10 Dec 2024 How LLMs Are Changing Programming (So Far)
The End of Endless Google Searches and Stack Overflow
Programming used to mean mastering Google: you’d dive deep into forums, speed-read Stack Overflow posts, and experiment with various user-generated solutions until you found a snippet that you liked.
Now? I just press a keyboard shortcut and ask ChatGPT to generate the code directly.
LLMs like ChatGPT and Anthropic’s Claude have essentially “eaten the internet” — Stack Overflow for breakfast, GitHub for lunch, and MDN Web Docs for dinner, with all kinds of snacks in between.
LLMs Aren’t Replacing Us—Yet!
The role of a programmer is evolving, not disappearing. While we can now offload a lot of repetitive, mundane tasks to AI, we still need to know what to do and how things should work, and this type of know-how only comes from practice and experience.
The New Role of the Programmer
- Understand Requirements: See the bigger picture and what’s needed to achieve the goal.
- Be Aware of Constraints: What’s possible? What’s not? What infrastructure is required?
- Manage and Oversee: Micro-manage each step, ensuring that each piece of code aligns with your plan.
If you over-delegate to an LLM, you might not understand how your own code works, leaving you unable to debug or modify it effectively. Stay in control by doing the thinking and let the LLM do the typing!
Obfuscating Sensitive Data
When using LLMs, it’s crucial to protect sensitive details: replace unique names, swap out client info, keep identifiable data vague, and so on. This way, you’re sharing only what’s necessary to get useful results without exposing anything proprietary.
In the big picture, data has become a currency, and every interaction with an LLM adds to its real-world knowledge. Whilst we’re helping to make AI models more powerful and more useful, we’re also handing over valuable insights that could be absorbed into the AI and potentially be accessed by competitors down the line. Balancing AI’s benefits with data privacy means carefully obfuscating details so that you can leverage the power of LLMs without compromising critical information.
Choosing the Right LLM for the Job
At the time of writing, the state-of-the-art model is OpenAI’s ChatGPT o1. It seems noticeably superior to the rest in terms of coming up with a good solution, so when I need maximum “intelligence” I’m forced to use up some of my 50 weekly prompts quota.
Others swear by Claude 3.5 Sonnet, and I’ve seen tests where it outperforms ChatGPT-4o.
For most things, I use ChatGPT-4o because it’s eminently practical and available via the desktop app. Whatever your own preferences, it’s great to have a variety of tools at our disposal, and I encourage you to experiment with different models.
Versioning is More Important than Ever
With LLMs speeding up code generation, it’s easier than ever to make lots of small changes and potentially to go down the wrong path. Good version control becomes critical:
- Create frequent checkpoints
- Commit often on a local branch
This helps to track progress and make adjustments efficiently.
Good Tasks for LLMs vs. Tasks to Avoid
LLMs are Great for:
- Remembering commands: Example: “What’s the Git command for seeing the file history?”
- Generating small code snippets: Example: “Write a JavaScript function that takes a string, creates a new date, and appends the date to the string.”
- Handling repetitive tasks: Example: “Change a value in 100 JSON objects based on a condition.”
LLMs Struggle With:
- Broad or Vague Requests: Asking for “a house” is too open-ended. Instead, specify: “a house with four small windows, a blue door, and a high roof”, for example.
- New or Niche Code: It’s not a good idea to ask questions about brand-new features or cutting-edge libraries. Most LLMs have knowledge cut-off dates, so they don’t know about the latest updates.
- Complex, Multi-File Code with Delicate Inputs/Outputs: This requires a precise handling of the interactions between code files.
- Requests with Errors: LLMs rarely admit uncertainty. If you provide an incorrect prompt, they may still generate code rather than admit they don’t know. There is also the risk of hallucinations, when the LLM gives us a response containing something that is totally inaccurate.
Practical Tips for Getting the Best from LLMs
Be as clear as possible with your instructions. LLMs have large context windows, so it’s okay to repeat the same structure several times to avoid confusion and to make things clear and unambiguous. Here’s an example:
I want an HTML code snippet. It should have two <div> elements: First <div> Contains three <span> elements: First <span>: Text should say, “Hello, this is a test. Second <span>: Text should say, “And this is another test.” Third <span>: Text should say, “This is the final test.” Second <div> Contains an <img> element with a CSS class called “tomato.”
When working with multiple files or sections, I try to delineate them by using html-style tags like this:
<Server.ts> export class Recorder { onDataAvailable: (buffer: Iterable) => void; private amplitudeCallback: ((amplitude: number) => void) | undefined; private audioContext: AudioContext | null = null; private mediaStream: MediaStream | null = null; private mediaStreamS … </Server.ts> <ThreeScene.tsx> const mLight = new THREE.PointLight(0xffffff, 1, 0.3); mLight.position.set(0, 0, 0); mLight.castShadow = true; scene.add(mLight); // Torus geometries const geometries = [ new THREE.TorusBufferGeometry(8, 2, 40, 150), new THREE.TorusBufferGeometry(8, 2, 40, 150), new THREE.TorusBufferGeometry(8, 2, 40, 150) ]; … </ThreeScene.tsx>
I sometimes take a screenshot of the file structure so the LLM can understand where all the files are placed in relation to each other, and I say something like “See image for file structure”, and then I describe the issue or give the instructions after providing all the relevant files.
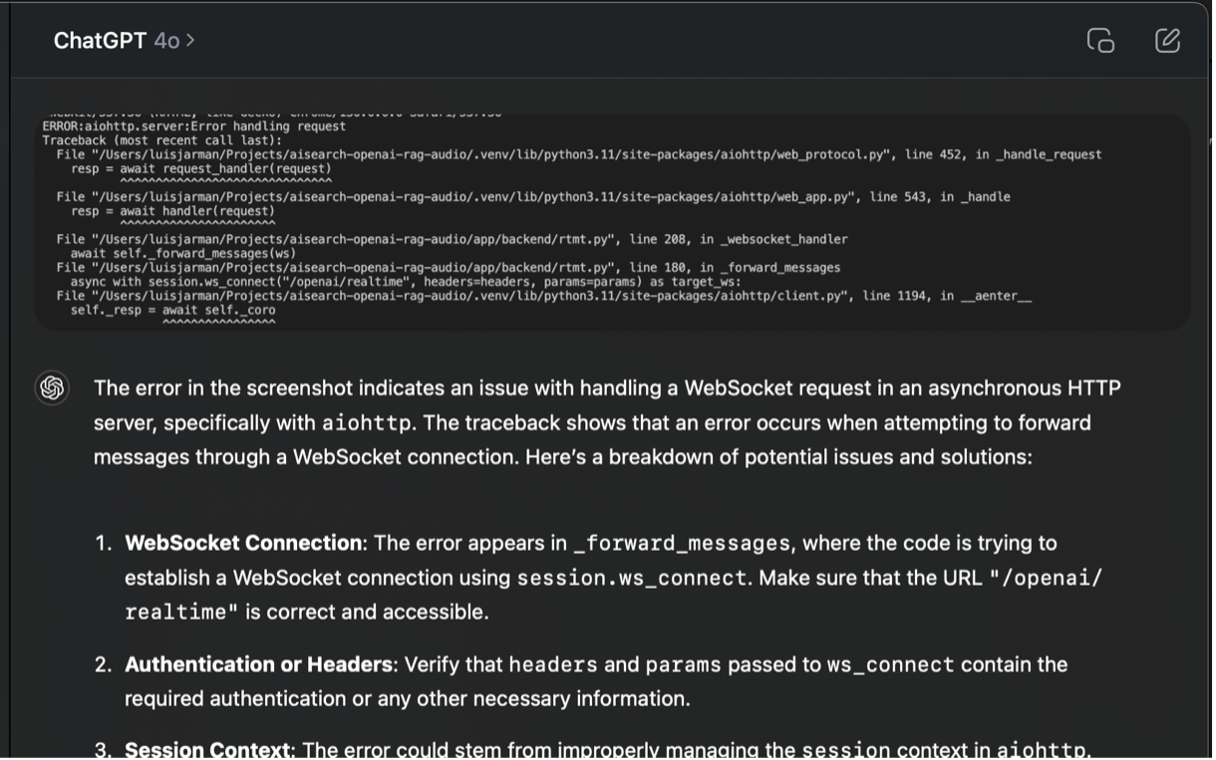
When I encounter a compilation error, a quick way of giving GPT the context is to take a screen shot and paste it in the conversation. *Copying then pasting the actual error text might provide the LLM with a better context than an image, but the multi-modal abilities of current models seem to understand and process images just as well.
Conclusion
The programming landscape is rapidly evolving thanks to LLMs. They’re transforming workflows, making it easier to generate code, manage repetitive tasks, and recall complex commands.
From understanding the need to obfuscate sensitive data to choosing the right LLM for each job, developers today are balancing AI’s power with careful use, and here at ClearPeaks our developers stay ahead by mastering these advanced techniques, ensuring faster development and high-quality code for our customers.
We all increasingly use AI both in our business solutions and in our daily routines to deliver the best results. Reach out with your ideas and contact us —we’re ready to bring them to life!
