28 Nov 2024 Streamlining Spark Transformations in Cloudera with A Lightweight Python-Based Framework
The ability to transform and analyse data efficiently is crucial for gaining insights that drive business decisions, and for organisations dealing with large-scale data pipelines, ensuring a smooth, auditable, and yet manageable ETL process is of paramount importance. One of the best data platforms we’ve worked with is Cloudera Data Platform (CDP) which offers an extensive suite of open-source services to build reliable ETL pipelines.
In a recent project with Cloudera for a customer, we developed a framework called DLPROC to streamline Spark jobs in CDP. DLPROC is a lightweight but powerful solution designed to simplify Spark-based data transformations, offering strong auditing capabilities and seamless integration with cloud environments.
In this blog post we’ll walk you through deploying DLPROC to transform data across different layers of a data lake using Spark SQL, allowing for the creation of curated data whilst keeping the framework straightforward, scalable, and auditable. What’s more, DLPROC is versatile enough to be used in both private and public cloud environments.
Why Another ETL Framework?
First, it’s important to clarify that DLPROC is not intended to compete with heavyweight ETL frameworks like Cloudera’s own Cloudera Data Engineering Data Services (CDE) or other industry-grade ETL solutions. There are various approaches an organisation can take to implement Spark ETLs within CDP, but we’ve often seen customers begin with small, custom Spark ETL implementations that quickly become fragmented and inefficient as new use cases arise.
While an obvious solution is to use CDE, some organisations face constraints, such as hardware limitations, that prevent them from adopting CDE or other comprehensive ETL solutions. DLPROC was developed to fill this gap, offering an accessible framework for Spark ETLs, free from the complexity of full-scale ETL platforms yet capable of supporting efficient data transformations.
Let’s explore the key advantages of DLPROC when compared to scattered, in-house Spark framework implementations:
- Consolidated Implementations: DLPROC replaces fragmented solutions by offering a unified platform for executing Spark jobs, providing centralised auditing and monitoring for seamless management.
- Simplified Data Transformation: With DLPROC, data transformations can be carried out through simple, sequential Spark SQL queries, making the process more efficient and significantly easier to debug and maintain.
- Enhanced Operational Visibility: Control tables and audit logs are stored in a metadata database, giving operations teams easy access to monitor and manage ETL processes from a central location.
- Lightweight and Flexible Framework: DLPROC is a lightweight, Python-based framework that is quick to deploy and easy to manage in both private and public cloud environments, particularly valuable when data services aren’t available.
Understanding Where DLPROC Fits In
To fully grasp the functionality of DLPROC and its role within the data transformation landscape, let’s explore a practical use case in the telecom sector, the objective being to conduct a network connectivity analysis. This involves processing data from various sources and transforming it into a consolidated, aggregated table within the gold layer.
For context, here’s is a visual representation of the data flow in our use case, highlighting where DLPROC fits in:
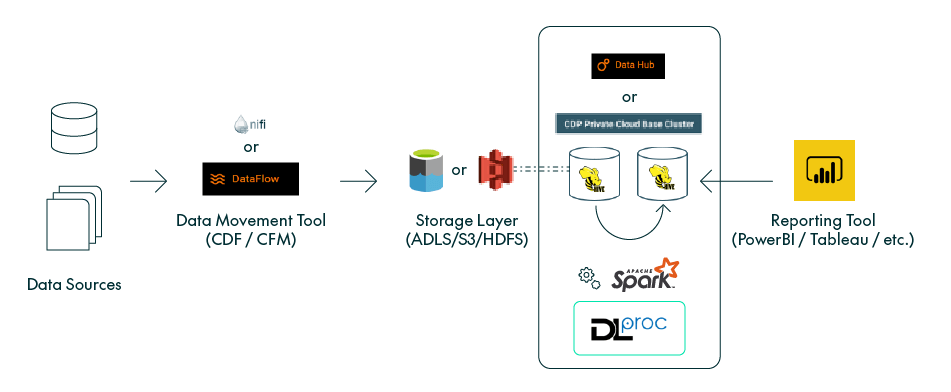
Figure 1: Architecture
Let’s run through the above scenario in detail. For our demonstration use case, and the data lake setup in general, we are implementing a fully private CDP Public Cloud environment with Cloudera Data Flow (CDF) Data Service enabled on Azure. However, as shown above, DLPROC is versatile and can also be utilised on-premises or in other cloud environments, such as AWS.
In the initial phase of this use case, data from various sources, including an Oracle database and SFTP servers, is ingested into the data lake’s silver layer using CDF.
Below you can see the CDF Deployments dashboard, showing the CDF jobs pulling data from these sources. For further insights into building data transfer jobs with CDF, you can explore our dedicated blog post here.
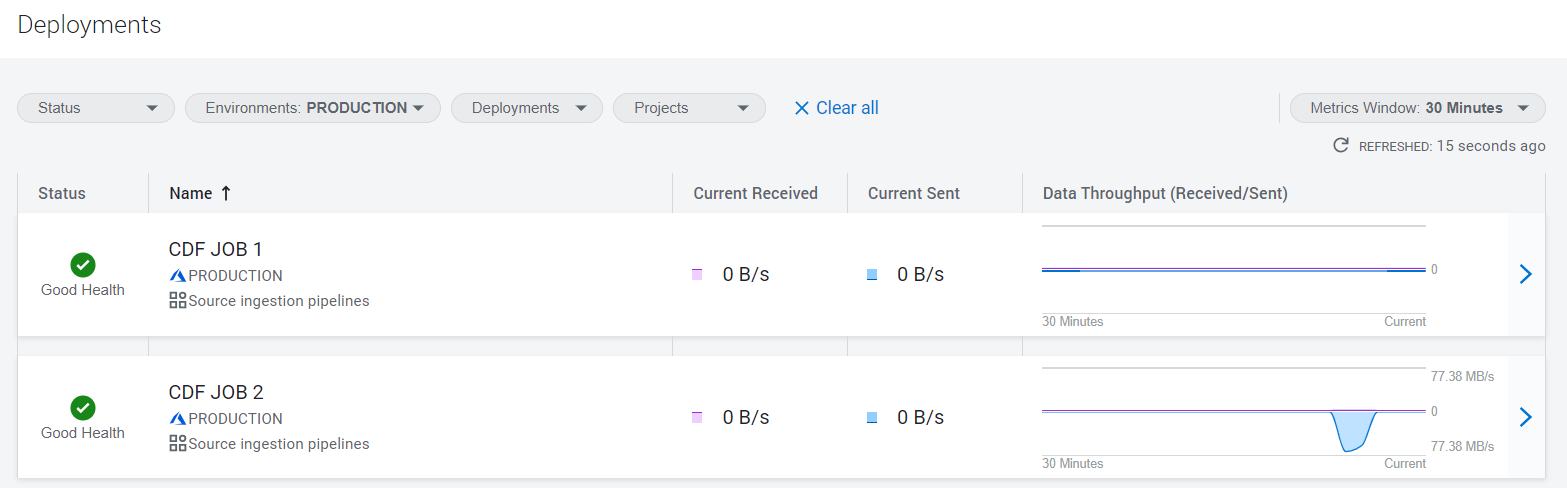
Figure 2: CDF Jobs
Deploying DLPROC
Deploying DLPROC is a one-time process that can be carried out either during the initial setup of the data lake or afterwards. Deployment is not complicated and requires no external packages or dependencies, as the framework is entirely Python-based.
Deployment involves three simple steps:
- Create the required directory structure in the cloud (ADLS/S3) or in local storage (HDFS), in line with the customer’s environment:/dlproc/logs – stores logs of the Spark execution/dlproc/property – stores property file for the use-case with Spark-SQLs/dlproc/scripts – stores any scripts / shell files required for the use-case
- Place the necessary framework-specific files within the DLPROC directory.
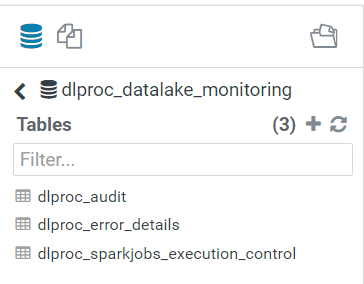
- Create a metadata database named dlproc_datalake_monitoring to house the following tables: dlproc_audit, dlproc_error_details and dlproc_Spark_execution_control.

Figure 3: – Metadata Database
Implementing Spark ETL with DLPROC
Now let’s explore the four simple steps to integrate Spark ETL into any use case with DLPROC!
Step 1: Prepare the Property File
The first step is to create a property file containing all the necessary Spark SQL queries for the transformation, arranged sequentially. Each step must have a unique identifier, and the final target query step should be explicitly marked.
Here’s a redacted version of what the property file will look like:
STEP_1_SQLQUERYSPARK-SQL QUERY 1
STEP_1_TEMPTABLE
Query1_Result_TempName
STEP_2_SQLQUERY
SPARK-SQL QUERY 2
STEP_2_TEMPTABLE
Query2_Result_TempName
STEP_3_SQLQUERY
SPARK-SQL QUERY 3
STEP_3_TEMPTABLE
Query3_Result_TempName
STEP_4_TGTQUERY
INESRT_QUERY 4
STEP_4_NEXTSTEP
END
The property file is structured using specific keywords to define each transformation step. Here are the essential sections:
STEP_X_SQLQUERY: This keyword marks the start of an SQL query to be executed. The X represents the sequence number of the step, ensuring the proper order of execution.
STEP_X_TEMPTABLE: This defines the name of a temporary table where the results of the corresponding SQL query will be stored. This table can then be referenced in subsequent queries.
STEP_X_TGTQUERY: This identifies the final target query in the sequence, which typically inserts or updates data in a designated table in the gold layer.
END: This keyword indicates the end of the sequence of steps in the property file.
The property file structure facilitates the organisation and sequencing of SQL queries, making it simple to manage and update ETL processes without complex coding. By defining the ETL logic within a property file, you can easily make adjustments to queries, table names, and execution steps, offering greater flexibility and adaptability to changing data processing needs.
Step 2: Place the Property File
The property file should then be placed within the appropriate directory structure set up during the DLPROC deployment in the storage layer. This step ensures that the file is accessible to the DLPROC framework during execution.
Step 3: Update the Spark Jobs Execution Control Table
Next, an entry is made in the dlproc_Sparkjobs_execution_control table which is part of the DLPROC control framework. This entry will manage the job execution based on the Oozie schedule. The table contains crucial information such as the flow name, start and end times, and the status of the last run.
Here’s a sample SQL statement:
INSERT INTO dlproc_monitoring.dlproc_Sparkjobs_execution_control VALUES ('gold_network_connectivity_analysis', '2024-03-04 00:00:00', '2024-03-11 00:00:00', NOW(), 'FAILED');
This entry will be updated after each run by the framework, ensuring that the job is ready for the next scheduled execution.
Step 4: Create and Schedule the Oozie Workflow
In the Oozie workflow editor, start by creating a new workflow based on an existing template that includes an SH action. This action is designed to trigger the DLPROC job by executing the relevant shell script within the DLPROC framework. The only parameter to be modified is the ‘argument‘, which specifies the name of the property file associated with the use case.
Next, save the workflow with a descriptive name to facilitate identification. The workflow is then scheduled using a crontab entry that matches the desired execution time. Ensure that the time zone is adjusted to the local time, if necessary.
This seamlessly integrates the Spark job into the DLPROC framework, enabling scheduled job executions along with built-in auditing and error-handling mechanisms. The transformation logic is applied to the silver layer tables, with the results being written into the gold layer based on a predefined schedule.
Key Features of DLPROC
Plugging multiple Spark-SQL ETLs
DLPROC simplifies integrating Spark-SQL-based ETL workflows by following a straightforward four-step process, enabling seamless scheduling, auditing, and monitoring of ETLs within the framework.
Error Logging
The framework includes a robust error-logging feature that captures and records issues encountered during the ETL process, ensuring a detailed audit trail. Spark logs are conveniently stored in a designated directory within the storage layer, enabling easy access for support teams.

Figure 4: Spark Logs
The dlproc_audit logs vital information such as the flow name, step, error message, and Spark application ID, ensuring traceability and simplifying debugging. It also ensures that every major action in the ETL process, from executing Spark SQL queries to inserting data into target tables, is logged with a status indicator and timestamp, providing a comprehensive overview of the workflow.
Below is a sample audit log message clearly indicating an error:

Figure 5: Audit Log Entry
Having an SQL table that audits and logs all Spark errors makes it easy to create dashboards for support and monitoring teams. It also reduces the effort needed to sift through Spark logs manually to identify root causes.
Support for Multiple Metadata Databases
DLPROC also supports hosting the metadata database in PostgreSQL, offering flexibility for organisations with specific preferences for metadata storage. For instance, customers uncomfortable hosting audit and configuration tables within the data lake (e.g., in Hive or Kudu) can now easily use PostgreSQL as an alternative.
Conclusion
In conclusion, DLPROC is a robust and adaptable framework designed to streamline Spark ETL processes in modern data environments, not only simplifying the complexity of data operations but also providing the reliability and control needed to manage, monitor, and optimise ETL workflows efficiently.
With its comprehensive error logging and detailed step-by-step tracking, DLPROC ensures that every aspect of the data transformation journey is transparent and traceable, significantly reducing the time and effort required for troubleshooting. Its flexibility in supporting multiple databases, such as PostgreSQL, Kudu or Hive further enhances its versatility.
These capabilities make DLPROC an ideal, free, and lightweight alternative for organisations navigating diverse technological ecosystems. It particularly benefits those relying on scattered in-house solutions or unwilling to invest in more complex ETL frameworks for Spark, such as Cloudera Data Engineering.
If you would like further information about this solution and whether it can meet your specific needs, don’t hesitate to contact us – we’ll be happy to help!
