07 Ago 2024 LLMs in Snowflake: Discovering Cortex Functions (Part 1)
Recently, as we all know, LLMs, or Large Language Models, have gained significant traction across many areas. But what exactly is driving this fascination with LLMs, and why are they increasingly becoming a cornerstone of modern AI technology?
LLMs represent a class of advanced AI systems primarily designed to understand and generate human-like text. These models leverage neural networks, particularly transformer architectures, to process and manipulate natural language data.
Thanks to their versatility and effectiveness, LLMs can easily be integrated into a wide range of industries and technologies where they can provide significant advantages like boosting productivity, enhancing the user experience, and offering new possibilities for innovation across various domains. They are powerful tools that can automate repetitive tasks, provide impactful insights, and facilitate complex language-related processes.
Organisations across diverse sectors are starting to recognise the potential of LLMs to drive efficiency, improve the customer experience, and unlock new opportunities for improvement. The accessibility of pre-trained LLMs, along with the availability of open-source frameworks and cloud-based services, has helped businesses leverage this technology.
Many leading platforms recognise the importance of ML in data analysis and decision-making, and are integrating these new technologies into their solutions. For instance, Snowflake, a cloud-based data platform, offers Cortex, a suite of AI features that introduces LLMs into the platform. Cortex enables users to perform a wide range of language-related tasks, including text analysis, natural language understanding, and content generation.
In this two-part series we’ll take a detailed look at Snowflake Cortex, exploring its various functions and capabilities, helping you to understand its unique features and benefits, as well as assessing how Snowflake can continue to grow to address the evolving needs of its user base.
Snowflake Cortex
Snowflake Cortex is an intelligent, fully managed service that seamlessly integrates ML and AI technologies into the Snowflake environment. In essence, Cortex introduces top-tier functionalities while leveraging Snowflake’s robust framework, meaning that all operations benefit from the platform’s core features of security, scalability, and governance.
The infrastructure that supports Snowflake Cortex also drives other advanced features, including innovations such as Document AI for enhanced document processing, Universal Search for streamlined data querying, and Snowflake Copilot for improved user interaction with data environments.
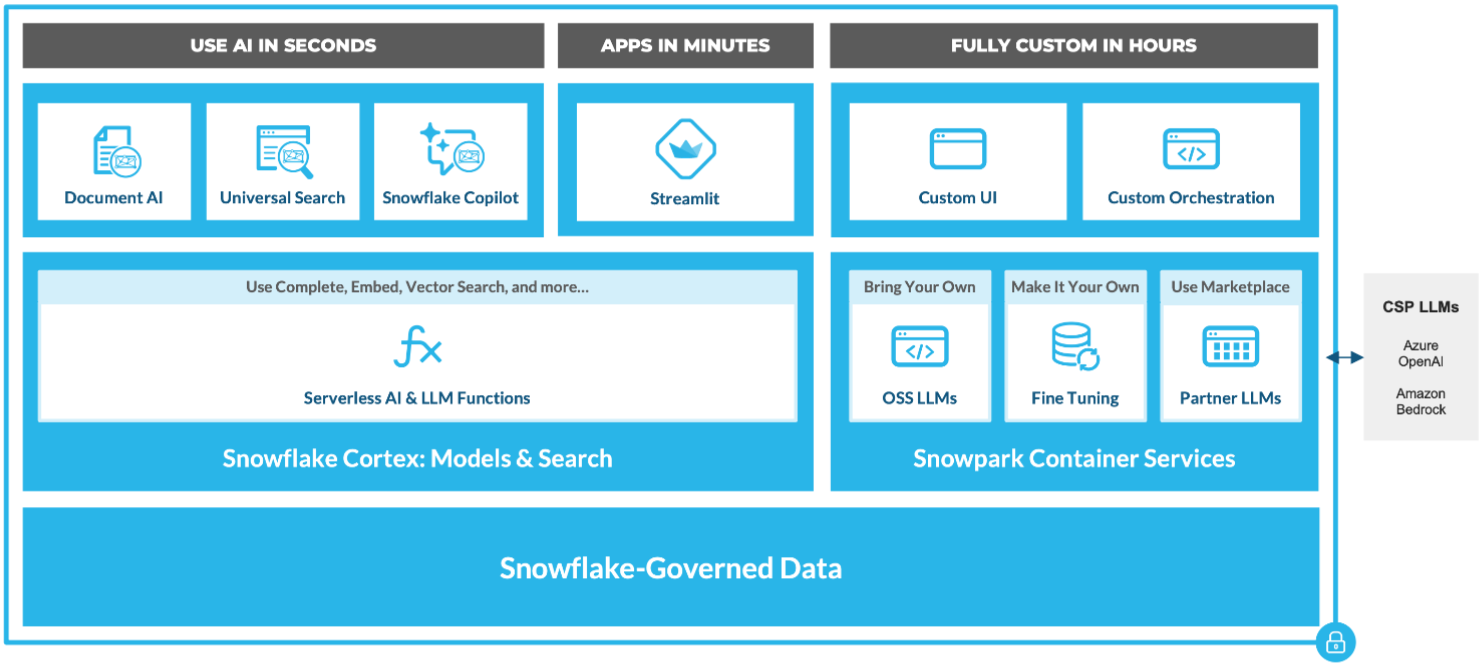
Figure 1: Cortex overview inside Snowflake architecture
As all the models are fully hosted and managed by Snowflake, using them requires no additional setup. Your data stays within Snowflake, giving you the performance, governance and scalability you’d expect. Cortex essentially offers two distinct sets of AI capabilities:
- ML Functions: SQL functions designed to conduct predictive analysis, utilising ML to extract deeper insights from structured data and to enhance analytical operations by emphasising the role of ML in transforming data into actionable intelligence efficiently. (For further reading, refer to our previous ML-related blog posts: Part1 and Part2).
- LLM Functions: These functions are available in both SQL and Python, and use LLMs to provide advanced text handling capabilities like understanding, querying, translating, summarising, and generating.
In this and our next post we’ll explore the LLM functionalities that Snowflake offers through both Cortex and Snowpark, to understand their unique features and assess how Snowflake is expanding its offering to keep up with high market demands.
Cortex LLM functions
Snowflake Cortex provides instant access to industry-leading LLMs trained by researchers at companies like Mistral, Reka, Meta, and Google. What’s more, Snowflake has released its own LLM, Snowflake Arctic, an open-source enterprise-grade model, also available in the popular Hugging Face platform.
Snowflake Cortex features are provided as SQL and Python functions.
- COMPLETE: This function returns a response that completes the given prompt. It accepts either a single prompt or a conversation with multiple prompts and responses.
- EXTRACT_ANSWER: Given a question and unstructured data, this returns the answer if it can be found in the data.
- SENTIMENT: This returns a sentiment score, from -1 to 1, representing the detected positive or negative sentiment of the given text.
- SUMMARIZE: This returns a summary of the given text.
- TRANSLATE: This translates the given text from one supported language to another.
In this first part, we will focus on the basic capabilities integrated in Cortex: Translate, Sentiment Detection, Summarize and Extract Answer, as well as their cost. We will provide an overview of how each of these functions work and how they can be used. In the second part of this series, we will go further and implement these functionalities using Complete prompts which offer more flexibility to generate sophisticated, nuanced outputs.
Hands-on with SQL, Cortex & Snowpark
We’ll use a Kaggle dataset with Brazilian ecommerce order reviews to explore all the functionalities, focusing specifically on the olist_order_reviews dataset, which contains customer reviews in the review_title and review_message columns. We’ll load it into Snowflake as a structured table named ORDER_REVIEWS.
During the analyses, we will utilise both an integrated Snowflake SQL worksheet and a remote Snowpark session using Python (see this guide to set up a Snowpark environment). This approach allows us to provide examples in both languages while evaluating all capabilities. Note that for the Snowpark session we need to reference our dataset at the beginning:
reviews = session.table("ORDER_REVIEWS")
Since the reviews are in Portuguese, we will translate them to English to maximise the use of the LLM. Let’s begin by exploring the first functionality of Cortex:
Translate
This operation uses a Snowflake-managed LLM to evaluate the original_text and translate it using the specified languages. When providing a table column as input, the function will return a new column with the translation of each row (for more detail, refer to the TRANSLATE documentation):
SNOWFLAKE.CORTEX.TRANSLATE(original_text, source_language, target_language)
This is the translation of the review comments:
- SQL:
SELECT
review_comment_title,
SNOWFLAKE.CORTEX.TRANSLATE(review_comment_title, 'pt', 'en') AS translated_title,
review_comment_message,
SNOWFLAKE.CORTEX.TRANSLATE(review_comment_message, 'pt', 'en') AS translated_comment
FROM ORDER_REVIEWS;
- Python:
reviews = reviews.withColumn(
"translated_comment",
Translate(col("review_comment_message"), 'pt', 'en')
)
Note that the snowflake.cortex Python library must be installed before starting.
When checking the output function, we can see hallucinations of empty fields, and we can also see that the translations are too literal; for example, the translation in line 2 is not at all clear:

Figure 2: Cortex Translation
Based on these observations, we can conclude the following:
Pros:
- The function is easy to use.
Cons:
- Hallucinations in generated content.
- Poor quality translation.
- Only 11 languages with limited support.
Since our focus is on evaluating Snowflake’s capabilities and we are working with a subset of the data, we recommend storing the translated output in the database, as the subsequent functionalities are only supported for English.
Sentiment Detection
This function uses a Snowflake-managed model to evaluate sentiment. It returns a floating-point number ranging from -1 to 1 (inclusive), indicating the level of negative or positive sentiment detected, where values around 0 indicate a neutral sentiment (see the SENTIMENT documentation for more details).
- SQL:
SELECT translated_comment, SNOWFLAKE.CORTEX.SENTIMENT(translated_comment) AS comment_sentiment FROM ORDER_REVIEWS_TRANSLATED
- Python:
reviews = reviews.withColumn(
"comment_sentiment",
Sentiment(col("translated_comment"))
)
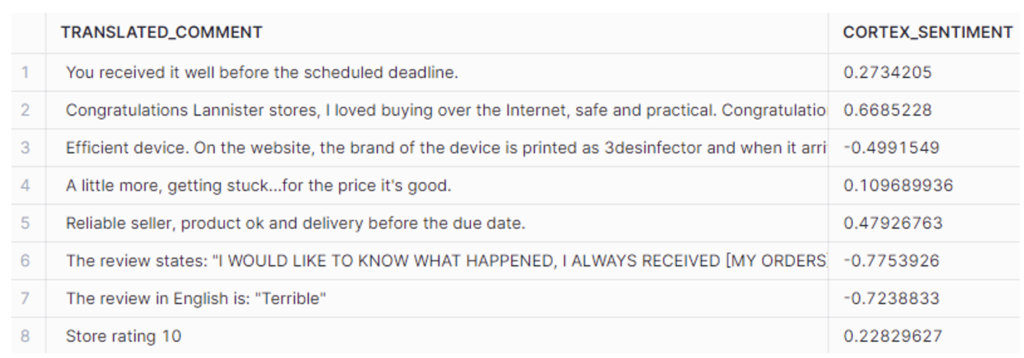
Figure 3: SENTIMENT Example
The model seems to be more stringent with positive reviews and performs better at detecting negative sentiments. It generally assigns lower scores to positive sentiments when compared to human evaluations.
Pros:
- Fast execution.
- Easy to use.
- Fair results.
Cons:
- No control over the functionality.
- Stricter with positive reviews.
Summarize
This operation generates a summary of the provided text, suitable for analysing documents or long texts for easier processing (see the SUMMARIZE documentation for more info).
- SQL:
SELECT translated_comment, SNOWFLAKE.CORTEX.SUMMARIZE(translated_comment) AS comment_summary FROM ORDER_REVIEWS_TRANSLATED LIMIT 1000
- Python:
reviews = reviews.withColumn(
"comment_summary",
Summarize(col("translated_comment"))
)
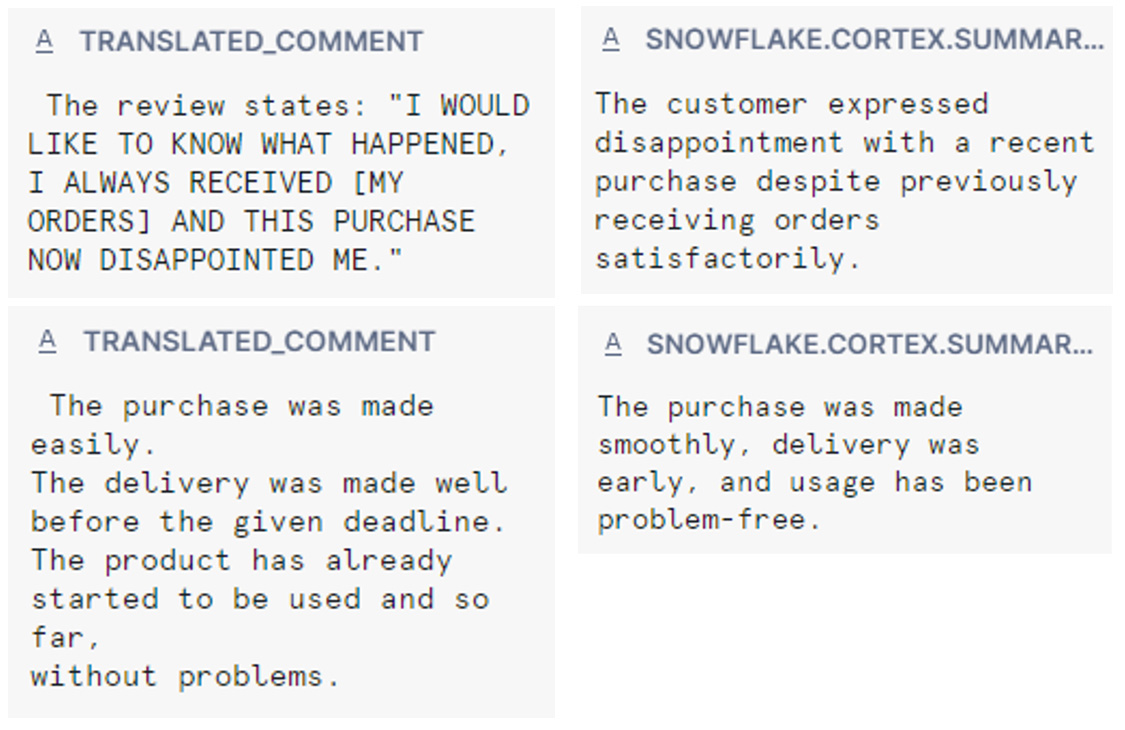
Figure 4: SUMMARIZE Example
Based on our testing, we can conclude the following:
Pros:
- Easy to use.
- Very straightforward.
- Very good results.
Cons:
- The current version only supports English.
- No control of the model and output (tone, length, etc.).
Getting an overview of the data is useful, but what if we want to extract specific content from the given text? With this in mind, let’s examine the next function of Cortex.
Extract Answer
This operation evaluates the document or text to identify the specific section that answers a given question. It analyses the context of the data using a Snowflake-managed LLM to pinpoint the relevant information (see the EXTRACT_ANSWER documentation for more about this).
- SQL:
SELECT translated_comment, SNOWFLAKE.CORTEX.EXTRACT_ANSWER( translated_comment, 'Extract parts of the review regards shipping.') AS shipping_details FROM ORDER_REVIEWS_TRANSLATED LIMIT 1000
- Python:
reviews = reviews.withColumn(
"comment_answer",
ExtractAnswer(col("translated_comment"), 'Extract parts of the review regards shipping.')
)
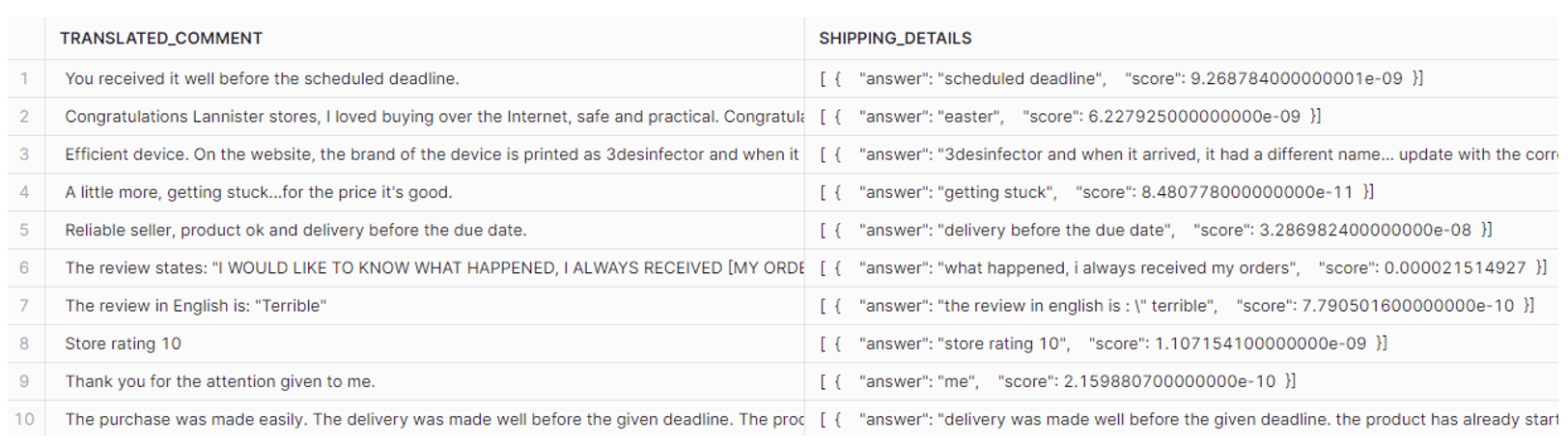
Figure 5: EXTRACT Answer Example
Pros:
- The output data is provided in JSON format which facilitates processing.
- Includes a score indicating how well the provided text answers the given question.
- Possibility to include a prompt in the question.
Cons:
- Hallucinations if the text doesn’t contain the answer.
Performance and Cost Considerations
Now that we have analysed most Cortex LLM functionalities as well as their trade-offs, let’s take a look at the processes executed on . It is important to consider the resources required for these operations to better align them with your needs, and you can find the costs associated with each function in the table below:
Function | Model | Context window (tokens) | Snowflake credits per million tokens | |
|---|---|---|---|---|
EXTRACT ANSWER | Snowflake managed model | 2,048 for text | 0,08 | |
SENTIMENT | Snowflake managed model | 512 | 0,08 | |
SUMMARIZE | Snowflake managed model | 32,000 | 0,10 | |
TRANSLATE | Snowflake managed model | 1,024 | 0,33 |
Now, let’s investigate our execution times by checking our previous executions. Note that Cortex executions were made using only 1,000 rows of the Reviews dataset, whereas Snowpark tests were executed using the whole dataset. This table shows the times each operation took using different warehouse configurations:
Function | Not NULL (1000) | All data (99K) | Not NULL (49K) | Not Null (49K) | |
|---|---|---|---|---|---|
Translate | 32s | 43m 21s | 16m 6s | 16m 17s | |
Sentiment | 0.47s | 39m 4s | 16m 40s | 17m 28s | |
Summarize | 1m 19s | 38m 57s | 16m 46s | 17m 19s | |
ExtractAnswer | 1.6s | 39m 10s | 16m 54s | 16m 23s |
We can see that the size of the warehouse does not significantly impact the processing time for the operations involving LLMs. For these language tasks, the recommended size of the warehouse is Small or Medium, ensuring optimal resource utilisation without unnecessary computational costs. For general information on compute costs, see Understanding Compute Cost.
Please note that these analyses were conducted during the release in June 2024. Given that Snowflake is constantly improving and releasing new capabilities, these computation details may differ in future versions.
Count Tokens
Understanding the cost associated with tokens is essential for managing computational expenses, but how can we determine the cost of a specific query? To do so, we must first define what tokens are: a token in a language model is a basic unit of input/output text. In NLP tasks tokens are often words, sub-words, or characters. Text is broken down into tokens for more efficient processing, and each model has its own unique tokenisation method.
Note that for generative functions (COMPLETE*, SUMMARIZE, and TRANSLATE) the costs take both input and output tokens into account, while for functions that solely extract information (EXTRACT_ANSWER, SENTIMENT), only input tokens are counted. You can find this information in the official Snowflake documentation here.
(*The costs for the COMPLETE function will be analysed in part 2).
Snowflake provides a helper function to calculate the number of tokens a query will use. Given the function name (TRANSLATE, SENTIMENT, SUMMARIZE or EXTRACT_ANSWER) and the input text, it will calculate how many tokens the query will use. (See the COUNT_TOKENS documentation for more details).
SNOWFLAKE.CORTEX.COUNT_TOKENS(function_name, input_text)
When the input is a table column, the cost function will evaluate the tokens needed for each row, so if we want to know the total cost, we need to aggregate the output values as follows:
SELECT SUM(translate_tokens) as translate_tokens,
SUM(sentiment_tokens) as sentiment_tokens,
SUM(summarize_tokens) as summarize_tokens,
SUM(extract_answer_tokens) as extract_answer_tokens
FROM (
SELECT SNOWFLAKE.CORTEX.COUNT_TOKENS('translate', REVIEW_COMMENT_MESSAGE) as translate_tokens,
SNOWFLAKE.CORTEX.COUNT_TOKENS('translate', REVIEW_COMMENT_MESSAGE) as summarize_tokens,
SNOWFLAKE.CORTEX.COUNT_TOKENS('translate', REVIEW_COMMENT_MESSAGE) as sentiment_tokens,
SNOWFLAKE.CORTEX.COUNT_TOKENS('translate', REVIEW_COMMENT_MESSAGE) as extract_answer_tokens
FROM ORDER_REVIEWS_TRANSLATED
WHERE REVIEW_COMMENT_MESSAGE IS NOT NULL
LIMIT 1000
);
Executing this statement yields the same number of tokens for each function, 19,872, because the COUNT_TOKENS function only considers the provided text in the second argument in its token calculation. It’s important to note that generative functions like TRANSLATE and SUMMARIZE should also account for output tokens to compute the total cost of the query. (You can estimate this by executing COUNT_TOKENS on the results after running the query).
We also wanted to understand the impact of NULL values on the results, so we executed the COUNT_TOKENS function on the entire dataset twice – once after filtering out the empty values and once without applying any filtering:
All data (99K) | Not NULL (49K) | |
|---|---|---|
979921 | 821665 |
Given the hallucinations observed in the previous section, it is likely that NULL values also affect the cost calculation, so we recommend filtering out empty values when performing LLM operations.
Conclusion
The introduction of Snowflake Cortex, particularly its LLM functionalities like TRANSLATE, SENTIMENT, EXTRACT_ANSWER, and SUMMARIZE, marks a significant advancement in making powerful AI tools more accessible and applicable within the Snowflake ecosystem. By integrating these capabilities in a secure and scalable environment, Snowflake has enhanced its platform and empowered users to leverage AI more effectively in their data strategies.
As LLMs are integrated more and more into tech solutions, Snowflake’s incorporation of these models underscores its commitment to leading the data technology landscape. The platform’s ongoing evolution and the addition of new features make it a reliable and up-to-date tool for data-driven applications.
In our next blog post we’ll dive deep into the COMPLETE functionality; this feature generates output text based on specific guidelines, offering versatile applications. We’ll use it to compare and complete the results obtained from TRANSLATE, SENTIMENT, EXTRACT_ANSWER and SUMMARIZE, providing a comprehensive analysis of Cortex’s capabilities. Make sure to check out the results and discover COMPLETE’s awesome abilities in Part 2 of this series! And remember that our team of experienced experts is ready to help you get the most out of your Snowflake environment, so please reach out to us for whatever you need.
