25 Sep 2024 Handling Schema Drift with Apache NiFi
In the ever-evolving world of technology, it’s crucial to ensure data quality and maintain governance over dynamic data schemas. Schema drift, characterised by changes in the structure, distribution, or quality of data over time, can have far-reaching implications on downstream systems and processes.
To overcome these challenges, we’ve implemented a comprehensive, customised solution that leverages the power of Cloudera Flow Management (a.k.a. Apache NiFi) to provide solid schema-drift detection and monitoring capabilities.
In this blog post, we’ll delve into the details of our approach and explore the powerful tools and techniques we employed.
The NiFi Flow
Apache NiFi, a powerful data flow automation tool, played a pivotal role in our solution: its flexibility and extensibility allowed us to develop custom logic and integrate it seamlessly into our data pipelines.
Within NiFi, we implemented the flow from the ingestion to the detection of the schema changes, in a solution called Schema Changes Detector.
Our solution operates through a flow comprising three main stages, each represented by a NiFi process group:
- Ingest Data
- Data is ingested and inserted into a target table.
- If the insertion fails, indicating a potential issue with the data or a schema mismatch, further analysis is triggered.
- Ingest Data
- Detect Schema Changes
- Upon failed insertion, the system initiates schema change detection.
- The incoming data schema is compared with the schema of the target table to identify any discrepancies or modifications.
- Detect Schema Changes
- Store Schema Changes
- Detected schema changes are logged into a dedicated table, allowing for convenient monitoring and analysis of these events.

Figure 1: Schema changes detector flow
Example Use Case
To better understand the functionality of our flow, let’s look at a case in which we attempt to ingest a CSV file containing an airline’s customer satisfaction data into a Hive table, but the “age” field is mistakenly passed as a string instead of the intended integer type:

Figure 2: CSV file with age field as a string instead of an integer
In the figure above we can see a sample of the dataset, highlighting the two incorrect records. Below, we find the original target table schema:
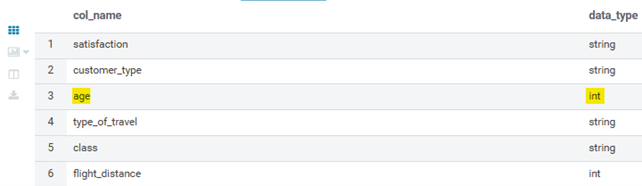
Figure 3: Hive table schema
Note that this – and what we will describe next – is just an example to present our solution. The concept can be applied to any combination of sources and targets, provided that the schemas are correctly detected and compared at the right points of the ingestion flow.
1. Ingest Data
The first step of the Schema Changes Detector flow is to ingest the file into the corresponding Hive table: we do so in the Ingest Data process group. If the insertion is successful, it means there were no issues, but if it fails it might be due to a difference in the schema, so we route the FlowFile to the Detect Schema Changes process group to address the issue:
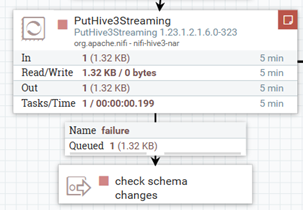
Figure 4: Route the file to check for changes
2. Detect Schema Changes
As mentioned, upon failing to upload the file to the Hive table, our flow process proceeds to check for potential changes between the schema of the incoming data and the actual schema of the target table. This happens in the Detect Schema Changes process group. To do so, we take the schema from the incoming file, and we compare it with the schema of the corresponding Hive table using a query. This allows us to identify any discrepancies or changes that may need to be addressed.
In some cases, we may need to normalise schemas before comparing them. This is required for schema structure validation, ensuring that the schemas are correctly defined and compatible for accurate comparison, particularly with respect to how null values are handled. This step is crucial for maintaining data integrity whilst ensuring compatibility between the incoming data and the target table schema. In our case, we use the Execute Script processor (Normalize avro schema in the picture below) where we run an ad hoc Python script:
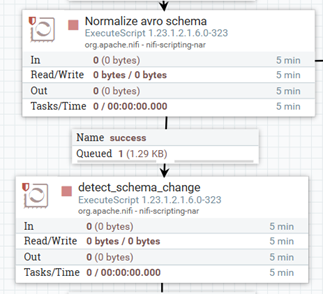
Figure 5: Schema normalisation
Below, we can see both schemas after the normalisation process. As we can see, the age field is supposed to be an int, whereas it’s a string in the incoming file:

Figure 6: Normalised schema in data

Figure 7: Normalised schema in table
The actual comparison is automated in NiFi using another Execute Script processor: detect_schema_change. This script will generate an attribute called comparison_output, containing the description of the detected discrepancy:
![]()
Figure 8: Changes between the schemas
This information can also be stored to track the changes in the schema and to facilitate monitoring and further analysis.
By using a custom attribute to indicate whether a schema change was detected or not, we can use the Route On Attribute processor to send our file to the last process group of our flow:
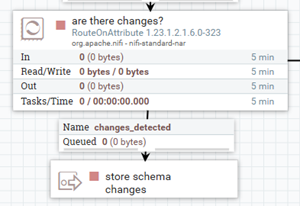
Figure 9: Processor detecting changes
3. Store Schema Changes
In this final process group, Store Schema Changes, we extract some metadata from the file that we failed to ingest, and store it in a dedicated log/event table:
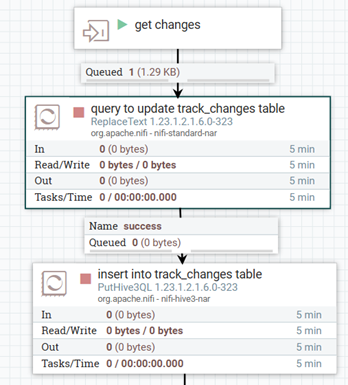
Figure 10: Store changes in hive table
First, using the replaceText processor, we generate a record that contains key information about the detected schema change. Then, as we can see in the image below, we store the information in the track_changes Hive table, which includes the table name, a description of the changes, and the timestamp:

Figure 11: Example of changes in hive table
This table can then be used to feed any monitoring dashboard, alert mechanism, or as a source of useful information for data stewards who might have to take actions based on the detected drift.
Conclusions
By using NiFi as our data movement and orchestration tool, with a touch of custom code, we’ve created a comprehensive schema drift detection and monitoring solution, allowing us to mitigate the potential impacts of schema changes on downstream systems and processes, enabling prompt remediation when necessary and in turn, ensuring data integrity.
It’s important to note that while we’ve illustrated this with a CSV to Hive scenario, our approach is versatile and adaptable to virtually any data integration combination with minimal adjustments. This flexibility highlights the broad potential of our solution across different use cases.
What’s more, thanks to the final event table, we can easily embed the drift information into existing monitoring or alerting apps or ecosystems.
If you would like further information about this solution or other NiFi integration projects, don’t hesitate to contact us – we’ll be happy to help!
