
11 Dec 2024 How to Optimise ODI Performance with the Right Knowledge Modules
In the context of data warehousing, ETL plays a crucial role in consolidating, cleansing, transforming and organising data from diverse sources into a unified, consistent dataset. As well as ensuring data reliability and accuracy, it is also important to ensure the whole process is performance-optimised and timely.
In this article, we’ll explore some optimisation techniques specifically tailored for Oracle Data Integrator (ODI), a leading ETL tool.
We’ll cover the following:
- Choice of Knowledge Module
- Customising Knowledge Modules to disable/enable indexes
- Gather Statistics
Choice of Knowledge Module
There is a special (and perhaps its most powerful) category of component in ODI called Knowledge Modules. These consist of code templates that can be used to perform a wide range of tasks during the data integration process. They are reusable, customisable, and have specific names based on the tasks they are designed to do.
In this section we’ll look at Loading Knowledge Modules (LKMs) and the advantages they can offer when chosen correctly.
Firstly, it is important to remember that LKMs are used in the process of loading data from a source datastore to a staging table, which means that not all mappings will require this component. LKMs are particularly useful in scenarios where the source datastore and target datastore use different technologies, or are hosted on separate servers.
Secondly, it is vital to select the most suitable LKM for each mapping. The typical naming convention for LKMs is as follows:
LKM source technology to target technology (loading method)
It should be relatively easy to choose one if we know the source and target technology. For example, we could use the LKM SQL to Oracle (Built-in).GLOBAL LKM if we are loading data from SQL to an Oracle environment. This will mean a more efficient loading process that will likely speed up the execution time.
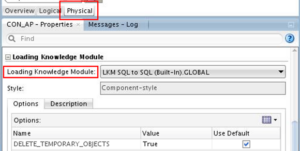
However, choosing the right technologies is not the only thing that can speed up the loading process, as the loading method can also play an important role. For example, if both the source and target technologies are Oracle, instead of using the default method, a database link (DBLINK) can be used to achieve a faster loading process (using, for example, the LKM Oracle to Oracle Pull (DB Link).GLOBAL LKM). This can be particularly helpful when loading massive amounts of data.
![]()
ODI supports multiple methods for performing data upload operations across different technologies. For instance, when working with Big Data, ODI offers a variety of LKMs to facilitate data uploads between HDFS, Hive, Spark, HBase, and Pig. Each of these tools provides distinct performance advantages, with some enabling faster data uploads than others. So the choice of LKM is a key factor in determining the overall efficiency and performance of your data upload processes.
Customising Knowledge Modules to Disable/Enable Indexes
Indexes enhance the performance of SQL queries by enabling faster data retrieval, but they can negatively impact the performance of certain operations, particularly those involving data insertion or deletion. This is because whenever rows are inserted or deleted, all indexes associated with the affected table must be updated, which can significantly slow these processes down.
To mitigate this, a best practice when inserting new data into a table with existing indexes is to disable the indexes before the data load, then re-enable them afterwards. In ODI this can be done using Knowledge Modules – specifically Integration Knowledge Modules (IKMs).
Whilst LKMs are typically used for data loading, IKMs handle data integration tasks in the target system. These tasks may include strategies such as Insert, Update, or Slowly Changing Dimensions (SCDs), and IKMs can be customised to handle the process of disabling and enabling indexes during data load operations.
Disabling and enabling can also be extended to table constraints, as constraint validation can significantly impact performance, especially when inserting large volumes of data into a table.
It is important to note that unique indexes cannot be disabled directly. However, this limitation can be worked around if the unique index is generated through a unique constraint, using the following syntax:
CONSTRAINT constraint_name UNIQUE (column1, column2, ... column_n) USING INDEX
If a unique index is created directly (i.e., without a constraint), attempts to disable it will lead to errors.
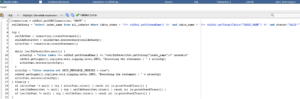
In ODI, the option to enable or disable indexes and constraints is typically available as part of the IKM configuration in the Physical layer of a mapping. This flexibility allows you to control index behaviour during data load processes effectively, avoiding potential errors while optimizing performance:
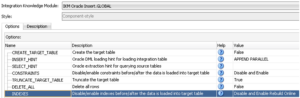
There are, however, some types of IKM that do not offer these actions automatically, such as the IKM SQL Control Append IKM:
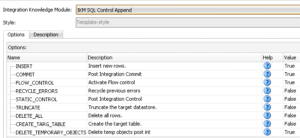
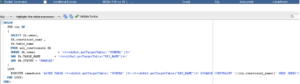
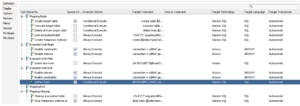
Fortunately, a KM can be customised to include new tasks or to change existing ones. To do so, we access the Knowledge Modules list in the Projects or the Global Objects menu in the Designer tab (depending on whether you want the IKM to be specific to a project or available for use across all projects), and duplicate the IKM we want to use as a base:

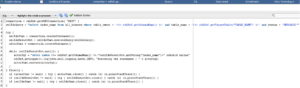
If we double–click on the newly created IKM, we can access the general configuration, but more importantly, the tasks it will perform when executed:
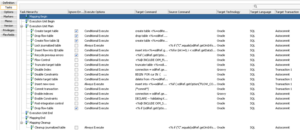
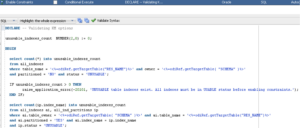
The task list now includes options for disabling and enabling indexes and constraints. It also allows you to define the PL/SQL command to be executed and to configure other execution-related options for the tasks:
Gather Statistics
Oracle provides the DBMS_STATS package to facilitate the collection of various types of statistics to enhance performance. Typically, Oracle automatically gathers statistics for database objects that are missing or have outdated statistics during a predefined maintenance window. However, in a data warehouse context, it may be necessary to manually gather statistics tailored to specific use cases, such as when data changes in a table which is then being used as a source to load another table.
The operations included in this package can be applied to statistics stored either in the dictionary or in a table created for this purpose; the package also supports user-defined statistics for tables and domain indexes.
In this section we’ll focus on the GATHER_STATS procedures, specifically the GATHER_TABLE_STATS operation.
The GATHER_STATS procedures can be used in ODI and can be crucial for optimising SQL execution plans. They can be applied in ODI in the following situations:
- Interfaces and Mappings: To ensure efficient ETL processes by collecting statistics on source and target tables.
- Packages: As procedural steps within ODI packages to automate the gathering of statistics at key stages in a data integration workflow.
- Scenarios: As part of generated scenarios to ensure that statistics are gathered during the automated deployment of ETL processes.
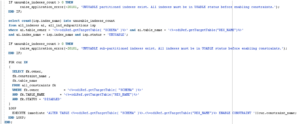
Below is the syntax for the GATHER_TABLE_STATS procedure, as well as an explanation of the parameters involved:
DBMS_STATS.GATHER_TABLE_STATS ( ownname => ‘SCHEMA_NAME’, tabname => ‘TABLE_NAME’, granularity => ‘GRANULARITY’, method_opt => ‘METHOD_OPT’, cascade => ‘CASCADE’, degree => ‘DEGREE’ );
The parameters represent the following:
1. SCHEMA_NAME: The schema containing the table(s) for which statistics are to be gathered. This parameter is optional and can be used to gather statistics for all tables in the schema.
- Example: ‘HR’
2. TABLE_NAME: The name of the table for which statistics are to be gathered. This parameter is required when gathering statistics for a single table.
- Example: ‘HR.EMPLOYEES’
3. GRANULARITY: Specifies the level of granularity of the statistics. It can be set to ‘GLOBAL’, ‘PARTITION’, ‘SUBPARTITION’, etc.
- Example: ‘GLOBAL’
4. METHOD_OPT: Defines the method options for collecting statistics on columns. This parameter also controls whether histograms should be gathered, and if so, on which columns.
- Example: ‘FOR ALL COLUMNS SIZE AUTO’
5. CASCADE: Determines whether statistics should also be gathered for the indexes on the table. The default value is ‘TRUE’.
- Values: ‘TRUE’ or ‘FALSE’
- Example: ‘TRUE’
6. DEGREE: Specifies the degree of parallelism to be used for gathering statistics. Increasing this value can speed up the process but requires more resources.
- Example: ‘4’
7. OPTIONS: Additional options for gathering statistics, such as ‘GATHER’, ‘GATHER AUTO’, ‘GATHER STALE’, ‘GATHER EMPTY’, etc.
- Example: ‘GATHER’
This command can be run directly in a mapping, normally in the End Mapping Command option in the Physical layer:

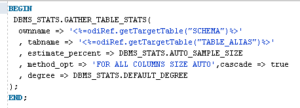
However, this is not the only way to include the GATHER_STATS procedure in a mapping. You can also customise the IKM to include this command as a new task. This approach ensures that statistics for the table are gathered during mapping execution, further improving performance:
The new ‘Gather Stats’ step would be included in the customised IKM, with the following PL/SQL command:
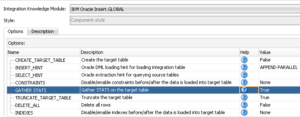
If we use the custom IKM in a mapping, we can see the new task has been added:
To conclude this section, the benefits of using GATHER_STATS in ODI are:
- Optimised SQL Execution: Up-to-date statistics help the Oracle Optimizer to generate more efficient execution plans.
- Improved Performance: Better execution plans lead to faster query execution and improved overall ETL performance.
- Automation: Integrating GATHER_STATS into ODI workflows automates the statistics collection process, reducing manual maintenance efforts.
By using the GATHER_STATS command effectively within ODI, you can ensure that your ETL processes are running optimally, with the most efficient execution plans.
Conclusion
ODI typically delivers excellent performance thanks to its E-LT architecture, which harnesses native DBMS SQL and utilities. However, real-world scenarios often mean performance challenges, and in this article we’ve aimed to address one such aspect with targeted solutions.
There are additional optimisation techniques to consider, including:
- Install and run ODI Studio on the same subnet where the repository DB server is running.
- Run the Agent on the same machine as the database to take advantage of database utilities.
- Use JAVA EE Agents to benefit from the load balancing capabilities available in Oracle WebLogic.
- Whilst the staging area is typically located on the target server, moving it to the source server can enhance performance in some cases.
- Enable the Use Unique Temporary Object Names option when multiple mappings load the same target table.
- Increase the Array Fetch Size and Batch Fetch Size in the Data Server configuration to optimise data fetching and insertion by the Agent.
- Execute filters on source servers.
Here at ClearPeaks, our certified experts are ready to support you in extracting the maximum value from your data and in meeting your strategic business needs. Connect with us today to unlock the full potential of your data integration processes!
