
21 Oct 2021 Serverless Near Real-time Data Ingestion in BigQuery
Here at ClearPeaks we have been using Google Cloud Platform (GCP) in our customers’ projects for a while now, and a few months ago we published a blog article about a solution we had implemented for one of our customers in which we built a data warehouse on GCP with BigQuery. In that scenario, data was loaded weekly from a network share on our customer’s premises to GCP by a Python tool running on an on-prem VM. Every week the data was first loaded to Cloud Storage, then external tables were created in BigQuery pointing to the new data in Cloud Storage; lastly the data was loaded to the final partitioned tables in BigQuery from the external tables in an insert statement that also added a clustering column and some columns to monitor the loading procedure.
In this article, we will be describing another GCP data platform solution in a similar scenario that, while also leveraging Big Query, takes a different approach regarding how data is ingested compared to what we saw in our previous GCP blog. The most distinctive characteristics of the solution we are describing here are that it is fully serverless in that it uses only GCP services that are fully managed, and that it is capable of ingesting data into BigQuery in near real time.
Solution Overview
In the scenario described in this article, an upstream application dumps data periodically into an S3 bucket. There are multiple folders in S3, and each folder contains CSVs with a common schema, and a new CSV is added every few hours.
Essentially, we want to load each folder in S3 into a table in BigQuery, and we need to load the new data landing in S3 into BigQuery as soon as possible. The loading procedure needs to make some minor in-row transformations – a few columns are added based on others, including a clustering column and columns to monitor the loading procedure. Moreover, the BigQuery tables are all partitioned by a date field. This combination of clustering and partitioning yields the best performance in queries.
We have designed and implemented a full serverless ingestion solution based on the one presented in this Google blog, but extended to be more robust. The solution consists of the following Google Cloud services: Google Cloud Storage, Google Cloud Transfer Service, Google BigQuery, Google Firestore, Google Cloud Functions, Google Pub/Sub, Google Cloud Scheduler and SendGrid Email API, the latter being a marketplace service. To avoid ending up with a lengthy article, we will not present all the services involved, so if you need more information about the services used please check the Google documentation.
What we will do now is to describe briefly how we have used each of the services in our solution before going into deeper tech details later:
- Cloud Storage: There are a number of buckets used for various reasons:
- “Lake” bucket for the data files landing from S3; this bucket is split into folders like the one in S3.
- Bucket for the configuration files.
- Bucket to store the outcome of the periodic checks.
- Bucket to store the deployed Google Cloud Functions.
- Auxiliary buckets used internally during Google Cloud Function executions.
- Transfer Service: Different jobs, one for each folder, to bring data from the AWS S3 bucket to Google Cloud Storage.
- BigQuery: The final tables are in BigQuery; data needs to be loaded into these tables as soon as possible. Users will connect to BigQuery and query/extract data as they need, but instead of connecting directly to the tables with the data, they will connect via read-only views (which are actually in different GCP projects).
- Firestore: We use this NoSQL document store to track which files are loaded.
- Cloud Function: All the compute required by our ingestion solution is provided by Cloud Functions. There are two functions:
- Streaming: used to stream data from Cloud Storage to Big Query.
- Checking: used to validate the status of the last couple of months of data.
- Pub/Sub: The serverless GCP messaging broker is used to:
- Re-trigger ingestion of files.
- Trigger a periodic checking procedure.
- Cloud Scheduler: A periodic job to send a message to a Pub/Sub topic to trigger the checking procedure.
- SendGrid Email API: We use this marketplace service to send emails with the results of the periodic checking procedure.
Technical Details
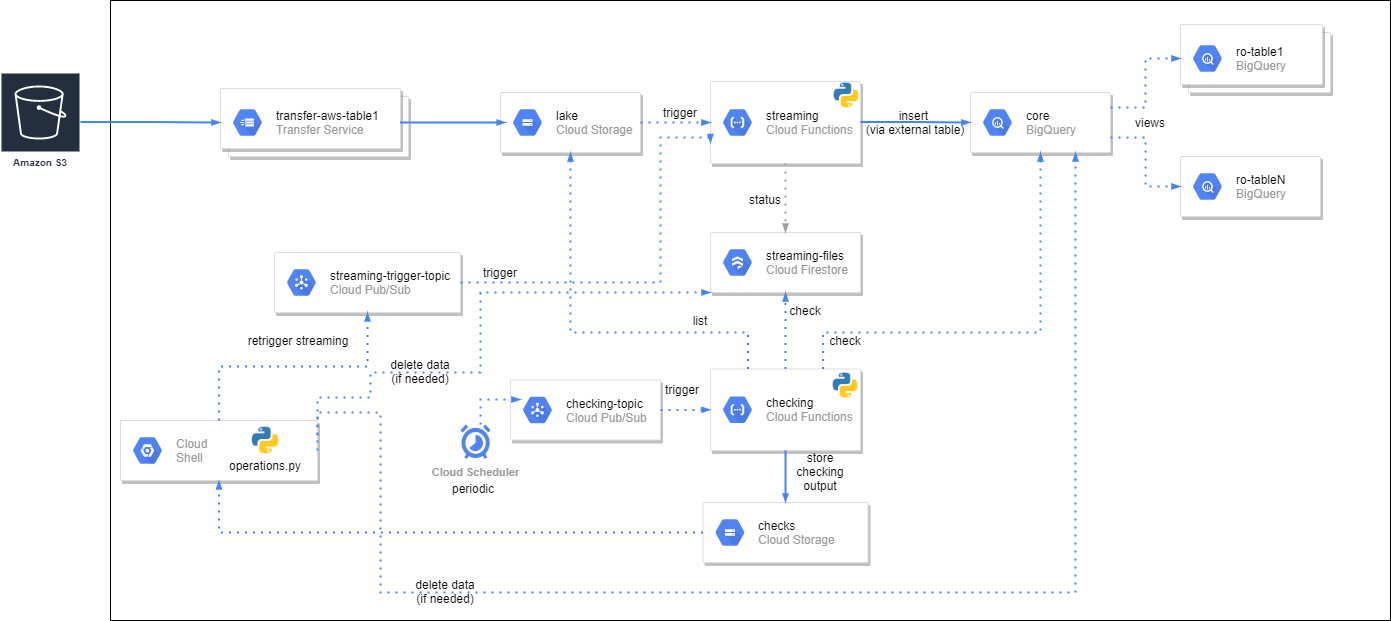
Figure 2 above depicts the diagram and flow of the various services and the actions involved in our GCP serverless ingestion solution. Various Transfer Service jobs are created to transfer data from the S3 bucket to a Cloud Storage (CS) bucket. The transfer service jobs are scheduled to run periodically (every couple of hours), and each run only transfers the files that have been added recently and that do not already exist in the destination (our S3 files are immutable; they cannot be modified). We have one job per folder in S3 to gain better control over when the data of each folder is transferred.
A Cloud Function called streaming is created that will be triggered every time a file is created in CS. This streaming Cloud Function is implemented in Python and performs the following steps:
- Check if the file is already ingested or if there is already a Function instance ingesting this file. A Google Cloud Storage trigger, while in principle this should not happen, can yield more than one Function Execution (see here for more information), so we have added a mechanism that, using Firestore, ensures each file is added only once.
- If the file is not already ingested the Function instance:
- Downloads the file locally (locally to the Function instance workspace).
- Gets the number of lines in the file and its header.
- Creates an external table pointing to the file in CS.
- Inserts the data into the corresponding final BigQuery table. The insert statement does the required in-row transformation, e. adds the clustering field and the monitoring fields.
- Deletes the external table in BigQuery and the local file.
- The ingestion status is logged into Firestore. In Firestore, we also register the time spent on each of the steps, as well as other metadata such as the number of rows in the file.
A second Cloud Function called checking runs periodically and checks, for the current and previous month and for all the tables, that all files in Cloud Storage are also in BigQuery. A checking execution outputs, in Cloud Storage, a number of CSV files with the results of the check. In some cases, the checking function also carries out some minor fixes. More details on this later.
We have also created a script called operations.py that can be executed using Cloud Shell and that, given a CSV with links to CS files (which is what the checking function outputs), can:
- Retrigger the streaming function (ingest data from CS to BigQuery) for a bunch of files. This also calls the streaming function, but in a second deployment that is triggered using Pub/Sub instead of CS triggers; essentially the Python code writes one message in Pub/Sub, for each file that needs to be ingested, with the location of the file.
- Delete the related BigQuery data for the files. This mode must be operated with extreme care since deletion queries can be expensive.
- Delete the related Firestore entries for the files.
Using operations.py can help us to deal with the outcome of the checking function. Below we can see a table that explains the various files that are output by the checking execution as well as the recommended action (DATE is the date when the checking function was run; NUM will be the number of lines of each file):
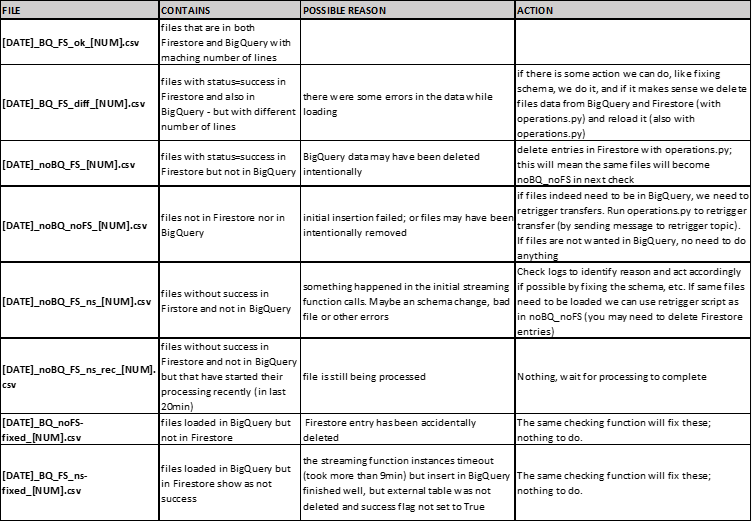
Note the final type of file in the above table: it will list files that are loaded in BigQuery but that appear as unsuccessful in Firestore. As you have seen above, the ingestion of a file itself is done by a run of a cloud function called streaming. An important thing to know about functions is that, while they are great, they time out after 9 minutes – which can be problematic in some cases.
In our case, most of the run time of a streaming function is spent on the insert statement, so a streaming function run may time out before the insert statement has completed. Luckily, BigQuery jobs are async anyway, so what the Python code actually does is submit the insert and wait for it to finish. If the function times out, only the wait is killed but not the insert, though the steps after the insert will not be executed – these steps basically delete the external table and update Firestore.
As mentioned in the table above, when executed, the checking function will fix these cases – when it detects that a file is in BigQuery but appears unsuccessful in Firestore, it will fix the Firestore entry, and also delete the external table. In any case, please note that the files that we receive are relatively small (less than 1GB) so on average a streaming function run takes around 5 minutes, so we do not often see this timeout situation (but we are ready for it).
Conclusion
In this article, we have presented a full serverless approach to ingest data into BigQuery in near real time. In our case, the input files are in AWS S3 and are brought to Cloud Storage using Google Transfer Service. Once a new file lands in Cloud Storage, it is loaded into BigQuery within a few minutes so users can query the data as soon as possible. The solution is quite generic and can be reused for other cases with minor modifications.
Here at ClearPeaks we are experts on building and operating data platforms in the main public clouds, including not only GCP but also AWS, Azure and Oracle Cloud. If you require expert brains and experienced hands for your cloud project, do not hesitate to contact us – we will be delighted to help you. Clouds are fun, and we love flying in them!
