redshift)
- Redshift (data warehouse)
From the console we can manage all of the web services we have signed up for, in our case we will focus on the following ones:
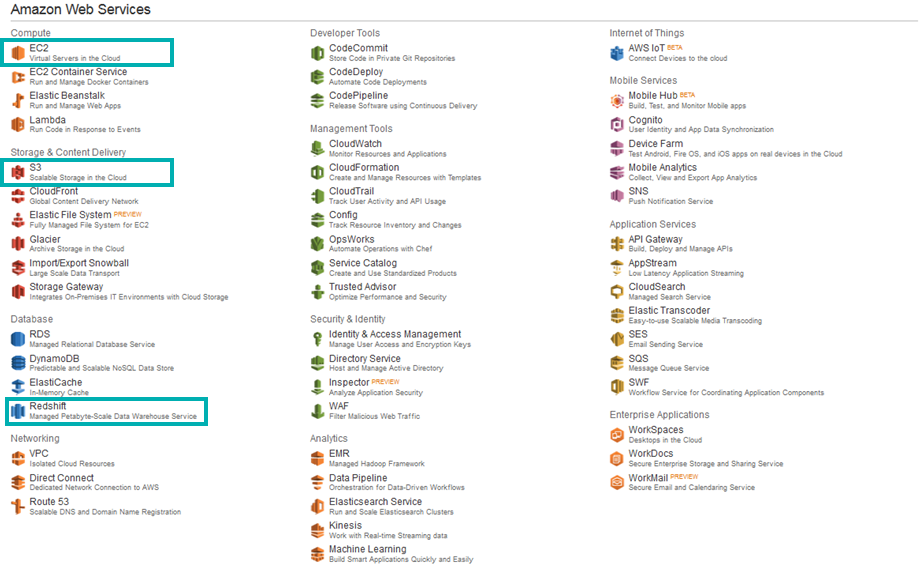
Amazon Web Services
a. EC2
EC2 is a compute AWS used to create instances of machines needed to support our infrastructure, in our case of a BI system, we will use 2 instances, one for the ETL server and a different one for the reporting server.
EC2 is completely dynamic, it allows maintenance of the infrastructure with a simple and intuitive front end, where we can operate into our instances. As main features, it allows resizing of the resources of the instance on demand, to add more memory, increase the number of CPUs and add new HDD volumes to the instance.
There are so many other features detailed on the following video:
In this scenario for our BI system, we have created 2 Windows machines, the instance can be selected from a set of preconfigured machines, then once created we can modify some properties as explained above.
Figure 1 Creating a new instance
There are different prices and paying methods for the instances, the pricing and the licenses for the different sort of instances can be reviewed in the links below:
https://aws.amazon.com/ec2/instance-types/
https://aws.amazon.com/ec2/pricing/
One of the great features on EC2 instance is that with only a little knowledge of IT we can manage the infrastructure by ourselves, we can set up our network, connect to the machines using remote desktop, and share files between the instances and our local machines, we can take snapshots of the volumes, images of the instances that can be downloaded and deployed on premises.
Regarding the network and security configurations, we can assign a static IP to the instances, we can limit the access to that instance to be only reachable from certain IPs, so the instances can be secured.
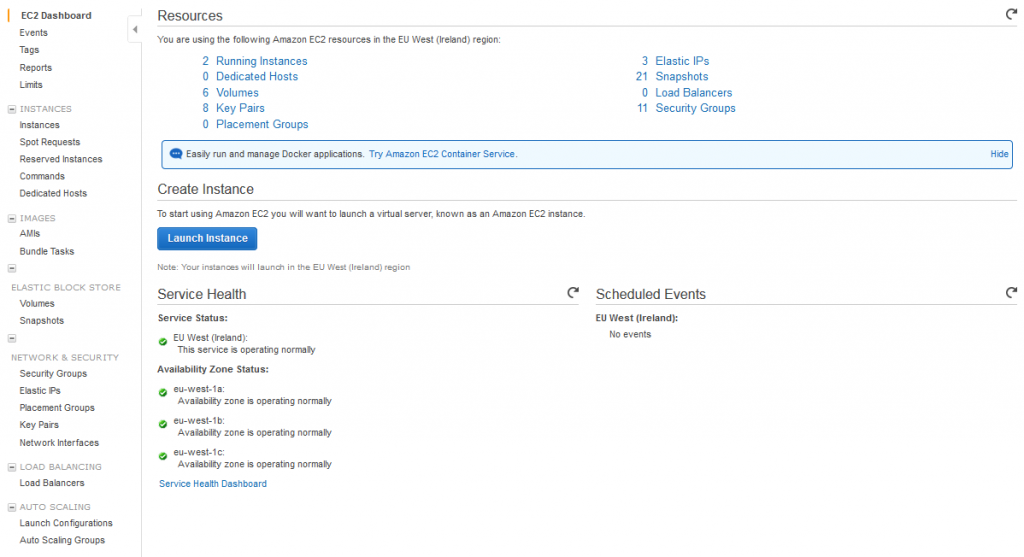
Figure 2 EC2 Landing page
As a conclusion, we can use this service to create any kind of instance that fit our needs and we will pay for the resources and usage we make of it, it is flexible and securable.
For the BI system we want to configure, EC2 will host 2 instances:
- ETL server running on Windows: this server will be the responsible of make the data extraction and transformations and send the files generated to S3. We will use an open source ETL tool, Pentaho data integrator, the features of this ETL tool can be reviewed in the following link:
http://community.pentaho.com/projects/data-integration/
- Reporting server running on Windows: this server will contain the dashboards and visualizations of the information hosted on redshift, we will use tableau as a reporting server, the features of tableau can be reviewed in the following link:
http://www.tableau.com/products/server
b. S3
S3 is one of the storage AWS, basically it is used to store data into a file directory inside a bucket. We will use this service for optimization reasons.
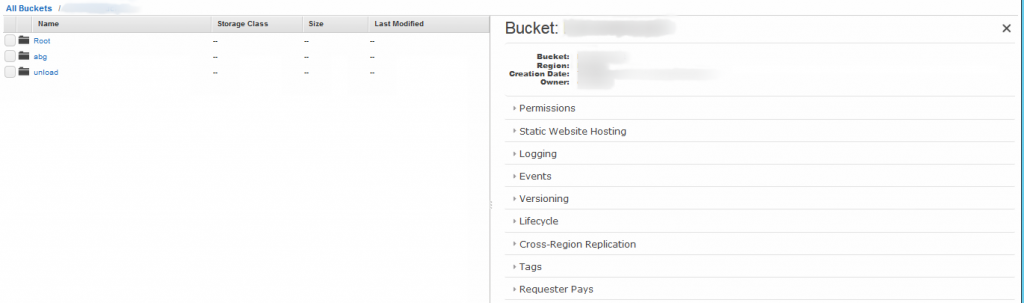
Figure 3 S3 Buckets
One of the bottlenecks that can appear in a BI system is the data loading into the database tables in the data warehouse, as this tables use to be very large, usually we want to bulk load the tables, using the tandem redshift-S3 this can be done in a very efficient way.
Once we have configured our bucket and assign a user to it, we can send files to the S3 bucket given a URL and using the AWS command line interface (AWS CLI). This will improve the performance of the table loads, as the files on S3 can be bulk loaded into tables in a very efficient way.
The service allows to secure the files, add encryption and some other interesting features.
c. Redshift
Redshift completes our BI system, it is a database service, scalable, columnar postgre database.
The latest visualization tools such as tableau, have in built connectors to access the information. It’s easy to connect a database client to Redshift by specifying the URL. Redshift does not support table partitioning or indexing, however we can set sort and distribution keys on our tables to improve query performance, it also allows table compression setting the encoding on the columns.
As explained above, in order to improve the performance, we will use S3 to load the tables, in order to do this, we will create a set of files in our ETL server and after we will send it to S3, once the file has been set we will launch the copy command to load the table, the reference for the copy command can be reviewed at the following link:
http://docs.aws.amazon.com/cli/latest/reference/s3/cp.html
The relation between S3 and redshift is tight, we can also issue commands from our SQL client to store extracts from the tables directly into files in an S3 buckets.
Redshift can be configured in nodes, there are different kinds of nodes depending on our needs, we will chose between the different kind of nodes (computing or storage), once the node has been created it can be resized, it permits snapshots to be taken of the data and the size can be scalable to petabytes We can also apply security settings and configure alerts that will be received on an email inbox
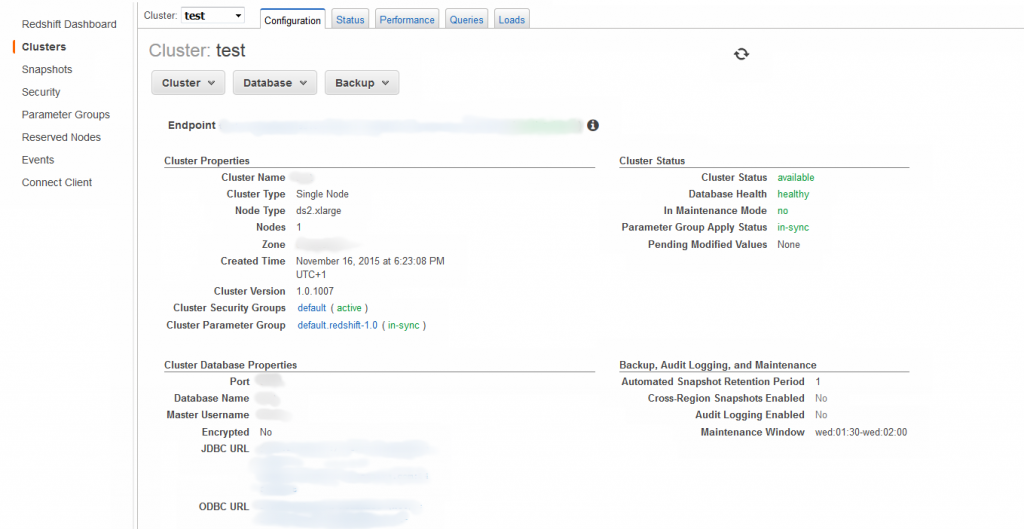
Figure 4 Redshift Cluster configuration and properties
Another good feature of redshift on the management console is the ability to check the query status and monitor the resources used by the database such as disk and cpu usage, query time, etc as seen on the following figure:
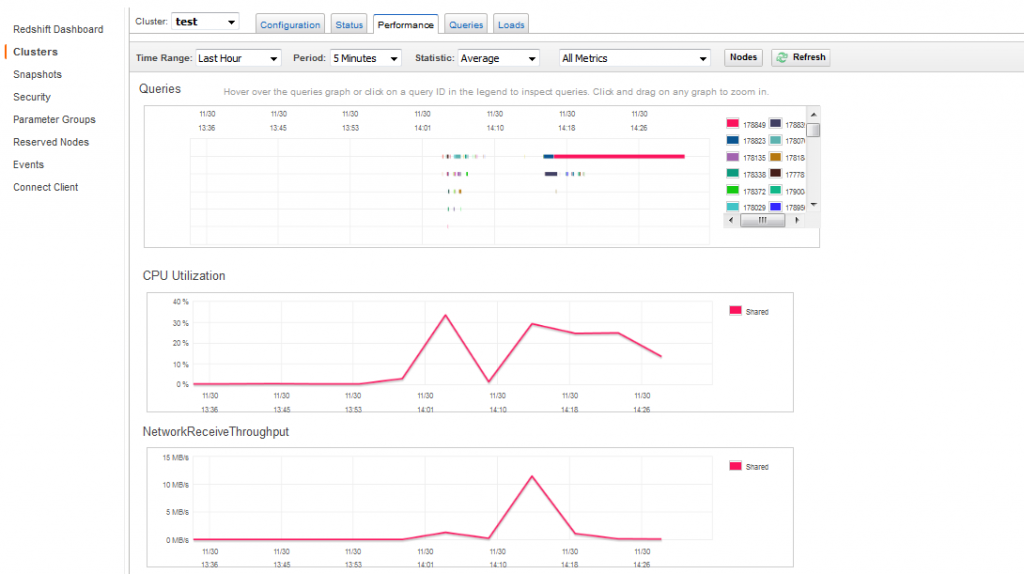
Figure 5 Redshift reports
Conclusion
AWS provides a set of on demand services that can be used to create any kind of IT system.
Regarding the benefits of using it to configure a BI system, it provides scalable on high performance services to create a data warehouse on redshift, host BI tools in EC2 instances with easy maintenance and security configuration, as well as fast data transfers using S3, these services working together are a great option to consider for saving time and money on our BI system infrastructure and configuration.
Contact us if you are thinking in have your data warehouse in AWS.