
28 Jun 2023 Microsoft Fabric: First Contact – Evolution or Revolution?
Everybody’s talking about Microsoft Fabric nowadays, but what exactly is it? How does it differ from the data platforms that we already know?
Simply put, Microsoft is presenting a unified data platform with a single data lake and a common data format, Delta Parquet, transitioning from the use of protective formats to completely open ones.
The traditional data warehouse architecture is being replaced by the lakehouse architectural pattern. This is key to understanding Fabric, but a bit of history is also necessary to fully grasp the present.
The History of the Lakehouse and Delta Format
A few years ago, data lakes appeared as an alternative to databases to help organisations to scale and to store their massive datasets whilst managing costs. Data lakes are flexible and especially well-suited to dynamic advanced analytics, machine learning, and artificial intelligence (AI).
Data lakes originally consisted of files in cloud-based storage systems in CSV, JSON, or Parquet format, offering advantages such as:
- No risk of vendor lock-in thanks to the use of open file formats.
- Reduced costs, as storing files in the cloud with open formats is usually cheaper than using proprietary data services.
- Scalability, as data lakes can handle volumes of data that a database might struggle with.
However, this architecture also presents some downsides, like:
- It doesn’t support transactions, so it can easily be corrupted.
- It doesn’t support indexes, so queries can be slow.
- Some common data operations are tricky to do, like updating or merging data and deleting columns or rows from files.
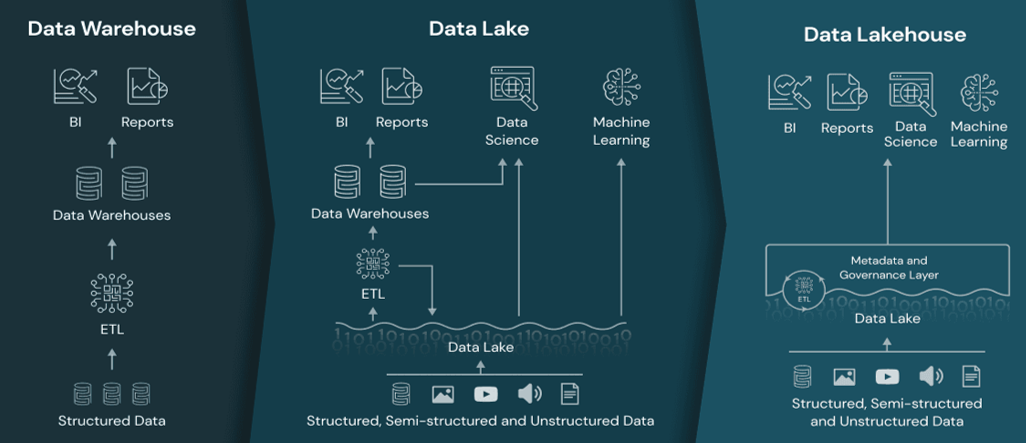
Figure 1: Data warehouse evolution.
(Source: https://www.databricks.com/glossary/data-lakehouse )
The data lakehouse architecture emerged as a solution to overcome the limitations of traditional data warehousing and to address the challenges associated with data lakes. In a data lakehouse, the data lake and data warehouse are combined, eliminating the need for separate storage systems.
The introduction of the Delta format, based on Apache Parquet, played a significant role in enabling data warehouse-like functionality directly on the data lake, incorporating a transaction log that enables users to access features commonly found in databases, whilst still benefiting from the scalability of a data lake.
A Delta Lake offers several impressive features, including ACID transactions, scalable metadata, time travel, unified batch/streaming, schema evolution/enforcement, audit history, DML operations and more, as well as being an open-source project.
What is Microsoft Fabric?
We are used to seeing overly complex data architecture diagrams with different ETL tools to ingest and transform the data, different compute engines (Spark, Databricks, SQL, etc.), in real time, with integrated AI and so on – the challenge is often to connect the different pieces of these puzzles and the people that interact with them.
With Microsoft Fabric, rather than provisioning and managing different computes for each workload, the full data lifecycle is covered, including ingestion and integration, engineering, real-time analysis, warehousing, data science, business intelligence and data monitoring/alerting:
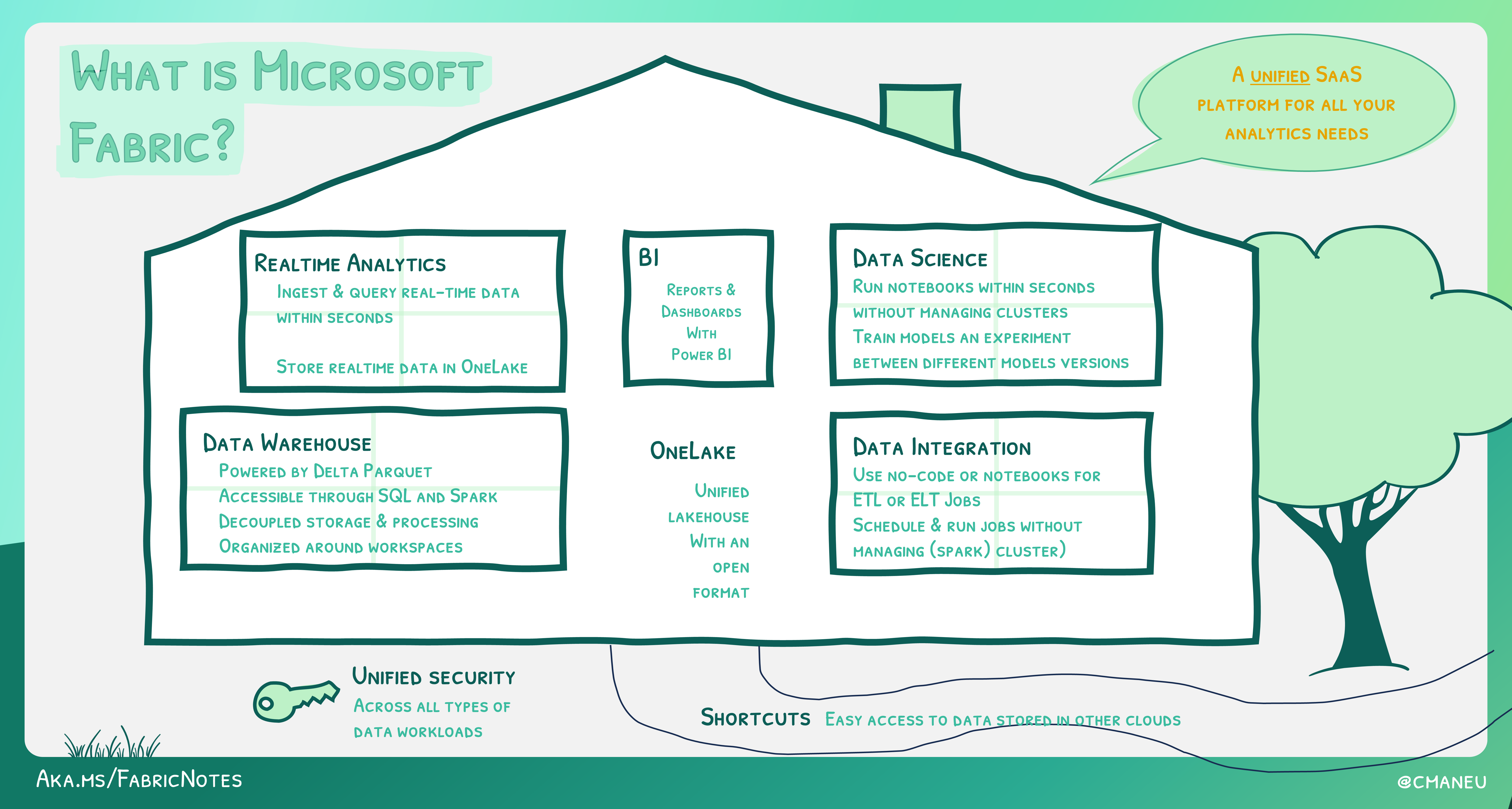
Figure 2: Microsoft Fabric as a unified SaaS.
(Source: https://microsoft.github.io/fabricnotes/images/notes/06-what-is-fabric.png)
At first glance, Fabric seems like an evolution of Synapse, in that the analytics tools and services are the same – but now these workloads work together to offer a unified analytics experience.
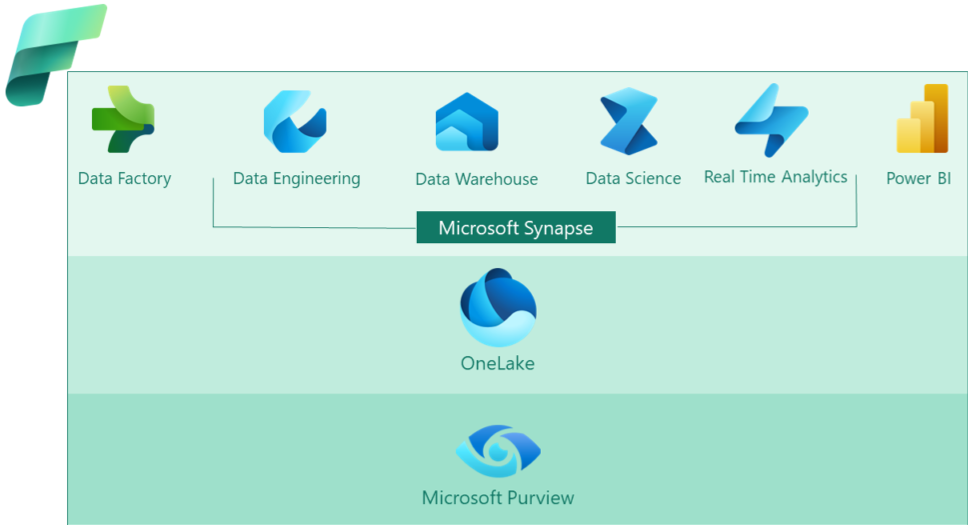
Figure 3: Microsoft Fabric components.
Components of Microsoft Fabric
As we can see in the previous image, Microsoft Fabric has six core components that were already existing. Let’s take a look at them:
- Data Factory: Enables the creation of data transformations, data pipelines, and orchestration.
- Synapse Data Engineering: Based on the same technology as the Spark pools in Azure Synapse Analytics, this feature allows code-centric data engineering and includes notebook capabilities.
- Synapse Data Science: This component facilitates the training, deployment, and management of machine learning models. It leverages Spark technology and incorporates elements from Azure Machine Learning, SQL Server Machine Learning Services, and the open-source MLflow project.
- Synapse Data Warehousing: An evolution of the Azure SQL Data Warehouse, but now converged to lakehouse technology. There is an optimised SQL engine that provides data warehouse-like performance whilst operating directly on a data lake instead of a traditional database.
- Synapse Real-Time Analytics: This combines Azure Event Hubs, Azure Stream Analytics and Azure Data Explorer, and it supports operational technology (OT) analytics, enabling the analysis of real-time streaming data from various sources like IoT devices, telemetry systems, logs, and more.
- Power BI: No need to explain what Power BI is! Microsoft will add AI with Copilot, a feature that will generate DAX for creating queries and calculations in Power BI.
OneLake
This is a crucial element in streamlining the data architecture: all workloads interact with the data stored in OneLake, which is in Delta Parquet format, regardless of its original format. Because we store everything in a single data lake, there’s no need to configure access to different storage accounts or to use different services to access the data, and a unified security model is integrated into it.
Another benefit of this unique centralised access is that diverse users, such as data analysts, BI developers, data engineers and data scientists can seamlessly interact with the data. Whether you work with Spark notebooks using Python, Scala, R, or SQL, or if you are a BI SQL developer, or a data analyst working with Power BI, all contributors are working on the same data lake. It’s like having a universal language in your organisation, enabling efficient communication and collaboration!
To allow the connection from Power BI to OneLake, Microsoft has released a new storage mode called Direct Lake, which works like a live connection to Analysis Services. You don’t need to import data to Power BI and the performance is great.
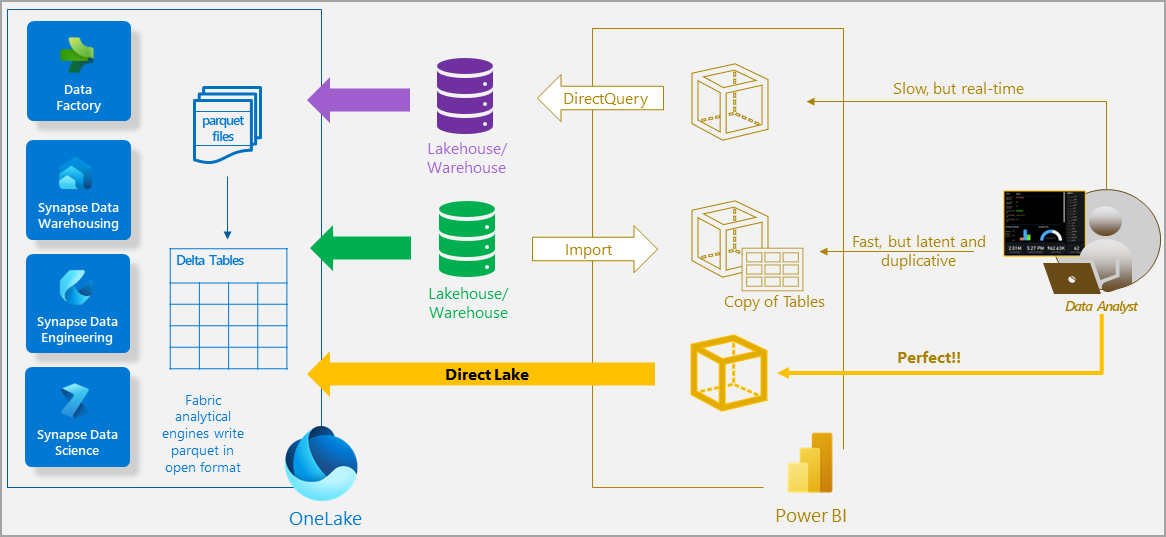
Figure 4: Power BI storage modes.
(Source: https://learn.microsoft.com/en-us/power-bi/enterprise/directlake-overview)
We believe that this feature is a must for the future success of Fabric. A very common scenario would be working with a Power BI dataset in import mode and exceeding the 1Gb limit: the customer would have to go for a dedicated premium capacity or spend twice as much on Power BI Premium Per User licenses. We will need to test performance and calculate costs to decide which scenarios really benefit from this storage mode.
Conclusion
Fabric marks the dawn of a new era in data platforms, and it promises lots of advantages with its unified SaaS approach for all your analytics needs.
Don’t forget that at the time of writing Fabric is in preview and there will be changes and new features before it goes to general availability, so we still need to analyse the final costs and limitations of its different features and workloads. You can definitely look forward to more blog posts on the topic as new developments happen!
Here at ClearPeaks we are busy testing Fabric to gather the expertise needed in order to show our customers how this new product can help them. In the meantime, please don’t hesitate to get in touch with us with any questions you might have about Microsoft BI and analytics services, or to see what we could do for your business!
