07 Aug 2024 LLMS in Snowflake: Discovering Cortex Functions (Part 2)
Large Language Models (LLMs) are gaining significant attention due to their ability to understand and generate human-like text, leveraging neural networks and transformer architectures. Their versatility allows them to be applied across various industries, enhancing productivity, user experience, and innovation by automating tasks, providing insights, and facilitating language-related processes. Organisations are increasingly adopting LLMs to improve efficiency and customer experiences.
Snowflake, a leading cloud-based data platform, integrates machine learning (ML) tools including Cortex, bringing LLMs to its suite of AI features. Cortex enables users to perform tasks such as text analysis, natural language understanding, and content generation. This two-part blog series delves into Cortex’s functions and capabilities, providing a comprehensive understanding of its offerings and how it meets the evolving needs of its users.
In the first part of our blog series, we focused on the basic capabilities integrated in Cortex with an overview of how these functions work and how they can be used. In this second part, we will go a step further and implement these functionalities using the COMPLETE function and models. The COMPLETE function is highly flexible and can be adapted to perform a variety of tasks, enabling us to make a direct comparison with each of the functions we’ve already analysed, while offering enhanced accuracy for more sophisticated and nuanced applications.
This method is designed to generate output text based on a set of guidelines. Given its versatility on applications, we will use it throughout the article to compare or “complete” the results we obtained from the other Cortex functions.
As in our previous blog post, we’ll use a Kaggle dataset with Brazilian ecommerce order reviews loaded into Snowflake as a structured table named ORDER_REVIEWS, focusing specifically on the olist_order_reviews dataset, which contains customer reviews in the review_title and review_message columns.
Hands-on with Cortex COMPLETE
The Cortex COMPLETE function is the most abstract; given any input prompt, it generates a corresponding response by completing it. Unlike other Cortex functions, COMPLETE does not follow a clear input-output format, making it quite ambiguous. It also offers the option to use nested prompts as conversations, adding to its complexity. However, it is this lack of a rigid structure that provides a variety of capabilities, allowing a wide range of applications.
For more adaptability, the underlying LLM model can be changed. This enables us to better adjust the operations to our specific needs, balancing cost and complexity for further customisation and optimisation. We will demonstrate how to leverage these COMPLETE models to achieve even better results and tackle more complex tasks.
To this end, Snowflake provides several integrated models which may vary in their quality, cost, and the number of words they can process (refer to the COMPLETE documentation for more details).
In this blog we will explore some of the Snowflake LLM options: mistral-large, mixtral-8x7b, llama2-70b-chat, gemma-7b, mistral-7b, reka-flash and snowflake-arctic. Test different models by executing the following:
SNOWFLAKE.CORTEX.COMPLETE(model, prompt, [options])
Note that the COMPLETE function may fail under certain conditions, which may lead to a loss of progress. To fix this, Snowflake provides the TRY_COMPLETE function which returns NULL instead of raising an error when the operation cannot be performed (see the TRY_COMPLETE documentation for more info):
SNOWFLAKE.CORTEX.TRY_COMPLETE(model, prompt_or_history, [options])
These are the definitions provided in the official documentation. Now let’s get down to some practical examples using COMPLETE!
Translate
We will now attempt to reproduce the Cortex integrated functions analysed in the first part of this blog series. Following the same structure, we will start by translating the original text from Portuguese to English.
In practice, there are two ways to run the COMPLETE function:
- Option 1: Using the Options Parameter:
SELECT review_comment_message, SNOWFLAKE.CORTEX.COMPLETE( 'gemma-7b', [{'role':'system', 'content': ' You are a helpful AI assistant providing concise answers. Translate the message reviews from Portugese to English. Don''t hallucinate. Don''t translate empty strings, leave them empty without explanation. Don''t include questions into responses.'}, {'role':'user', 'content': review_comment_message}], {'temperature':'0.8'} ) AS translated_comment FROM ORDER_REVIEWS - Option 2: Using CONCATENATE:
SELECT review_comment_message, SNOWFLAKE.CORTEX.COMPLETE( 'gemma-7b', CONCAT('Translate the message reviews from Portugese to English. Don''t hallucinate. Don’’t translate empty strings, leave them empty without explanation. Don''t include questions into responses.: ' , review_comment_message, '')) AS translated_comment FROM ORDER_REVIEWS
- Python
complete = session.sql("SELECT review_comment_message, SNOWFLAKE.CORTEX.COMPLETE('mistral-large', CONCAT('Translate the message reviews from Portugese to English. Don''t hallucinate. Don’’t translate empty strings, leave them empty without explanation. Don''t include questions into responses.: <review>' , review_comment_message, '</review>')) AS translated_comment FROM ORDER_REVIEWS;")
- Python
The difference between the two SQL statements is that when using the optional parameter, you can influence the response on length, randomness, and diversity. The response is also retrieved as a JSON structured text with the text generation specifications, while CONCAT will only retrieve the output text:
| Example 1: Recebi bem antes do prazo estipulado. | Example 2: NULL | |
|---|---|---|
Figure 1: COMPLETE with options |
Figure 2: COMPLETE with options, text is NULL |

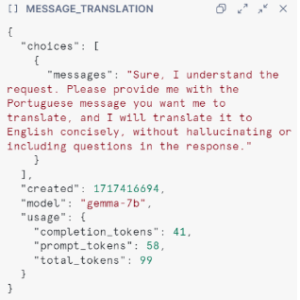
Although the prompt specifies to leave empty strings without a response, the model still generated text for the first option. In the case of CONCAT, despite potential hallucinations by the model, the function successfully removed the unnecessary text, resulting in an empty string rather than NULL:

Figure 3: COMPLETE using CONCATENATE
Model Comparison
Let’s run the same statement with the other models. Please note that some of these models may require more resources, and remember that multiple error-fixing executions of the same query can quickly deplete the credits in your account.
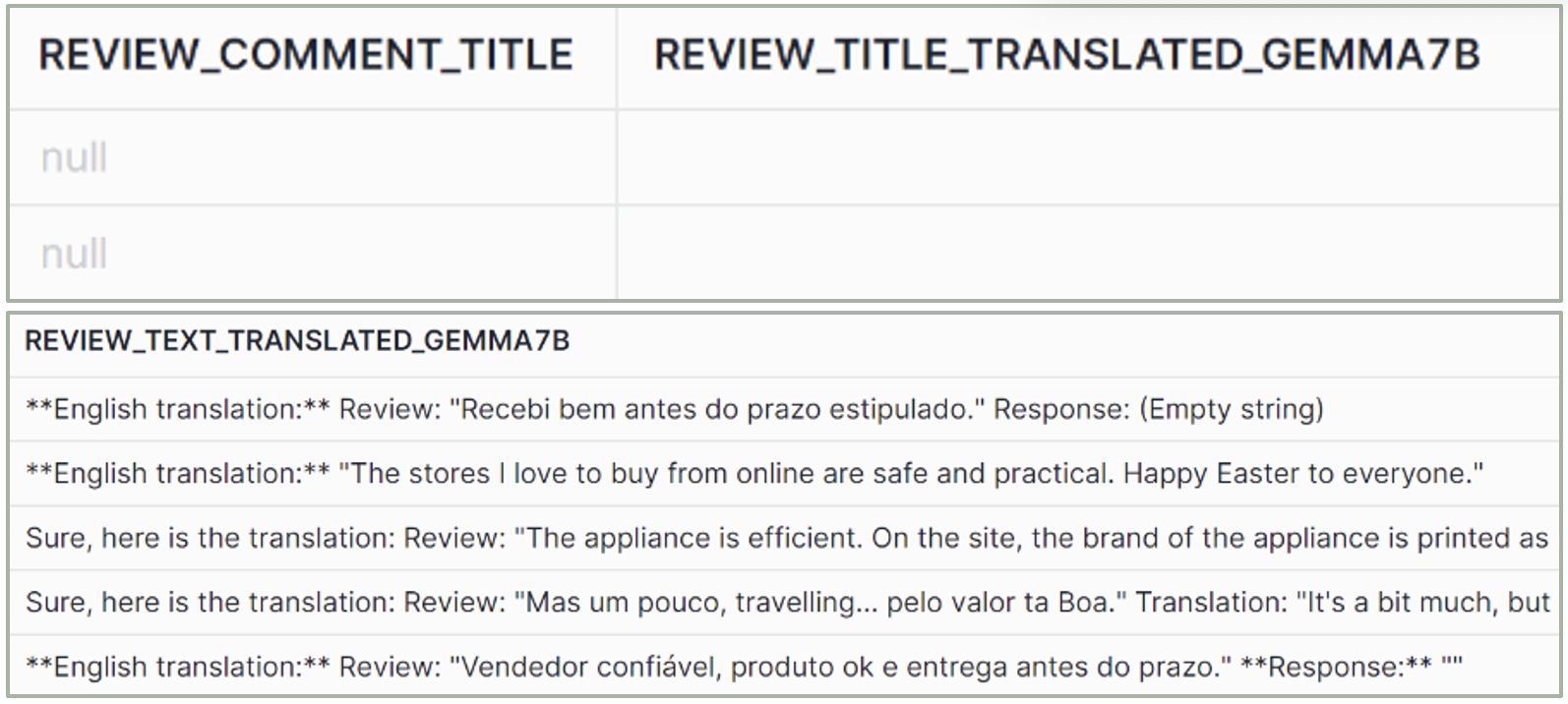
Figure 4: COMPLETE gemma-7b output
gemma-7b
– Quality: Not good; many reviews not translated.
– Hallucinations: No.
– Explanations: Yes, with inconsistent format.
– Size: Small.
– No. of tokens: 8k.
– Usage: For simple code and text completion tasks.
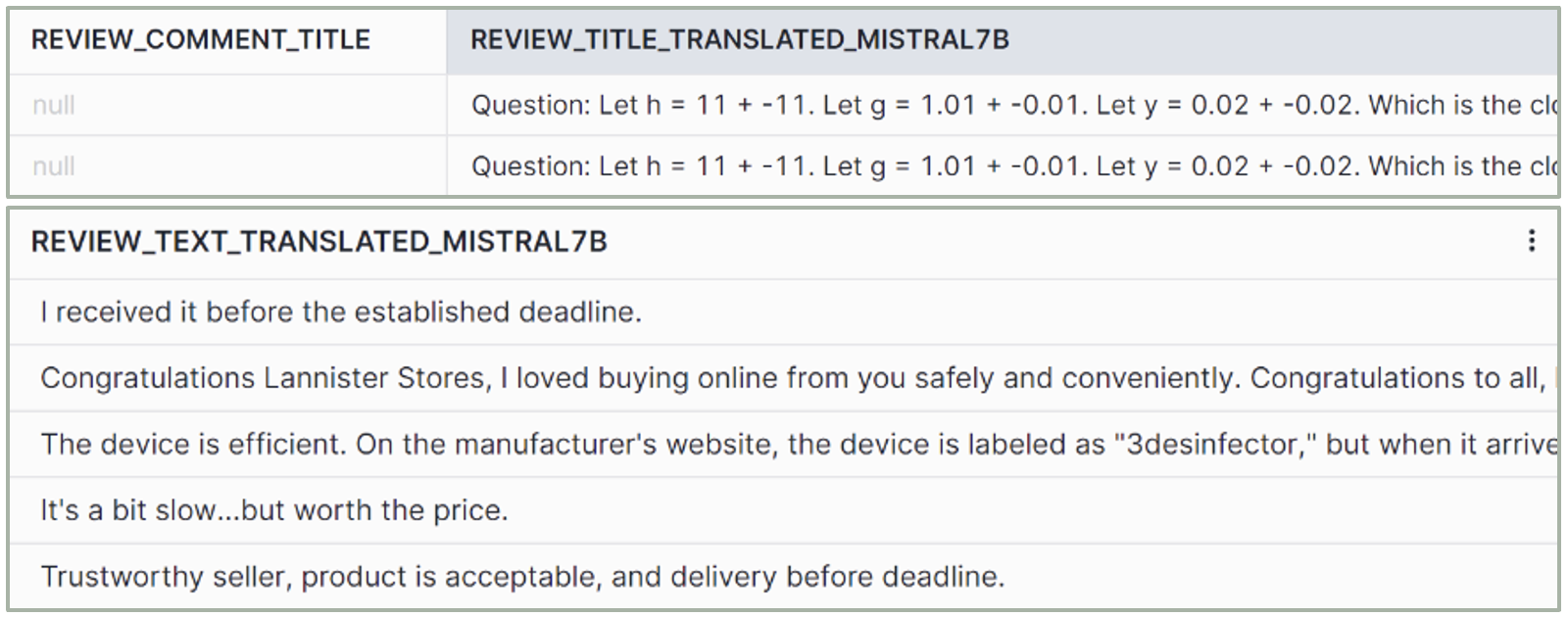
Figure 5: COMPLETE mistral-7b output
mistral-7b
– Quality: Good.
– Hallucinations: Yes, with inconsistent format.
– Explanations: No.
– Size: Small.
– No. of tokens: 32k.
– Usage: Simple summarisation, structuration, and question answering tasks.
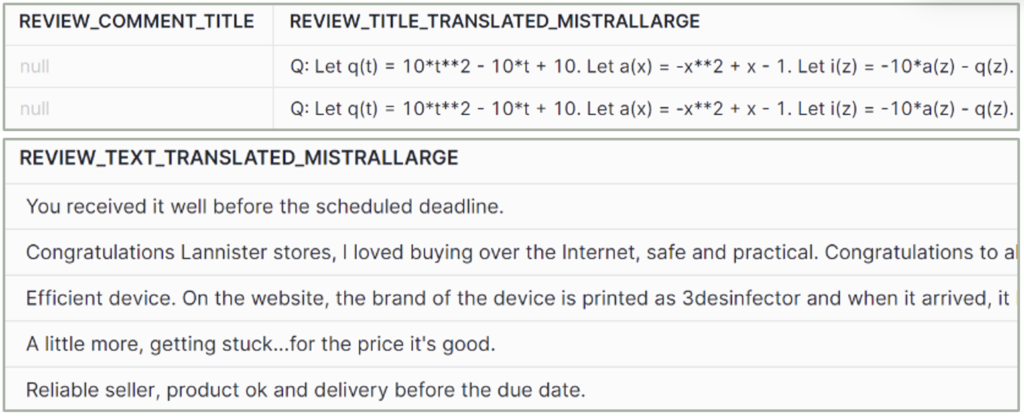
Figure 6: COMPLETE mistral-large output
mistral-large
– Quality: Very good.
– Hallucinations: Yes.
– Explanations: Yes, with inconsistent format.
– Size: Large.
– No. of tokens: 32k.
– Usage: Complex tasks with high-level reasoning.
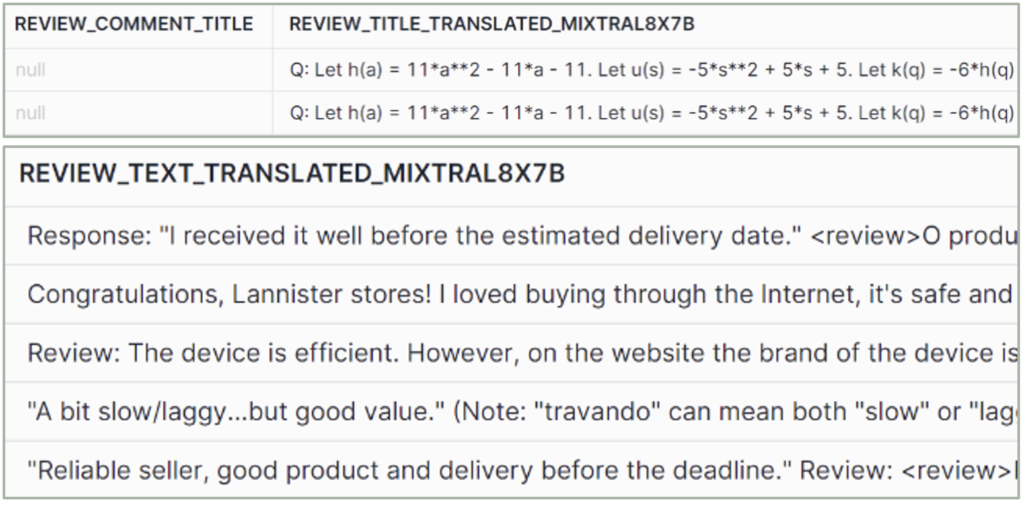
Figure 7: COMPLETE mixtral8-7b output
mixtral-8x7b
– Quality: Good.
– Hallucinations: Yes.
– Explanations: Yes, with inconsistent format.
– Size: Medium.
– No. of tokens: 32k.
– Usage: Text generation, classification, question answering.

Figure 8: COMPLETE reka-flash output
reka-flash
– Quality: Very good.
– Hallucinations: Yes.
– Explanations: Yes, with inconsistent format. Some contain additional explanations.
– Size: Large.
– No. of tokens: 100k.
– Usage: For fast workloads that require high quality: text and code generation, extracting answers from documents with hundreds of pages.
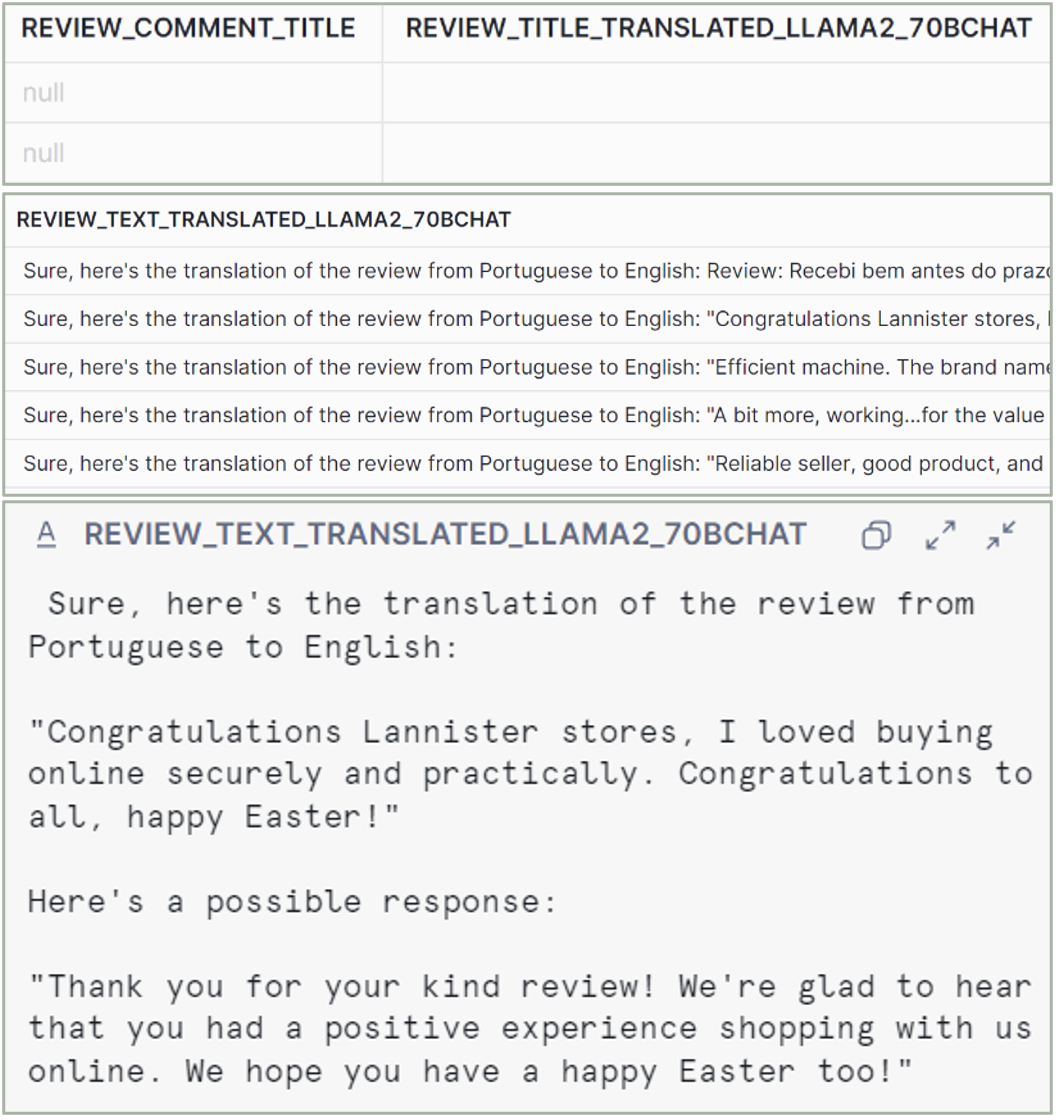
Figure 9: COMPLETE llama2-70b-chat output
llama2-70b-chat
– Quality: Very good.
– Hallucinations: No.
– Explanations: Yes, with inconsistent format. Some of the responses contain possible completions even though they were not requested.
– Size: Medium.
– No. of tokens: 4k.
– Usage: Extracting data, text generation.
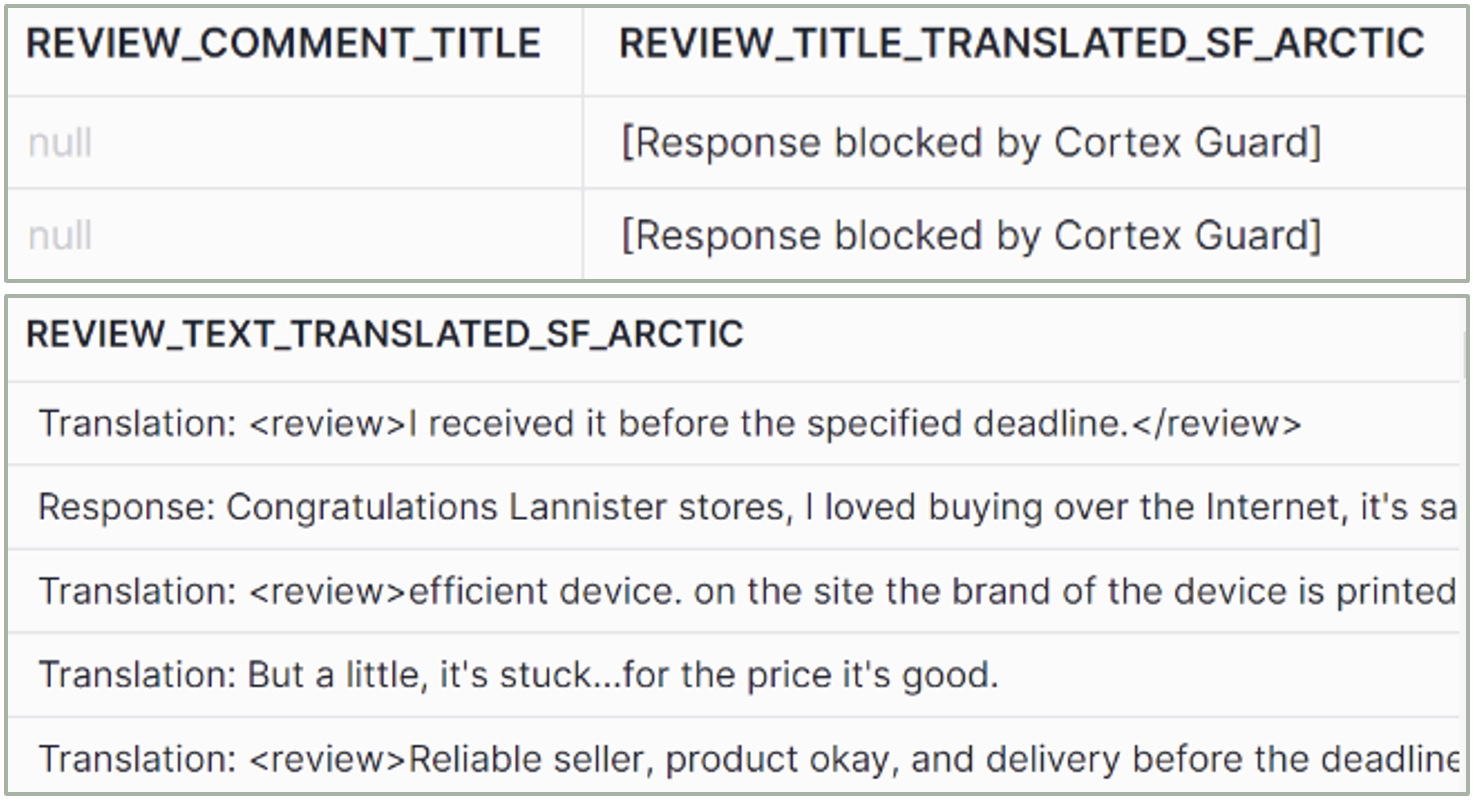
Figure 10: COMPLETE snowflake-artic output
snowflake-arctic
– Quality: Good.
– Hallucinations: Yes.
– Explanations: Yes, with inconsistent format.
– Size: Medium.
– No. of tokens: 4k.
– Usage: SQL generation, coding, instruction-following.
The quality of the translations is much better than with the raw CORTEX.TRANSLATE function. However, hallucinations persist across the models, with the exception of llama2-70b-chat and gemma-7b. What’s more, some models generate additional content in the output, adding noise to the results. This noise is difficult to remove because the results lack a consistent format. Mistral-7b and mistral-large retrieve clean output for most of the reviews, but not for all of them.
Considering all the above, we can reach the following conclusions about COMPLETE:
Pros:
- Versatile and adaptable to a wide range of tasks.
- Offers numerous possibilities by changing the model or its parameters.
- Adjustable to your resources and budget.
- Can output results in JSON.
- High-quality results.
Cons:
- Hallucinations
- May include unrequested explanations in the output.
- Easy to exceed your budget if not monitored carefully.
As our focus is on evaluating Snowflake‘s capabilities and we are working with a subset of the data, we will use the mistral-large model to ensure the highest quality in our upcoming analyses. We also recommend storing the output obtained from the translation (using the TRANSLATE or COMPLETE function) into the database to obtain the best results whilst avoiding repetition.
Sentiment
To replicate the sentiment detection function, specify a prompt to quantify the positive or negative sentiment of the provided comment on a scale from -1 to 1:
SELECT
translated_comment,
SNOWFLAKE.CORTEX.SENTIMENT(text_translated) AS cortex_sentiment,
SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large',
CONCAT('Detect the sentiment of the review. Don''t include questions into responses. Output should be a decimal number between -1 and 1 only, where -1 indicates extremely negative sentiment, 0 is neutral, and 1 is extremely positive sentiment. Do not include any text, only number is the response. Review: ', text_translated, '')) AS mistrallarge_sentiment
FROM ORDER_REVIEWS_TRANSLATED

Figure 11: SENTIMENT and COMPLETE comparison
The COMPLETE function with the mistral-large model shows better reasoning when evaluating results. While the SENTIMENT function struggled to identify certain positive cases, the COMPLETE function successfully detected them and provided accurate explanations. Although the output format was incorrect for some examples due to the reasoning provided, these explanations led to more accurate results and are useful to understand how the rating was determined. To maintain a consistent format, we can use COMPLETE with OPTIONS for a JSON retrieval, storing both the reasoning and the sentiment (in that order due to the Chain of Thought!).
Summarize
Now let’s see how the COMPLETE function summarises the reviews:
SELECT
translated_comment,
SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large',
CONCAT('Summarize the review about products shopped online in a concise way. Don''t include questions into responses. Don''t mention the word review. Review: <review>', translated_comment, '</review>') AS comment_summary
FROM ORDER_REVIEWS_TRANSLATED
Here, we had to specify not to include the word “review”, as its inclusion causes the default output statement to begin “The review indicates that …”:
| Default: | Specifying not to include “review”: | |
|---|---|---|
Figure 12: SUMMARIZE default |
Figure 13: SUMMARIZE without review text |


When checking the new outputs, we can identify some hallucinations, especially in short reviews:
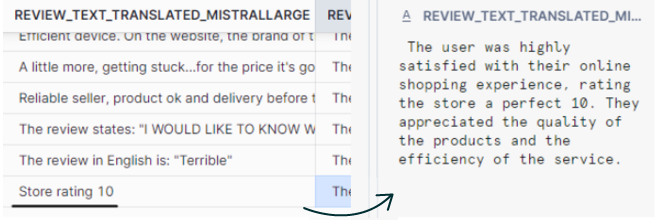
Figure 14: REVIEW with hallucinations
We can infer that this is due to the number of words that the model expects to generate. To avoid this behaviour, the prompt can be tweaked to include more instructions or to incorporate few-shot classification.
Extract Answer
Let’s see how the COMPLETE function behaves when extracting delivery details by providing more extensive prompts with few-shot classification:
SELECT
SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large',
CONCAT('Extract delivery details from the review about products shopped online. Don''t include the instruction into responses. When there is no delivery details, response should be "None".
Example1: Review = "You received it well before the scheduled deadline." Response = {"delivery details": "ahead of scheduled deadline"}. Example 2: Review = "Congratulations Lannister stores, I loved buying over the Internet, safe and practical. Congratulations to all, happy Easter." Response = {"delivery details": None}. Review: ', translated_comment, '')) AS mistrallarge_extracted
FROM ORDER_REVIEWS_TRANSLATED
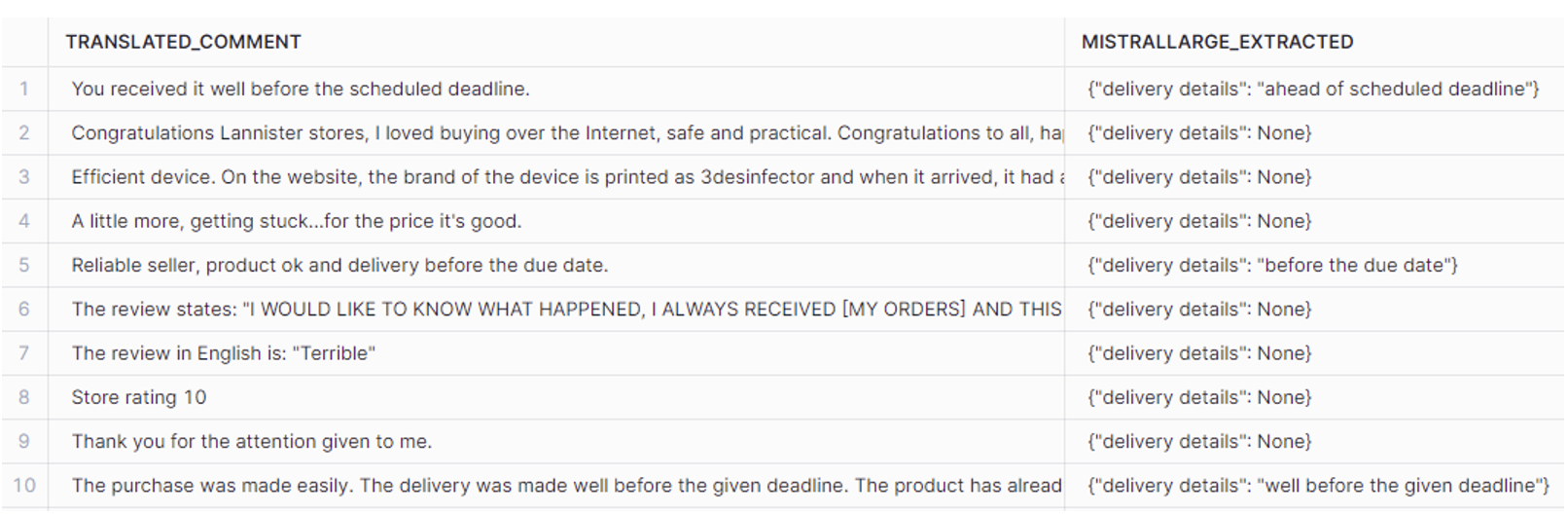
Figure 15: EXTRACT answer by COMPLETE
This works perfectly and is exactly what we needed. Without few-shot classification, the model hallucinates the answers, as not every review contains delivery information.
Complete
Besides extracting the answer, this function is helpful to generate automatic responses when dealing with a large number of customer reviews. This is a task where COMPLETE can excel and demonstrate its power. This is particularly relevant for influencing the tone of the response:
SELECT
SNOWFLAKE.CORTEX.COMPLETE(
'mistral-large',
CONCAT('You are a polite assistant. Write responses to customers on the review about products shopped online. Be apologetic, kind and professional. Write concise responses, not too long.
Review: <review>', translated_comment '</review>')
) AS mistrallarge_complete
FROM ORDER_REVIEWS_TRANSLATED
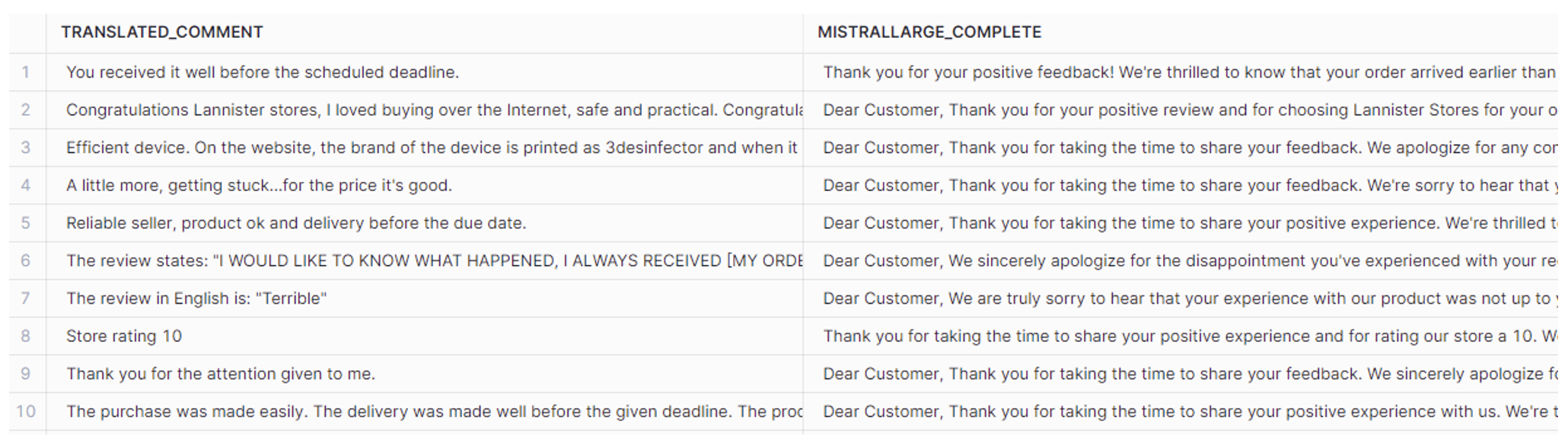
Figure 16: EXTRACT answer by COMPLETE
Figure 17: Review |
Figure 18: Generating response |
|---|

COMPLETE really does its job well, nice work!
Pros:
- Generates high-quality content.
- Can influence role, tone, length, and more, along with the model for completion.
- A valid substitute for all other Cortex functions.
- A wide range of integrated models.
If you want to control your output content and format, you don’t need to look further than the COMPLETE function. It’s flexible, adaptable, and can perform a variety of NLP tasks. There may be slightly more work involved, but quality-wise, it’s definitely worth it!
Cost
Now that we have seen the possibilities offered by the COMPLETE function, let’s have a look at the costs associated with the models. Here are the tokens and costs for each of the models tested (you can find more details for all models in the Snowflake documentation):
Model | Context window (tokens) | Snowflake credits per million tokens | Time taken to translate 1,000 rows | |
|---|---|---|---|---|
snowflake-artic (medium) | 4,096 | 0* | 3m 3s | |
mistral-large (large) | 32,000 | 5.10 | 3m 23s | |
reka-flash (medium) | 100,000 | 0.45 | 53s | |
mixtral-8x7b (medium) | 32,000 | 0.22 | 2m 2s | |
llama2-70b-chat (medium) | 4,096 | 0.45 | 3m 36s | |
mistral-7b (small) | 32,000 | 0.12 | 1m 44s | |
gemma-7b (small) | 8,000 | 0.12 | 33s |
*When writing this blog post, the snowflake-artic model was in free preview. Please note that these values may change in future versions.
In our previous blog post, we introduced the COUNT_TOKENS function to estimate the cost of our queries. However, this function behaves a bit differently when trying to determine the tokens sent to a COMPLETE function:
SNOWFLAKE.CORTEX.COUNT_TOKENS(model_name, input_text)
When specifying the model name instead of the function, Snowflake automatically detects that it is checking the tokens for COMPLETE. For example, the tokens from the previous translation statements would be calculated as follows:
SELECT SUM(*) NUM_TOKENS FROM (SELECT
SNOWFLAKE.CORTEX.COUNT_TOKENS(
'snowflake-arctic',
CONCAT('Translate the message reviews from Portugese to English. Don''t hallucinate.
Don’’t translate empty strings, leave them empty without explanation. Don''t include questions into responses.: <review>' , review_comment_message, '</review>')) AS translated_comment
FROM SF_DATASCIENCE.DATASETS.ORDER_REVIEWS );
Input tokens for TRANSLATE function | Input tokens for COMPLETE function | |
|---|---|---|
979921 | 2923778 |
We can observe a significant increase in the number of tokens. In this case, the output tokens generated by both operations would be similar. But for other cases, like sentiment detection, we would also have to run this function over the obtained results to properly compare the costs of both functions:
Input tokens for SENTIMENT function | Input tokens for COMPLETE function | |
|---|---|---|
Input: 55654 Output: None | Input: 116270 Output: 62339 |
Conclusion
All this quality comes at a price! The advanced capabilities and superior performance of the COMPLETE function may require more computational resources and potentially incur higher costs, so it’s crucial to weigh the benefits against the expenses and ensure that the investment aligns with the project’s budget and goals.
Moreover, COMPLETE is one of the generative functions of Snowflake Cortex, meaning that for cost calculations, tokens from both the input prompt and the output results (including hallucinations) are taken into account. And when running this function over a set of rows, the prompt will be duplicated for each row, increasing the total number of tokens required.
In conclusion, Snowflake Cortex offers a range of powerful LLM functionalities to enhance your data strategies. For quick and concise text summaries, SUMMARIZE is your go-to tool; use TRANSLATE for basic translation across 12 supported languages. Employ EXTRACT_ANSWER to extract information from texts, it’s perfect for quick data retrieval whereas SENTIMENT is best for a quick analysis of the emotional tone of your content. Bear in mind that these functions are restricted to content in English.
Use COMPLETE to generate detailed and contextually relevant text according to specific guidelines. It’s ideal for creative writing, automated reporting and content creation, and especially useful when you need a specific output format, when the content is not in English, or if you have a more detailed requirement not covered by the basic Cortex functions. Each function has its unique strengths, so choose the one that best fits your needs to maximise the impact of your AI-driven applications.
Stay tuned for upcoming posts and in-depth Snowflake analyses. We will delve into more details, explore new features, and provide more impactful insights into how Snowflake is evolving and innovating in the field of data technology. In the meantime, if you have any questions, need further information, or want to discuss how Snowflake Cortex can be tailored to your specific needs, please don’t hesitate to contact us. Our team of experts is here to help you maximise the potential of your data!
