
16 Jul 2018 ODI 11g Repository metadata: Data Linage
In a previous article – ODI 11g Repository metadata: Tips and tricks – we discussed how ODI 11g metadata can be accessed and used to get all sort of detailed information about ODI ETL project components.
Although the queries described in the article are quite basic and mainly focus on single objects/components, the same logic can be combined to get more complex and powerful queries allowing a full overview of the project.
The goal of this article is to describe in detail an example of a query that gives the full data lineage picture of all the ODI interfaces satisfying a specified set of filtering conditions.
For instance, with this query (and slightly modifying when needed) we can:
- check which tables are populated by a given source,
- analyze the sources of a given table column at the end of the ETL,
- look for particular mapping expressions across all interfaces (this is especially useful when looking for hardcoded values),
So, essentially, we obtain a broader overview of the data flow.
In big ETL projects, that have many sources and data streams, it is difficult to get this general perspective through the ODI navigation panel, so by using these queries the team can have a better understanding of the ETL solution with just few clicks. Furthermore, throwing the output of the queries to a graph plotting software/script can result in really interesting, nice looking and quite useful graphics!
WARNING! As stated in the first article, the scripts below query the ODI repository database. You need to take all necessary precautions, and must only replicate it at your own risk after having a full understanding of the logic involved.
1. Data Lineage Query
Let’s just begin with the previously mentioned query and discuss some of its parts. This query is at the lowest level possible and describes the Sources and Target, and Mappings between the Columns for each Interface. Removing some of these query columns would give a more general and simple overview, like the relation between Interfaces, Sources and Target tables without the Columns level.
select distinct
-- FOLDERS : more levels can be included, if needed (update the join conditions accordingly)
PROJECT.PROJECT_NAME PROJECT,
FOLDER_LVL1.FOLDER_NAME LVL1_FOLDER,
FOLDER_LVL2.FOLDER_NAME LVL2_FOLDER,
--INTERFACE
I.POP_NAME INTERFACE,
case when I.WSTAGE = 'E' then 'N' else 'Y' end TEMPORARY_INTERFACE, -- WSTAGE can be: E - Existing target or N,W - Temporary target
-- SOURCE
SRC_TMP.POP_NAME SOURCE_TMP, -- temporary interface as the source
SRC_MOD.MOD_NAME SOURCE_MODEL,
SRC_TAB.TABLE_NAME SOURCE_TABLE,
SRC_TAB.RES_NAME SOURCE_TABLE_RES_NAME,
SRC_COL.COL_NAME SOURCE_COLUMN,
SRC_COL.SOURCE_DT || '(' || SRC_COL.LONGC || case when SRC_COL.SCALEC is not null then ',' || SRC_COL.SCALEC else '' end || ')' SOURCE_COLUMN_DATATYPE,
-- TARGET
TGT_MOD.MOD_NAME TARGET_MODEL,
case when I.WSTAGE = 'E' then TGT_TAB.TABLE_NAME || '(' || TGT_TAB.RES_NAME || ')' else I.TABLE_NAME end TARGET_TABLE,
case when I.WSTAGE = 'E' then TGT_TAB.RES_NAME else null end TARGET_TABLE_RES_NAME,
case when I.WSTAGE = 'E' then TGT_COL.COL_NAME else TGT_POP_COL.COL_NAME end TARGET_COLUMN,
case
when I.WSTAGE = 'E' then TGT_COL.SOURCE_DT || '(' || TGT_COL.LONGC || case when TGT_COL.SCALEC is not null then ',' || TGT_COL.SCALEC else '' end || ')'
else TGT_POP_COL.SOURCE_DT || '(' || TGT_POP_COL.LONGC || case when TGT_POP_COL.SCALEC is not null then ',' || TGT_POP_COL.SCALEC else '' end || ')'
end TARGET_COLUMN_DATATYPE,
case when TGT_POP_COL.IND_KEY_UPD = 1 then 'Y' else null end PRIMARY_KEY,
-- MAPPING VALUE
MAP_VAL_FULL.STRING_ELT FULL_ELT_STRING
from SNP_PROJECT PROJECT
left outer join SNP_FOLDER FOLDER_LVL1 on FOLDER_LVL1.I_PROJECT = PROJECT.I_PROJECT -- FIRST FOLDER LEVEL
left outer join SNP_FOLDER FOLDER_LVL2 on FOLDER_LVL2.PAR_I_FOLDER = FOLDER_LVL1.I_FOLDER -- SECOND FOLDER LEVEL
left outer join SNP_POP I on I.I_FOLDER = FOLDER_LVL2.I_FOLDER -- INTERFACES IN THE 2nd LEVEL FOLDER
left outer join SNP_POP_COL TGT_POP_COL on TGT_POP_COL.I_POP = I.I_POP -- TARGET COLUMNS OF THE INTERFACES
left outer join SNP_COL TGT_COL on TGT_COL.I_COL = TGT_POP_COL.I_COL -- TARGET COLUMNS DETAILS
left outer join SNP_TABLE TGT_TAB on TGT_TAB.I_TABLE = TGT_COL.I_TABLE -- TARGET TABLE DETAILS
left outer join SNP_MODEL TGT_MOD on TGT_MOD.I_MOD = TGT_TAB.I_MOD -- TARGET TABLE MODEL
left outer join SNP_POP_MAPPING MAP on MAP.I_POP_COL = TGT_POP_COL.I_POP_COL
left outer join SNP_TXT_CROSSR MAP_VAL on MAP_VAL.I_TXT = MAP.I_TXT_MAP and MAP_VAL.OBJECT_TYPE in ('C', 'P', 'V')
left outer join SNP_COL SRC_COL on SRC_COL.I_COL = MAP_VAL.I_COL -- SOURCE COLUMN DETAILS
left outer join SNP_TABLE SRC_TAB on SRC_TAB.I_TABLE = SRC_COL.I_TABLE -- SOURCE TABLE DETAILS
left outer join SNP_MODEL SRC_MOD on SRC_MOD.I_MOD = SRC_TAB.I_MOD -- SOURCE TABLE MODEL
left outer join SNP_DATA_SET DATA_SET on I.I_POP = DATA_SET.I_POP
left outer join SNP_SOURCE_TAB SOURCE_TAB on DATA_SET.I_DATA_SET = SOURCE_TAB.I_DATA_SET
left outer join SNP_POP SRC_TMP on SOURCE_TAB.I_POP_SUB = SRC_TMP.I_POP -- TEMPORARY SOURCE
left outer join (
select I_TXT, STRING_POS, STRING_ELT, ROW_NUMBER() over (partition by I_TXT order by length(STRING_ELT) desc) POS
from SNP_TXT_CROSSR
) MAP_VAL_FULL on MAP_VAL_FULL.I_TXT = MAP_VAL.I_TXT and MAP_VAL_FULL.POS = 1
where 1=1 -- FILTERS
and PROJECT.PROJECT_NAME = 'BI Apps Project' -- by Project name
and FOLDER_LVL1.FOLDER_NAME like 'Custom_%' -- by 1st Level Folder name
and FOLDER_LVL2.FOLDER_NAME = 'SDE_ORA_%' -- by 2nd Level Folder name
and I.POP_NAME not like 'Copy%' -- by Interface name
and SRC_TAB.TABLE_NAME like '%WC_LHA%PS%' -- by Source Table name
and SRC_COL.COL_NAME like '%EMPLOYEE_ID' -- by Source Column name
and TGT_TAB.TABLE_NAME like '%_DS' -- by Target Table name
and TGT_COL.COL_NAME like '%EMPLOYEE_ID' -- by Target Column name
and MAP_VAL_FULL.STRING_ELT like '%COALESCE(%' -- by Mapping Value
order by
PROJECT.PROJECT_NAME
, FOLDER_LVL1.FOLDER_NAME
, FOLDER_LVL2.FOLDER_NAME
, I.POP_NAME
, SRC_COL.COL_NAME
, case when I.WSTAGE = 'E' then TGT_COL.COL_NAME else TGT_POP_COL.COL_NAME end
;
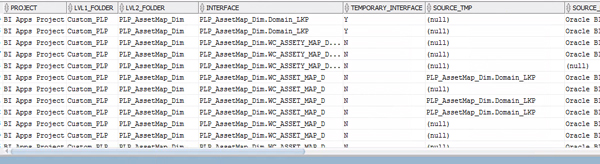
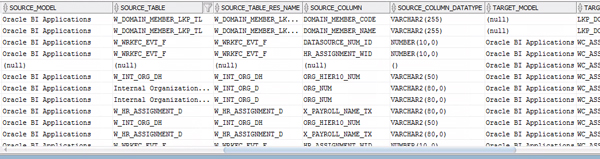
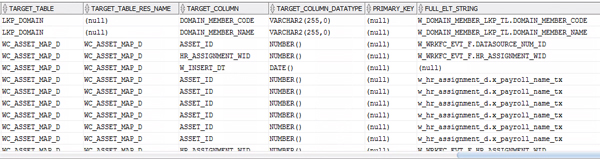
In the SELECT clause we have five well defined sections: Folders structure, Interface, Source details, Target details and Mapping value. Many of the selected columns were already described in the first article, and more details could be added if needed (timestamps, users, etc).
Depending on whether the Interface is Temporary or not, the Target details (table, columns) are extracted from different tables, so the following condition accounts for that:
case when I.WSTAGE = 'E' then … else … end
The repository tables FROM where the metadata is pulled and the joins between them follow a similar grouping as in the SELECT statement. Most of these were also discussed in the previous article. Only some extra bridge tables are needed to connect Mappings, Source and Target metadata, like SNP_POP_MAPPING, SNP_TXT_CROSSR, SNP_DATA_SET DATA_SET, SNP_SOURCE_TAB.
Lastly, the filtering WHERE statement is quite self-explanatory. All the Interfaces, Tables and Columns names can be filtered immediately, or more complex logics can be implemented, such as combining conditions on the Source/Target with AND/OR operators. This is also particularly useful to filter the Mapping Values to look for particular functions used, concatenations of strings, or hardcoded IDs:
and MAP_VAL_FULL.STRING_ELT like '%COALESCE(%'
Let’s discuss some of these use cases in the next section.
2. Use cases
Sometimes we might be interested in knowing where a given table is used and what its data is populating. If we clean the SELECT statement and comment out every row referencing Columns metadata:
select distinct
...
-- SOURCE
--SRC_TMP.POP_NAME SOURCE_TMP, -- temporary interface as the source
...
--SRC_COL.COL_NAME SOURCE_COLUMN,
--SRC_COL.SOURCE_DT || '(' || SRC_COL.LONGC || case when SRC_COL.SCALEC is not null then ',' || SRC_COL.SCALEC else '' end || ')' SOURCE_COLUMN_DATATYPE,
-- TARGET
...
--case when I.WSTAGE = 'E' then TGT_COL.COL_NAME else TGT_POP_COL.COL_NAME end TARGET_COLUMN,
--case
-- when I.WSTAGE = 'E' then TGT_COL.SOURCE_DT || '(' || TGT_COL.LONGC || case when TGT_COL.SCALEC is not null then ',' || TGT_COL.SCALEC else '' end || ')'
-- else TGT_POP_COL.SOURCE_DT || '(' || TGT_POP_COL.LONGC || case when TGT_POP_COL.SCALEC is not null then ',' || TGT_POP_COL.SCALEC else '' end || ')'
--end TARGET_COLUMN_DATATYPE,
--case when TGT_POP_COL.IND_KEY_UPD = 1 then 'Y' else null end PRIMARY_KEY,
-- MAPPING VALUE
--MAP_VAL_FULL.STRING_ELT FULL_ELT_STRING
...
and we then apply a filter on the Source Table name:
and SRC_TAB.TABLE_NAME like 'WC_ASSET_D'
We´ll obtain a report of all the Interfaces having this table as a source and the Target Tables populated.

On the other hand, it can be useful to backtrack the data flow of a given column to analyze how it is being populated and which logics are applied. If, for instance, we consider the column REASON in WC_HR_TRANSITION_F table, we can apply the following conditions:
and TGT_TAB.TABLE_NAME = 'WC_HR_TRANSITION_F' and TGT_COL.COL_NAME = 'REASON'
That gives us the Temporary Interface that is populating this REASON column (Cust_SIL_HRTransitionFact.SQ_WC_HR_TRANSITION_FACT). If we use this information to include another filtering condition with an OR clause, and we keep on iterating and expanding the conditions, we get the full picture of the data flow:
…
and ( 1<>1
or ( 1=1
and TGT_TAB.TABLE_NAME = 'WC_HR_TRANSITION_F'
and TGT_COL.COL_NAME = 'REASON'
)
or ( 1=1
and I.POP_NAME = 'Cust_SIL_HRTransitionFact.SQ_WC_HR_TRANSITION_FACT'
and (case when I.WSTAGE = 'E' then TGT_COL.COL_NAME else TGT_POP_COL.COL_NAME end) like '%REASON%'
)
or ( 1=1
and TGT_TAB.TABLE_NAME = 'WC_HR_TRANSITION_FS'
and TGT_COL.COL_NAME like '%REASON%'
)
)
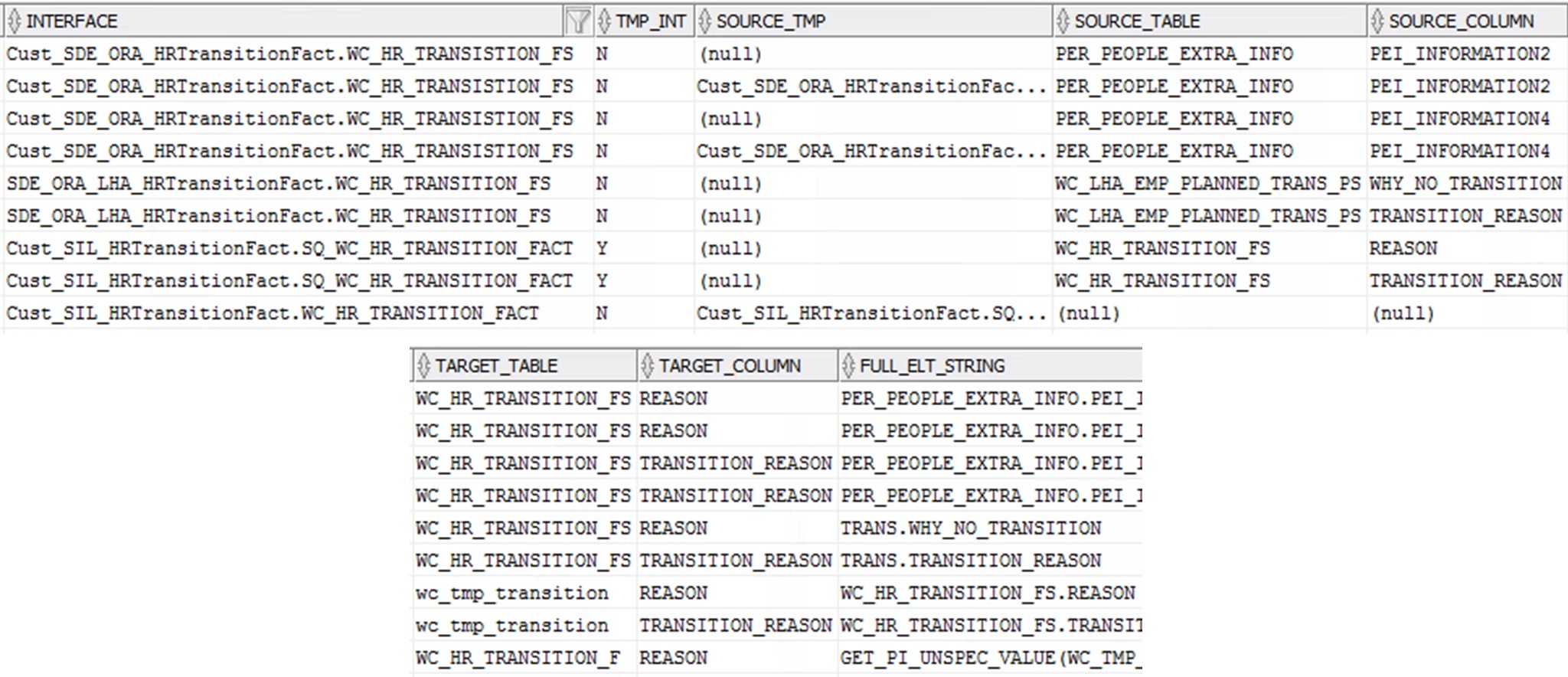
Last but not least, let’s say we want to check which Interfaces and Target Column mappings use a given expression. We can take, for example, the symbol ~ , which is sometimes used for concatenating values on a string column. We can add the following condition to our initial query to retrieve all the mappings where this is used:
and MAP_VAL_FULL.STRING_ELT like '%~%'

Conclusions
The queries discussed above can be useful for discovering and analyzing an ODI ETL implementation, but it is much better if we know the basic folder structure of the project and the naming convention followed for the Interfaces and Tables. This helps us to build the queries and understand the output.
In any case, even if the results of the queries might not be fully descriptive and ODI has to be used anyway for further references, this becomes a great starting point for having a general perspective of the data flow and to know where to look for more details.
All in all, this kind of ODI repository queries can be really convenient when analyzing a big ETL project. When mastered, the team can investigate ETL logics by just modifying a few lines of code, instead of launching ODI Studio and navigating through each of the objects, which would take much more time.
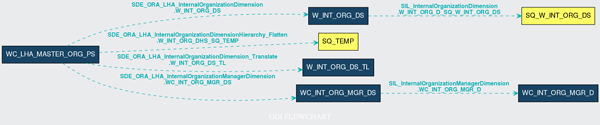
Furthermore, with some technical knowledge and time, the output of these queries can be used to generate some nice looking graphs (and even interactive ones!), like the one below, which was rendered with the Python graph visualization library Graphviz. These plots give a clear picture of the data streams and help to visually identify all the components which, in the end, can be used for both analysis and documentation of an ETL project.
Read our previous article on ODI Repository metadata or check out our blog for more interesting BI articles!