16 Oct 2024 LLMOps: The What, Why & How
Large Language Models (LLMs) are powerful AI tools that have taken the world by storm. Designed to understand and generate human-like text and trained on vast amounts of data, they can perform a wide range of tasks, such as answering questions from documents, summarising documents, coding and even more. Here at Clear Peaks we have implemented many projects with LLMs, like building Retrieval-Augmented Generation (RAG) pipelines in Cloudera, integrating LLMs in Snowflake, or building a RAG chatbot with Azure for SharePoint libraries.
Retrieval-Augmented Generation is a common use case in Generative AI applications, where the customer wants to interact with proprietary data, and the LLM’s knowledge is enhanced by incorporating the customer’s private data. Today our blog post will walk you through a key topic that anyone building Generative AI applications should be aware of – Large Language Model Operations (LLMOPs).
What is LLMOps?
LLMOps is a set of practices and tools that allow developers to experiment, automate and monitor all the processes involved in the development of an LLM application, as well as to build and deploy it. LLMOps requires collaboration across teams to make operationalising any LLM app more efficient and scalable.
This may sound familiar, as MLOps is also a set of practices that deploy, automate, and monitor an ML workflow. However, the main difference is that MLOps deals with the training of models from scratch rather than fine-tuning or adapting an existing model to a specific use case, which is what LLMOps does. We’ll dive into a detailed comparison between MLOps and LLMOps later.
LLMOps deals with the experimentation and benchmarking of language models by facilitating the integration of LLM and RAG pipelines for domain-specific data. It offers robust prompt engineering and management tools, and also incorporates human feedback into evaluation processes. LLMOps significantly enhances productivity, reduces the time-to-market, and improves the overall quality and reliability of AI-powered applications. To summarise, LLMOps provides methods and processes to implement and manage the following key functionalities:
- Data Management: Effective data management in LLMOps involves ensuring that large-scale datasets are clean, well-organised, and always available for training and fine-tuning models.
- Model Development: This involves selecting the best foundational model based on given constraints and adapting it to a specific use case through RAG or fine-tuning. Moreover, during the evaluation phase, metrics such as accuracy, relevance, and answer faithfulness are used to ensure the LLM application meets business objectives.
- Deployment Process: Seamlessly deploy LLM pipelines considering factors like scalability, latency, infrastructure requirements, and data policies.
- Monitoring and Observability: Track application health by monitoring token usage, latency, error rates, LLM call count, and success rates, thus helping to identify bottlenecks in the application.
LLMOps vs MLOps
MLOps and LLMOps share the same goal, managing the end-to-end lifecycle of building, deploying, and monitoring ML models and LLMs, respectively. However, there are some key differences:
- MLOps requires training and building a model from scratch, whereas LLMOps typically uses a pre-trained model that that is fine-tuned with domain-specific knowledge.
- The computational resources required for LLMOps and MLOps vary depending on several factors: whether the LLM is trained from scratch or fine-tuned, the use of prompt engineering techniques, the size of the foundational model, and the training process for the ML model. As a result, the computational demands for LLMOps differ from those for MLOps.
- The deployment infrastructure for the two types of models also varies. ML models are typically deployed through API endpoints using proprietary hardware or cloud services. On the other hand, LLM models require high-performance computing (HPC) systems for fine-tuning and inference, due to their large number of parameters. LLMs can be deployed on either cloud-based or on-premises services.
- Evaluation metrics for ML models, like those used for classification and regression tasks, are well-defined and often employ cross-validation strategies. In contrast, the evaluation of LLM applications is more diverse, involving traditional metrics, LLM-assisted frameworks (LLM-as-a-judge), and assessments of answer relevance/faithfulness to detect hallucinations.
- Human feedback is often gathered to apply reinforcement learning from human feedback (RLHF), which can be used to enhance LLMs or to build evaluation datasets with human feedback.
This table highlights the differences between the two in their shared aspects:
| MLOps | LLMOps | |
|---|---|---|
Data management | Structured and unstructured data sources. | Manage large-scale text data (text-corpora). |
Model development | Training ML model from scratch.
Evaluate results with quantitative metrics and cross-validation techniques, focusing on specific task performance. | Foundational model selection as LLM app baseline.
Perplexity and language model metrics, human evaluation for coherence and relevance. Benchmarking on diverse NLP tasks. Prompt-based evaluation techniques. |
Deployment and hosting process | API development, containerisation, and integration into production systems.Both batch and real-time inference. | Must handle the hosting of LLM models with billions of parameters. Optimisation for low-latency access to these models. Deploy LLM chains, agents, pipelines, and vector databases (knowledge stores). |
Monitoring and observability | Monitor data drift, model decay, and concept shift. Resource utilisation monitoring. | Monitor LLM system health, token usage, and cost tracking (if using priced APIs). |
Table 1: MLOps vs LLMOps: functionalities and features
Why LLMOps?
Overall, the use of LLMOps provides more efficiency, reduces risks, and offers scalability. However, if you’re not yet convinced that LLMOps principles should be applied throughout the entire lifecycle of Generative AI app development, here are three use cases where it may prove invaluable:
- Example nº1: You need to evaluate your LLM application and have considered doing so with human feedback, as your team wants to manually assess the app. With LLMOps, you can integrate feedback after each prompt completion, evaluating it based on any metric you define, such as correctness, helpfulness, or conciseness. This feedback allows you to construct datasets of successful examples, which can then be used to improve your prompts using the few-shot technique, or to apply fine-tuning with RLHF.
With LLMOps techniques, the production and evaluation processes are more efficient, improving model performance and managing dependencies between processes.
- Example nº2: You unexpectedly received more requests per minute than the LLM can handle. Similar to MLOps, LLMOps excels at monitoring and tracking every step of the process. One key insight from this monitoring is information about LLM calls and token usage. With this data, you can easily control the volume of LLM requests in real time, which helps you to avoid exceeding limits and scale resources up or down as needed.
This is a clear example of risk reduction, achieved by continuously monitoring and identifying bottlenecks or peaks in the server, effectively managed through the comprehensive analysis provided by LLMOps.
- Example nº3: You have built an LLM application, for instance for sentiment analysis, and it has been so successful that you have been tasked to build five more, covering areas like summarisation and grammar correction. Instead of manually repeating the entire end-to-end lifecycle for each new task, you can leverage LLMOps to automate key processes such as data preparation, model tuning, deployment, maintenance, and monitoring. For instance, an automated system to evaluate and compare different prompts can be particularly useful when creating or refining a prompt.
The scalability of projects improves significantly once you have control over each step and process, enabling faster project releases and ensuring smoother workload management.
In short, LLMOps allows you to automate and control processes, as well as to manage and scale multiple projects.
LLMOps Platforms Overview
There are several platforms available for managing LLM application workflows. In this section, we’ll share a concise review of the distinctive features offered by three leading MLOps providers (Amazon Bedrock, Azure AI Studio, and MLFlow). We’ll also explore two of the most popular platforms, according to GitHub stars and B2B reviews from AI Multiple (Deepset AI and NeMo by Nvidia). Finally, we’ll look at LangSmith, one of the first platforms to create a framework for LLM app development.
In the table below you can see their characteristics:
Useful for | Traceable features | Cost | Hosting options | |
|---|---|---|---|---|
Amazon Bedrock | – Developing. | – Prompts. | Depends on the chosen model. | Own Amazon Virtual Private Cloud (VPC). |
Azure AI Studio | – Developing. | – Prompts. | Depends on the chosen model, compute resources, data storage, and analytics services. | – Azure cloud storage services. |
Deepset AI | – Developing. | – Prompts. | SaaS platform: subscription paid annually. | – Cloud AWS S3. |
LangSmith | – Monitoring. | – Prompts. | Free and paid plans available. | – External databases. |
MLFlow for LLMs | – Deploying (experimental). | – Prompts. | Free and paid plans available. | -Self-host foundational model. |
NeMo by Nvidia | – Developing. | – Model training. | Nvidia AI Enterprise subscription, paid per hour depending on the EC2; 90-day free trial offered. | -Self-host foundational model. |
Table 2: LLMOps Platforms comparison
A thorough comparison of the various options is not in the scope of this blog. Moreover, it’s not our aim to favour one over another, as the right choice for an organisation will depend on multiple factors. However, if you’d like some help in deciding which is the right choice for you, don’t hesitate to contact us!
In the following part of this blog post, and as an illustrative example of how to apply LLMOps to your LLM apps, we’ll run through how the LangSmith platform works: it boasts a large number of features, is easy to integrate once you’ve created your LLM app, and it offers a free tier.
LangSmith Features
LangSmith keeps track of every step in the LLM workflow, offering a complete set of observability features as shown below:
| Traceability on | Monitoring | Extras |
|---|---|---|
Chains/Objects | Volume | Feedback Annotation |
Input/Output | Latency | Custom Metrics |
Tokens | Tokens | Add Feedback to Dataset |
LLM Calls | Cost | Dataset for few-shot |
Latency | Streaming | Prompt Design Hub |
Table 3: LangSmith platform observability features.
LangSmith is an integral part of the LLM app lifecycle’s development methodology, although the complete process can also be managed using LangChain platforms. LangChain handles the chaining of app components, with deployment managed by LangGraph Cloud, a platform designed for seamless LLM app deployment. LangSmith takes care of debugging, testing, and monitoring tasks, ensuring the app performs as expected. The image below shows the LangChain workflow for putting an LLM app into production:
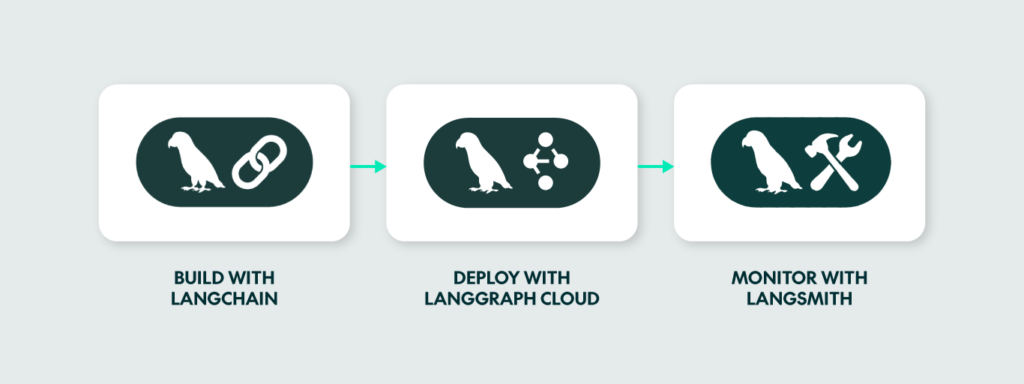
Figure 1: LangChain’s LLM application workflow
To log traces during the LangChain development process, you must add tracking environment variables to the code. This ensures that every time the code is executed, all data and metadata are automatically stored in LangSmith. Traces can be logged using the Python or TypeScript SDKs, or through the API.
Alternatively, you can use the @traceable Python decorator on any function that requires tracing. This method provides greater flexibility for creating specific use cases: rather than grouping all steps together in a single run, each step of the pipeline is logged individually under a designated run type, such as ‘llm‘ or ‘retriever’.
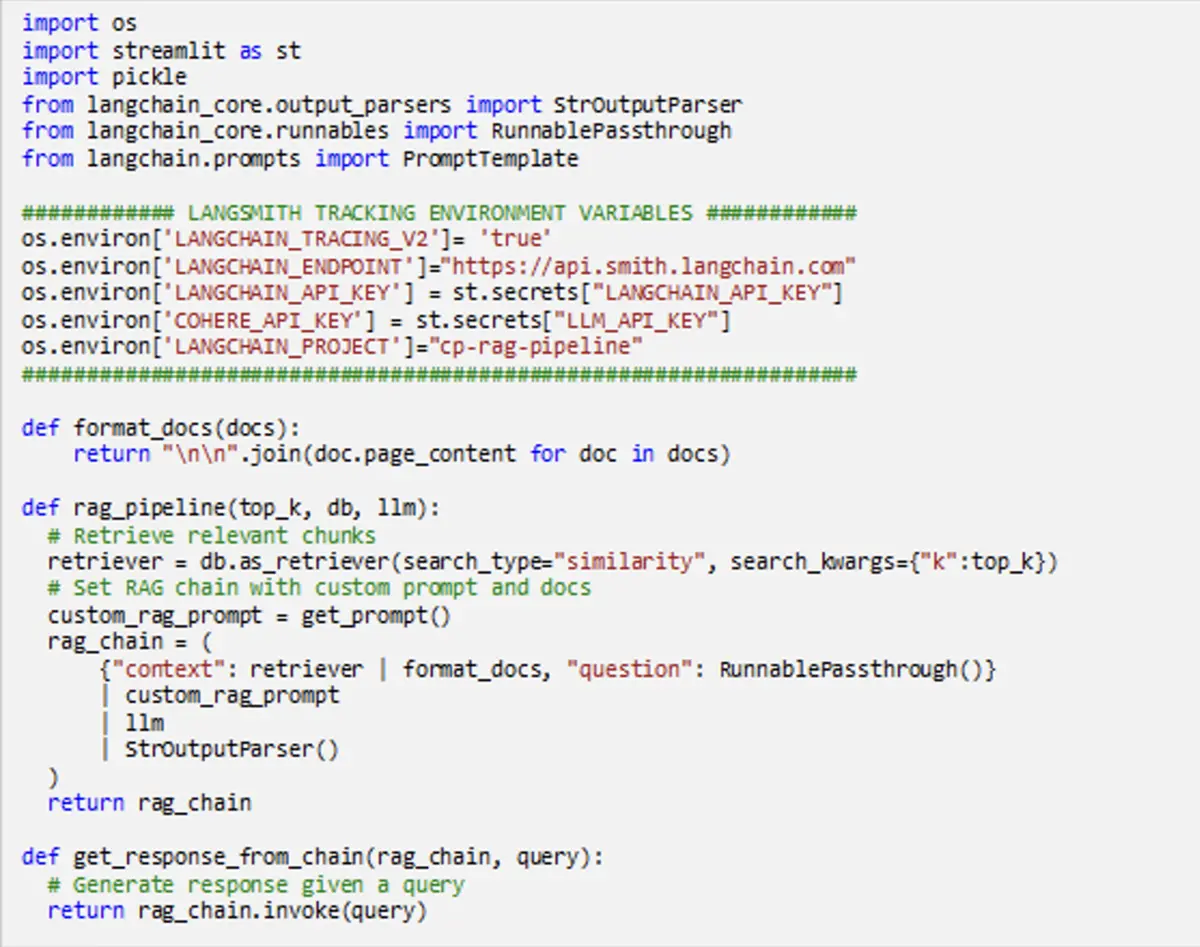
Figure 2: LCode snippet explanation of how to log traces in LangSmith
In our case, we built a RAG app, logged traces using the Python SDK, and adapted LangChain-provided chains to fit it. The Projects section (shown below) displays all the features available for monitoring the app runs. The main page can be customised to display selected characteristics, filter runs, add them to datasets, and access monitoring statistics. On the right side of the page, a few key stats are displayed. The latency percentiles at the 50th and 99th levels (P50 and P99) offer insights into general pipeline performance and help to prepare for high-workload scenarios. The following figure shows this main page with a few sample runs:
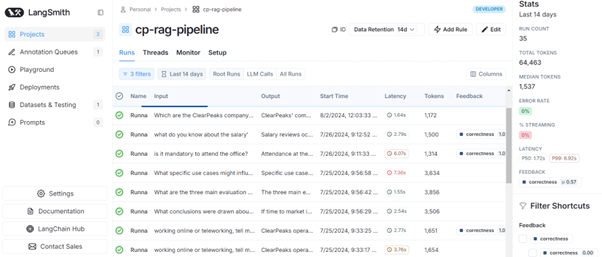
Figure 3: LangSmith’s main page for monitoring runs
To further analyse any run, simply click on it, and the corresponding chain is displayed. This allows you to examine the inputs and outputs of each component involved, making debugging easier and enabling you to evaluate every step of the process:
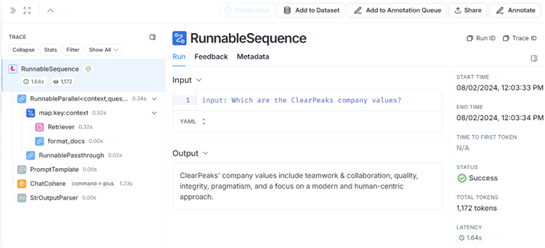
Figure 4: LangSmith’s LLM chain overview
The Datasets & Testing section allows you to create datasets from the logged data. These datasets can be used to customise prompts, generate reference prompt completions, or evaluate them using LangSmith evaluators. The following figure shows an example of a dataset created with completions logged into the platform:
Figure 5: LangSmith dataset sample visualisation
LangSmith is an LLMOps platform, but it only provides methods for monitoring and observability, so how are deployment and hosting handled?
Deploying and Hosting LLM Apps
When considering how to host your LLM app, it’s important to distinguish between two scenarios:
- Fine-tuning a pre-trained LLM
- Adapting a pre-trained LLM without changing its architecture
Hosting becomes relevant when you are fine-tuning or building from scratch. In our case, since we are using LangSmith, LangGraph Cloud is the managed service for hosting LangGraph applications. Self-hosting a model ensures it remains available for as long as you choose, with platforms offering hourly tiers for hosting, and many of these platforms also manage the deployment process.
If you’re not fine-tuning a model, you can use an API for inferencing. In this case, you leverage the pre-deployed model provided by the LLM provider, accessing it via API. This approach is appropriate when you are not introducing new modifications to the already deployed model. Instead, the model can be adapted to your use case through methods like fine-tuning (e.g., Parameter-Efficient Fine Tuning, PEFT), prompt engineering, or RAG, amongst others. LangGraph also allows you to build the LLM app by modelling the steps as edges and nodes in a graph.
When it comes to deployment, this can be on cloud or on-premises.
Cloud-based solutions offer more flexibility, operating on a subscription model that allows you to scale usage up or down depending on your workload; infrastructure maintenance is also managed for you. On the other hand, on-premises deployments provide greater control over your architecture, data, and the deployment process itself.
To deploy a LangChain LLM app, there are several options: using LangGraph Cloud, your own infrastructure, or platforms like Kubernetes or Docker. LangServe is another option from LangChain that deploys runnables and chains as a REST API. It is a library integrated with FastAPI, creating API endpoints for seamless deployment.
Conclusions
As the number of LLM applications grows, the urgency to deploy them into production increases. LLMOps platforms are gaining popularity and are continuously updated with new features, methods, and functionalities to address specific use cases.
In this blog post, we’ve explored the concept of LLMOps, sometimes referred to as MLOps for LLMs. We’ve discussed the differences between these two types of production platforms and explained why they are necessary, and additionally we’ve presented some of the most competitive LLMOps platforms, focusing on the open-source LangSmith. We’ve examined its key characteristics, functionalities, and methods, and reviewed the various options for hosting and deploying it.
Here at ClearPeaks we have extensive experience in developing and deploying a wide range of LLM applications. We help our customers select the right foundational model and adapt it to their specific use cases. And what’s more, we support our customers throughout the entire Generative AI use case development lifecycle, advising them on the best platforms and adhering to LLMOps principles to maximise the potential of LLM apps. So, if you’re curious about how Generative AI can benefit your organisation, or if you’re already leveraging Gen AI but need help to push it forward, don’t hesitate to contact us and we can give you that extra boost!
