
21 Sep 2023 Exploring Data Fabric for Modern Data Architectures
Nowadays, organisations are grappling with the challenges of managing and governing vast amounts of data from a wide range of sources. Traditional data architectures, such as the enterprise data warehouse (EDW), often struggle to keep up with growing complexities, making it difficult for businesses to derive actionable insights and make informed decisions.
The emergence of paradigms such as the Data Lakehouse has revolutionised data architecture, as you can see in our blog series Data Lake Querying in AWS. This paradigm combines the scalability and cost-effectiveness of data lakes with the performance and structure of data warehouses.
Another paradigm that has caught everyone’s attention is the data architecture pattern known as Data Mesh, which we have covered in this blog post and this YouTube video. Data Mesh is a promising, decentralised self-service data architecture that arranges data by business domains, focusing on the fast delivery of top-quality reliable datasets (known as data products) by their owners – the domain teams.
Although the number of Data Mesh adopters is growing exponentially, many of them are running into difficulties, and the reason behind this is the fact that Data Mesh is not only a data architecture, but also an operational structure. Companies are having a tough time trying to restructure their operational organisation in domains (even identifying their domains themselves is a challenge), and moreover, moving from a traditional centralised architecture to a decentralised system can be highly complex and unsuitable in some cases.
Nonetheless, a transformative concept that promises to overcome these hurdles has recently been gaining strength – Data Fabric. In this blog post, we will explore the concept of Data Fabric from our ClearPeaks perspective, examine its role in addressing data architecture problems, see how different tech vendors are adopting it, and finally look at how it synergises with Data Mesh.
Data Fabric
Data Fabric is a data architecture design concept, both centralised and decentralised, that aims to provide a unified view of all your enterprise data on top of all your multiple and separate data sources, regardless of whether they are on-premise, in the cloud, or hybrid. Data Fabric leverages metadata analysis to discover business-relevant relationships between data assets and thus promotes more rapid and efficient actions.
Whilst the term itself was first coined and defined by Forrester Research, there are many definitions now on the internet, and they are not always the same! Nevertheless, today we are going to run through its main principles, based on our real-life experiences of building and using Data Fabric with our customers.
The three main elements of Data Fabric are the data integration layer, AI-powered data governance, and metadata activation. Although these principles overlap, each one has a distinct focus. Let´s take a look at them!
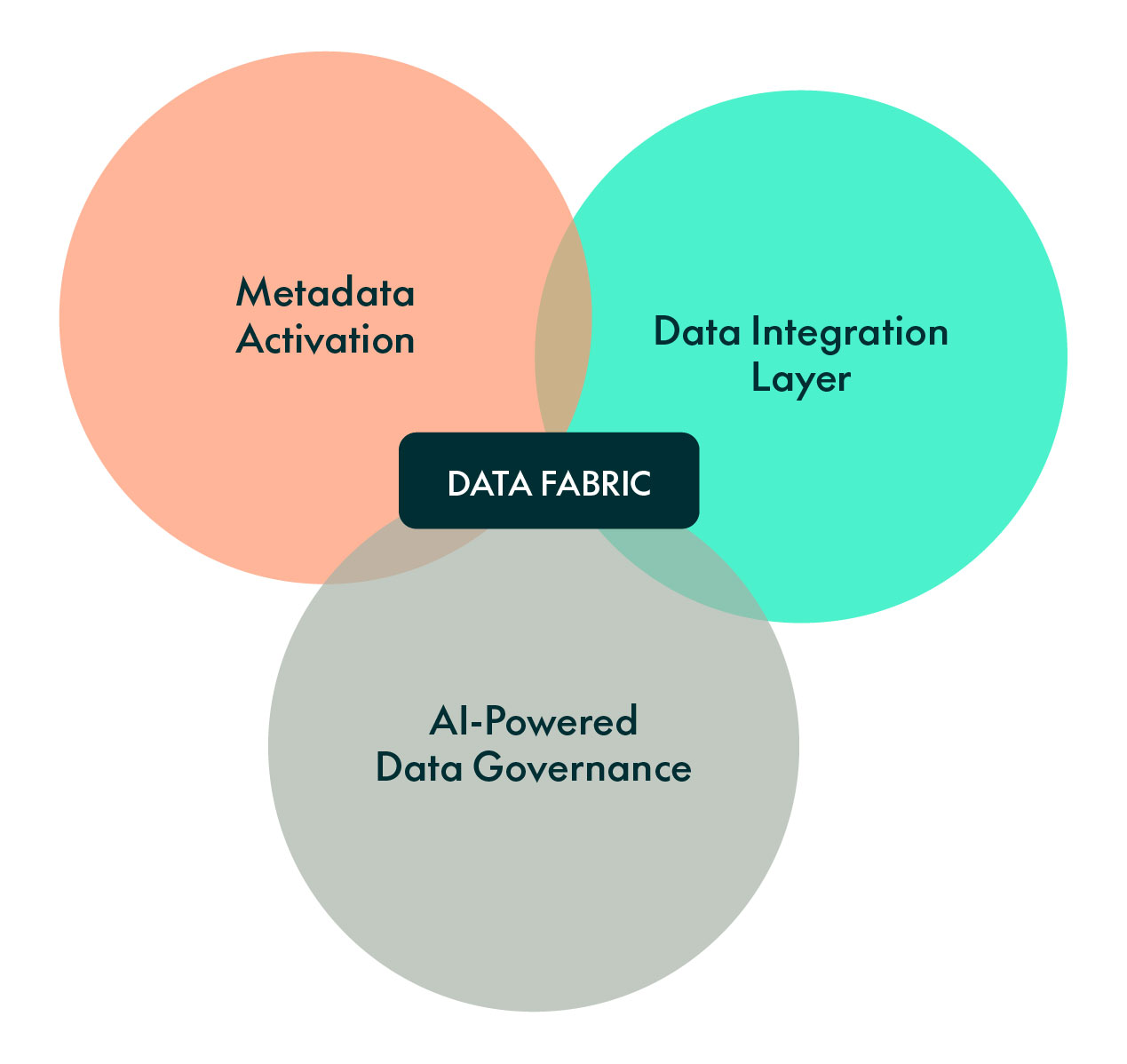
Figure 1: Main principles of Data Fabric
Data Integration Layer
The data integration layer provides the data consumers with a unified entry point to access data from various sources, regardless of the data type (structured, unstructured, or semi-structured) or the source location (cloud, multi-cloud, on-premise, or hybrid). This layer aims to minimise, or even eliminate, the need for data movement. And by minimising data movement, organisations can save time, reduce complexities, comply better with PII data requirements, and ensure real-time or near-real-time access to data.
The layer also encompasses the technical functionalities for ingesting data (when data movement is unavoidable) and for processing it in both batch and streaming modes, incorporating AI capabilities. Additionally, it includes the mechanisms for orchestrating all associated tasks, along with the actual data stores being used.
Adopting DataOps principles, which treat data infrastructure and pipelines as code, further enhances the integration layer. DataOps is a must for any modern data architecture as it promotes automation, version control, and collaboration, guaranteeing reliable and scalable data integration processes.
Data Fabric’s integration layer can play a pivotal role in creating data markets, where high-quality data assets are exposed and made discoverable for consumption by users with varying technical expertise. This democratises data access and promotes collaboration across the organisation, fostering a self-service data-driven culture enabling more users – data citizens – to make decisions based on data. The concept of data democratisation is gaining traction due to the increasing demand for the ability to manipulate fresh, quality data without advanced tech skills (this is why no-code tools are also on the rise) and then analyse it to make business decisions.
The integration layer provides a unified view for data that can be distributed across multiple systems cohesively, allowing federated access to data at source with minimal data copies. We predict that in some years ML and AI will be powerful enough to automatically access and virtualise data based on user queries, but in the meantime, Data Fabric has to rely on more manual approaches. There are various techniques to design and implement the integration layer, and two in particular stand out: data lakehouses and data virtualisation.
Data Lakehouses
The concept of the data lakehouse architecture aligns perfectly with the needs for the integration layer in Data Fabric because it’s designed to accommodate all types of data from diverse sources. Data movement may still take place as it´s common for companies to bring all their data to their data platforms. There are vendors that offer solutions that fit this description, as we have seen in our blog posts about data lakehouses, but in this post we want to highlight just two of them: Microsoft and Cloudera.
Microsoft recently released Microsoft Fabric, a promising end-to-end cloud-based analytics solution encompassing everything that you´d expect from a modern data platform, with OneLake to unify data access and Purview as their AI-powered data governance tool. You can find more information about Microsoft Fabric in our blog post Microsoft Fabric: First Contact – Evolution or Revolution?. While it may seem like a potential Data Fabric solution, we’ll need to be patient and monitor its adoption and maturation over time to make a more informed assessment.
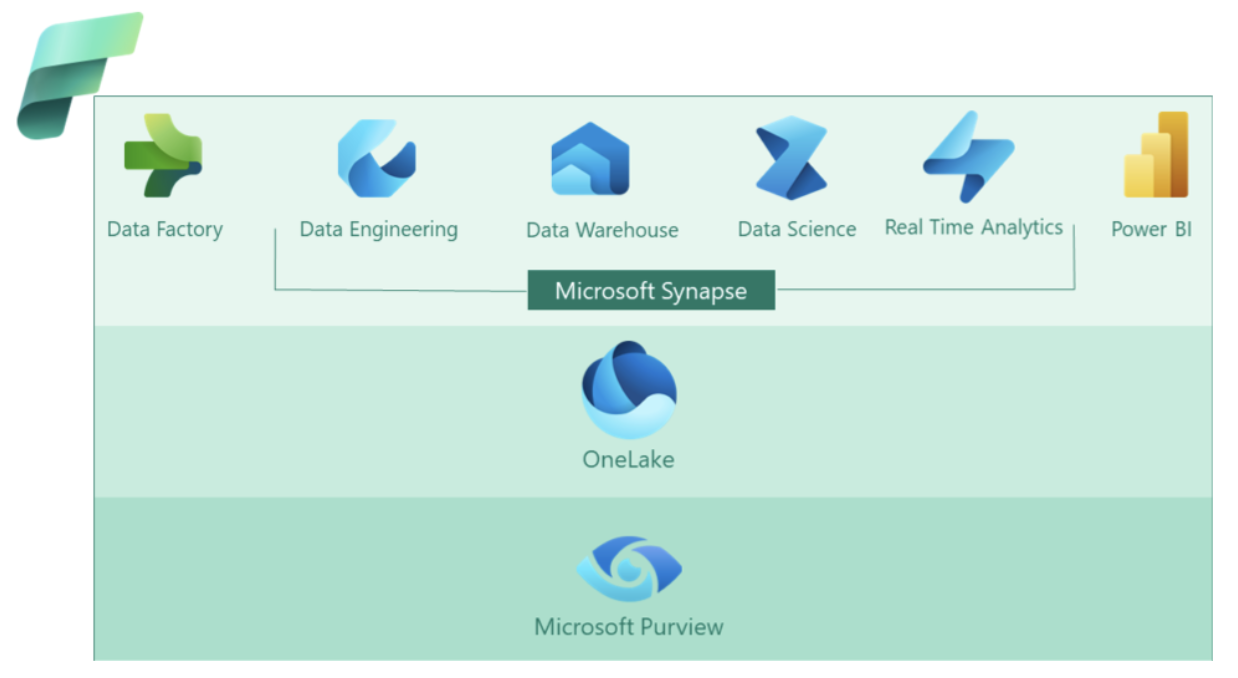
Figure 2: Data Fabric in Microsoft
Cloudera, on the other hand, offers the only product on the market that seamlessly works multi-cloud and on-premise, a convenient solution for the integration layer in Data Fabric. Moreover, Cloudera components offer solid API interoperability, being able to leverage DataOps to the fullest, allowing communication between all the pieces as well as data sharing between external and internal users. We have talked about Cloudera extensively in our blog and webinars.
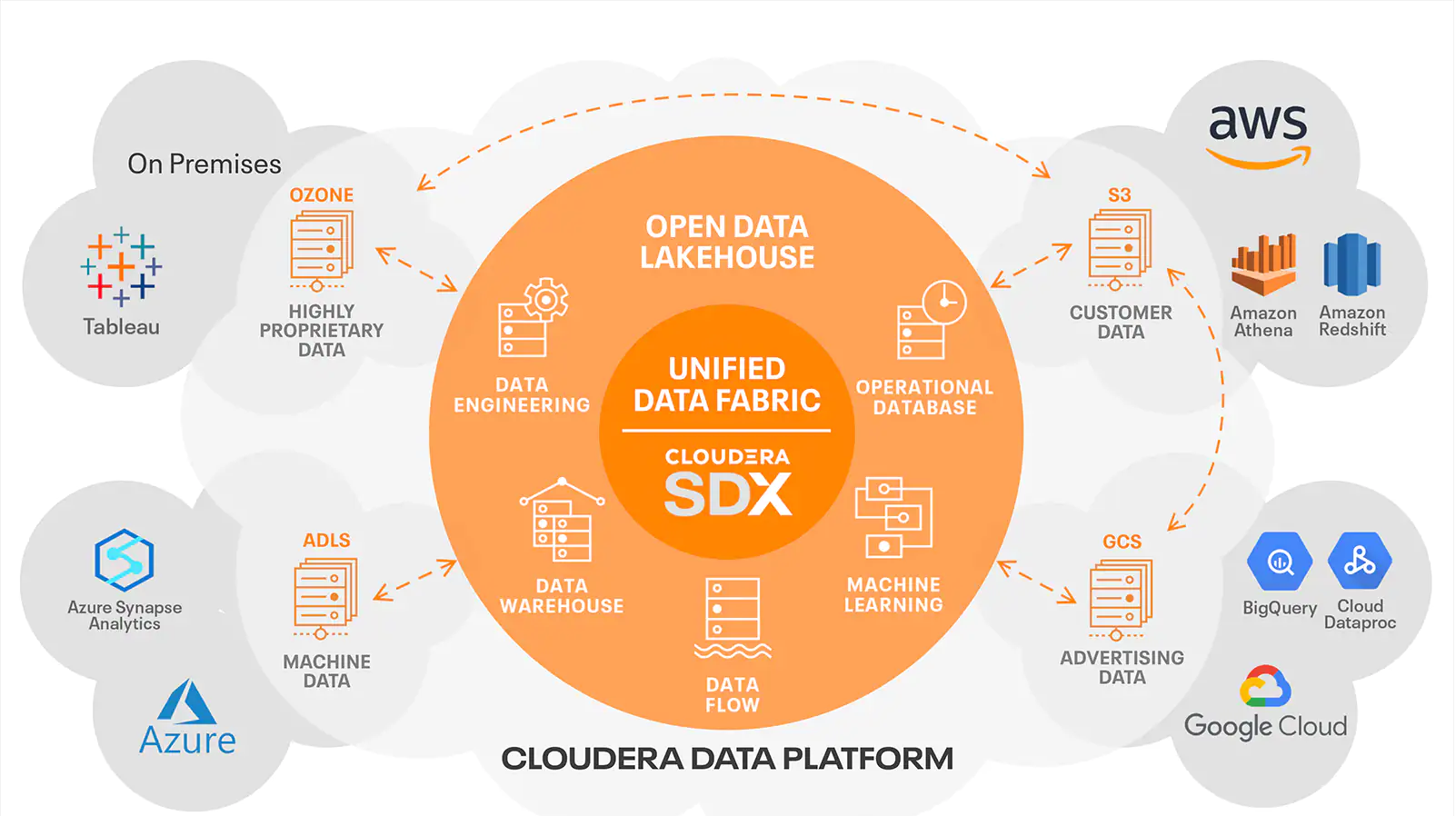
Figure 3: Data Fabric in Cloudera
Data Virtualisation
Data Virtualisation is a concept that we have already covered in our blog post Data Virtualisation. In short, it is a data integration technology that aims to provide a unified, abstracted, and encapsulated view of the data coming from a single or heterogeneous set of data sources, while the data remains in place (if there is data movement, primarily for faster access, it is typically automated). This approach is consistent with the core concept of Data Fabric, which is to enable seamless data access without the need for extensive data replication or movement.
There are few vendors that provide such a data virtualisation approach, and the one we want to share with you is Dremio. We have already looked at Dremio in previous blog posts like Massive Survey Data Exploration with Dremio or Data Lake Querying in AWS – Dremio, where we saw its potential for data virtualisation. Leveraging both physical and virtual tables, it is possible to create a Data Fabric integration layer with minimal data movements. To get faster results, Dremio uses Reflections, technically copies or aggregations of the data, whose management is semi-automatic.
Overall, the integration layer has to provide an abstraction layer for the users to access data in the format they want, regardless of where it comes from. Business users simply want accurate, up-to-date, and trustworthy data, so going directly to the source removes the need for frequent refreshes. This is why data virtualisation is often considered the easiest approach, but it comes with its own challenges, the most obvious being the potential performance impact on operational systems. In many cases, organisations find data lakehouses to be a more convenient solution, even though it may not be as efficient at minimising data duplication.
AI-powered Data Governance
Data governance is a critical aspect of any data architecture, focusing on ensuring data quality, security, privacy, compliance, and proper usage across the organisation. A key component is the data catalogue, which serves as a centralised repository of metadata, providing comprehensive information about the organisation’s data assets, including data sources, schemas, definitions, lineage, and access permissions. It enables users to discover, understand, and trust the available data, whilst handling personal and sensitive data appropriately.
With Data Fabric, AI and ML technologies can enhance the data catalogue by automating metadata management processes. Their algorithms can analyse and classify metadata, improve data discovery, make recommendations, enable data lineage tracking, and relate key business terms to one another, contributing to effective data governance.
Needless to say, this doesn´t happen by magic, and behind these capabilities lies a technology that both stores metadata and enriches data with semantics: knowledge graphs. A knowledge graph in Data Fabric serves as a connective, semantic layer that enhances data integration, discovery and understanding, empowering users to navigate and to explore data in a more meaningful and contextual manner, enabling advanced querying, analysis, and decision-making. By leveraging the rich representations and relationships captured in the knowledge graph, organisations can unlock the full potential of their data assets and benefit from innovative data-driven insights.
In the following section we will see how AI and ML can be maximised in Data Fabric.
AI and ML in Data Fabric
AI and ML are becoming increasingly popular nowadays – especially with the recent “AI boom” starring generative AIs such as ChatGPT or Midjourney – and it is no wonder! Not only they are revolutionising our conventional understanding of AIs, but they are also making a profound impact on the data sector. Recently, AI and ML have been used to create recommendation engines for personalised shopping, to build AI-powered assistants, to analyse patterns for fraud prevention… in short, to improve a company’s products. In these emerging data architecture paradigms, with concepts like data products and active metadata management, AI and ML are crucial to enhancing the data platform itself.
Here at ClearPeaks we offer multiple possibilities to exploit AI and ML in a modern data platform. Let´s look at some of the benefits we believe they can bring to your enterprise data platform:
- Intelligent Metadata Management: AI algorithms can automatically analyse and classify metadata within the Data Fabric. This enables better data discovery, understanding, and context-driven recommendations for data use.
- Data Exploration and Query Assistance: AI-powered recommendation systems can assist users in formulating complex queries, suggest relevant tables, and provide insights based on historical usage patterns, accelerating data exploration and enabling users to obtain valuable insights more efficiently.
- Natural Language Processing (NLP) Interfaces: NLP technologies enable users to interact with the Data Fabric using natural language queries or conversational interfaces, making data access and exploration more intuitive for non-technical users, and encouraging a broader adoption of data-driven practices. This will also reduce the level of data literacy required to understand the different components of the platform, as most businesses users will simply access this interface to interact with it.
- AI-Generated Insights: AI algorithms can analyse data within the Data Fabric to uncover patterns, trends, and correlations that may not be immediately apparent to users. These insights can be surfaced through automated reports, anomaly detection, or predictive analytics, improving human decision-making processes.
- Analyse Your Assets (Datasets, Tables, Dashboards): AI- powered systems can enable users to identify popular assets for recommendation and suggest related assets that are commonly used together, scale resources based on access trends, and automatically archive or delete unused assets. They can also notify the owners of relevant changes in their assets to avoid corruption or breakage.
These are only a few of the possibilities AI can unlock in your data platform. There are, of course, others – and we are sure that as AI continues to mature and becomes prevalent within organisations, more and more possibilities will emerge.
Metadata Activation
Metadata is a key component in every data platform as it provides critical information about the data assets within the system. Metadata is a broad concept, and its classification varies depending on its intended purpose. Below you can see the different types of metadata:
- Technical Metadata: Technical metadata describes the technical characteristics of the data, such as data types, field lengths, data formats, storage location, and database schemas. It helps to understand the structure and technical properties of the data.
- Business Metadata: Business metadata captures the business context and meaning of the data. It includes business glossaries, data definitions, business rules and data ownership information, helping users to understand the relevance and meaning of the data in specific business contexts.
- Operational Metadata: Operational metadata pertains to the operational aspects of the data, such as data lineage, data transformations, data quality metrics and data processing workflows, it provides insights into how data is derived, transformed, and processed within the system.
- Social Metadata: Social metadata encompasses user-generated information, such as user comments, ratings, and usage patterns. It helps users assess the reliability, relevance, and popularity of the data.
Apart from these, we can also differentiate two other types of metadata, depending on their generation:
- Passive Metadata: This refers to static or predefined metadata that is captured and stored in a centralised repository or data catalogue. It includes information about data sources, data schemas, definitions, data types, and other descriptive attributes. Passive metadata is typically created during the initial ingestion or registration of data assets in the platform, and it provides a foundational layer of information that helps users to understand the basic characteristics of the data. Usually, users in roles like data stewards are in charge of populating this metadata by providing business descriptions and glossaries in the data catalogue.
- Active Metadata: Active metadata, on the other hand, is dynamic metadata that is generated, updated or augmented in real time during data operations, interactions, or transformations within the Data Fabric. It captures information about data lineage, transformations, usage patterns and other operational aspects of data, and is continuously evolving, reflecting the current state and context of the data within the Fabric.
Although most companies understand the importance of becoming data-driven, many often exploit only the data per se and overlook the metadata. As we have seen, metadata comes in various forms, and analysing it can be a game-changer as it is essential for data discovery and comprehension. Some companies are starting to realise this and are actively gathering metadata while populating their data catalogues with glossaries and business descriptions.
However, passive metadata is not actively updated or modified during data operations or interactions, but remains static unless explicitly modified or updated by administrators or metadata curators. The need for human intervention makes analysis slow and sometimes inaccurate, so rather than waiting for users to manually update metadata, Data Fabric aims to use ML to extract the metadata from the knowledge base mentioned before, converting passive metadata into active metadata, a process known as Metadata Activation. Active metadata enables users to understand the most recent state of the data, to track changes, and to assess the reliability and freshness of the information.
Metadata activation leads to expedited, well-informed, and, in certain instances, entirely automated data access, classification, and sharing.
By harnessing the integration layer, AI-powered data governance practices and metadata activation techniques, Data Fabric can provide organisations with a comprehensive and efficient data architecture. This enables seamless data integration, ensures data governance and trust, and empowers users to leverage data assets effectively for insights, decision-making, and innovation.
Data Mesh and Data Fabric
We didn’t want to miss the opportunity to talk about Data Mesh in this blog post; whilst some specialists consider them mutually exclusive, in our opinion they could be complementary.
Although both are data architectures for data management approaches, Data Mesh is based on distributing ownership by domains while this is not compulsory in Data Fabric – although it´s possible. This is a key difference that makes Data Mesh a tricky approach for many companies, especially the ones lacking data literacy at executive levels, as it requires an organisational and operational restructuring along with a robust data maturity and culture. Data Fabric´s flexibility can make its implementation easier than Data Mesh.
Despite these differences, Data Mesh can synergise with Fabric: its knowledge graph, for example, besides being used for semantic purposes, could be used to identify your business domains and subdomains, further enhancing your domain ownership in a Mesh environment.
Moreover, as data virtualisation can be implemented in a decentralised manner, it can become a tool to create data products. The integration layer could include a virtualised data market where users can access and generate data products, with an automatic application of security and governance based on domains.
What´s more, even though Data Mesh does not specifically focus on metadata, incorporating the metadata activation methods explained in this blog, along with the AI and ML use cases mentioned, could significantly improve its implementation, creating a sturdier and more democratised data platform.
Despite being in its early adoption stage, many companies are wondering about the future of Data Mesh and how it might evolve. We think that a combination of both approaches – Mesh and Fabric – could be the way to go. However, considering the rapid evolution of the sector and the constant emergence of new technologies, the scenario might be completely different a few years from now.
Conclusions
As we have seen in this blog post, Data Fabric is an interesting data architecture design based on data virtualisation or data lakehouses to create an integration layer that reduces data movement regardless the number of sources, focusing on metadata activation to create a unified view with AI-powered data governance. Moreover, its synergy with Data Mesh allows us to harness its principles to further improve our current Mesh implementation.
For these reasons, we think Data Fabric is a great approach for most companies that are struggling with their current architectures. However, remember that there is no one-size-fits-all solution – each data platform needs to be customised for a specific organisation and use case, requiring forethought and careful planning. At ClearPeaks we are experts at designing and implementing data architectures that fit your business cases like a glove, so don’t hesitate to contact us!
