30 Jan 2025 Exploring Cloudera Data Catalog
Data Governance (DG) is increasingly becoming a cornerstone for all data-driven organisations. As highlighted in our previous blog posts, principles such as Data Quality, Data Catalogs, Master Data Management, and DevOps are gaining significant prominence. The buzz around DG is arguably second only to the excitement surrounding Generative AI.
It comes as no surprise, then, that most data-focused technology vendors are investing heavily in DG tools and partnerships. Cloudera is no exception, recently introducing a new service within Cloudera Data Platform (CDP) to strengthen its capabilities in this domain: Cloudera Data Catalog.
Whilst we’ve already covered data catalogs in another blog post, today we’ll explore Cloudera’s own catalog, simulating a simple use case, showcasing its features, and explaining how it can enable the implementation of DG practices in your CDP.
What is Cloudera Data Catalog?
According to Cloudera’s own documentation, the data catalog “is a service within CDP that enables you to understand, manage, secure, and govern data assets across the enterprise.”
Cloudera already had a DG tool in its CDP suite: Apache Atlas, an open-source tool that has been part of the CDP runtime for a while now, enabling things such as data cataloguing, exploration, lineage and tagging for most of the CDP services. You can read our blog post about it here.
Cloudera Data Catalog takes it to another level by providing additional features, an improved user experience, and seamless integration with the Data Services product. It is available by default for both private and public cloud environments.

Figure 1: Data Catalog on the Cloudera Data Services home page
Those familiar with Atlas will surely recognise some of its classic features embedded in the new data catalog, alongside the additional capabilities like tools for creating and managing datasets and assets, as well as the ability to run profilers. These features will be explored in detail in the following sections.
Exploring the Cloudera Data Catalog
On opening Cloudera Data Catalog, the first page we see is the Dashboard, offering a comprehensive overview of all data from the catalog perspective. Compared to the Atlas interface, this dashboard is significantly enhanced and better aligned with the broader CDP Data Services, reinforcing the impression that it is a core component of the platform rather than an add-on. The dashboard displays key metrics and metadata related to data lakes, assets, and profilers, including details on profiled assets. At the bottom, it features convenient links for performing basic actions, such as a tile to Manage Datasets:
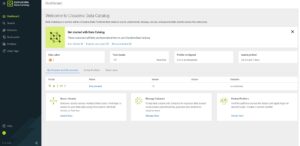
Figure 2: Cloudera Data Catalog home page
But what are assets and datasets in Cloudera? And what is a profiler?
A data asset is “a physical asset located in the CDP ecosystem such as a Hive table which contains business or technical data”. It is, essentially, what used to be called an Atlas Entity. Assets are automatically detected by the data catalog and are “created” when their corresponding physical entity is created in the cluster.
A dataset is a collection of assets. This is an entirely new concept introduced in the data catalog, but not in Atlas. Datasets “allow users of the data catalog to manage and govern various kinds of data objects as a single unit through a unified interface”. When you create a dataset you can assign existing assets to it, thus streamlining management and governance.
Finally, a profiler is another new addition to the data catalog. A profiler is a job that gathers several basic characteristics of an asset, such as distribution, quality, min/max/mean/null metrics, sensitivity, etc. It can run at regularly scheduled intervals, and can fetch information from Ranger audit logs, Atlas metadata, and Hive, as we will see later.
To explore these exciting features in detail, let’s dive in a demo use case: we are going to use this dataset (shown below) containing churn-related information about a telecom provider, including attributes such as churn reason, account length, payment method, contract type, monthly and total charges, amongst others. As the designated data owners of the churn dataset, our goal is to thoroughly explore, understand, and clean it. This will ensure we can maximise its value for churn prediction and, ultimately, churn prevention.
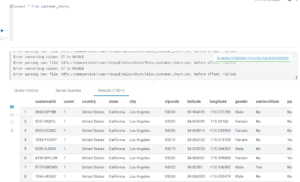
Figure 3: A sample of our churn dataset
Note: our small demo was done using the on-prem version of Data Catalog on ECS 1.5.3. Most looks, features and elements should be similar in the public cloud version.
Data Discovery
One of the standout features of Cloudera Data Catalog is Data Discovery, which enables seamless navigation and search capabilities across your cluster. Using the Search tab, you can locate a wide range of assets, including Hive tables, databases, columns, HDFS paths, HBase tables, and more.
To start our data owner tasks, we click on the Search tab and search for assets containing the term “churn”. Various relevant items are retrieved, such as Hive columns and HDFS locations, where this data is likely stored:
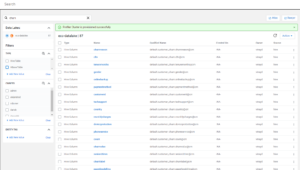
Figure 4: Searching for churn data
With the full list of results available, we apply a filter for Hive tables and locate a table named customer_churn. This appears to be a promising asset, so we click on it to explore further. This opens up the Asset Details view, where we can see a variety of asset properties, most which correspond to typical Atlas Entity properties, like comments, descriptions, classifications, terms, and lineage:
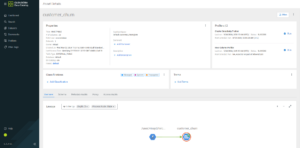
Figure 5: Exploring our Asset
Amongst the new features available, we can see the connected profilers (if there are any) and, in the Lineage pane, options to explore Policy and Access Audits, made possible through integration with Apache Ranger; we’ll delve into these aspects later.
For now, we examine the schema and confirm that this is an asset that we want to include in our churn dataset. The next step, then, is to create this dataset.
Creating a Dataset
As we mentioned, the data catalog introduces several new entities, the most important of which is the dataset, a feature that allows us to group all related data assets into a single repository, facilitating collaboration, data discovery, and data exploration.
To add a new dataset, we navigate to Datasets on the Cloudera Data Catalog homepage and then click on Add Dataset. We’ll name our dataset cp-telco, then select the data lake that it will be linked to, and click on Next:
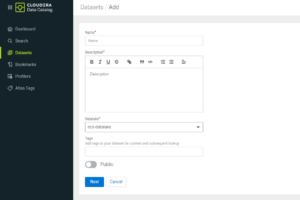
Figure 6: Creating a new Dataset
On the next page, we click on Add Assets to add assets to our dataset. Here, we search for our customer_churn table, select it, add it to our dataset and finally confirm the creation of our dataset.
Now we have a dataset that we can use to explore our churn data and, if necessary, we can add more assets to it:
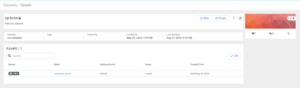
Figure 7: Our first Dataset
Exploring the Dataset
Now that our dataset has been created, we can explore its assets, add new ones, and collaborate seamlessly with fellow team members. On the right-hand side there is a dedicated comments box where we can add notes about the dataset or provide feedback based on our exploration. We can also “like” the dataset here:
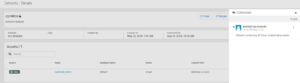
Figure 8: Dataset collaboration
In the same tile, we can also bookmark the dataset to save it in our Favorites. All bookmarked datasets are available in the Bookmarks section, accessible from the menu on the left. To streamline access to our dataset for everyday tasks, we’ll bookmark it:
Figure 9: Bookmarks
From the Dataset view, we can conveniently navigate back to the asset’s Details page, revisiting the content viewed just a moment ago. As owners of the churn dataset, after adding the customer_churn table, we assigned Ranger policies to it, so now, if we click on the Policy tab, we can review the newly created Ranger policies. If there are any tag-based policies, they are also available here. We can even navigate to the actual Ranger policy page by clicking on the ID on the left:

Figure 10: Asset policies
At the top-right of the page we can find some information about the profilers; let’s take a closer look.
Profiling our Data
Data Profiling is the systematic process of analysing datasets to produce high-level summaries. In the Cloudera Data Catalog, “profilers create metadata annotations that summarise the content and shape the characteristics of the data assets (such as distribution of values in a box plot or histogram)” according to the official documentation.
The Hive Column and the Sensitivity profilers are particularly useful to us, respectively providing summary statistics at the Hive column level and detecting any sensitive information (based on common practices and widely used regulatory standards such as HIPAA, PCI, etc.).
For us, as data owners, this is a strong starting point to analyse our asset, so let’s start by running the Hive Column profiler. Once completed, we can navigate to the Schema tab where we can expand each column to see its profiled data (this is only possible after running the Hive Column profiler at least once). With this, we can perform a quick initial analysis. For example, we can see that most of our customers are on a month-to-month contract:
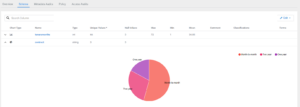
Figure 11: Hive Profiler on a categorical field
If we click on the churnreason field, a different plot appears, revealing that most customer churns are attributed to the price being too high. These are valuable insights to identify key areas of concern:
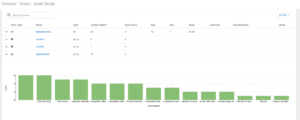
Figure 12: Profiled summary of the churn reason
What’s more, for metrics, we can see that max, min, and mean values are displayed. By accessing the column details, a boxplot is available, enabling a detailed analysis of the distribution of total charges across customers, helping us to better understand patterns and anomalies in customer spending behaviour:
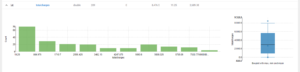
Figure 13: Profiled metric: total charges per customer
Last but not least, this view allows us to detect potential issues within the dataset. For instance, we can see that columns such as zipcode or churnvalue are incorrectly classified as integers. The profiler generates histograms for these fields and calculates max, min, and mean values. However, this is clearly inappropriate—after all, we don’t add up zip codes, do we? As data owners it is our responsibility to report such issues to the relevant data engineers and the data custodian for correction.
Sensitivity Profiler
Another important feature is the Sensitivity profiler, particularly useful for automatically generating tags which can then be used to implement policies, like tag-based rules.
For example, let’s imagine that we want to add a policy ensuring that only specific privileged users can access Customer ID values. This column is typically found in our data lake, so it is crucial to detect it and mask it dynamically.
Unfortunately, none of the default Sensitivity tags corresponds to our Customer ID format. However, we can create a new tag by clicking on Profilers > Tag Rules > New. Here we create a new rule that we’ll call customerid, and we enter the required regular expression, as we can see below:

Figure 14: Custom Sensitivity tag
We confirm that the rule works as expected by testing it; once confirmed, we save the rule, return to our asset, and run the Sensitivity profiler. After the profiling process is complete, we revisit the schema, where we can check that the dp_customerid tag has been successfully assigned to the relevant column:
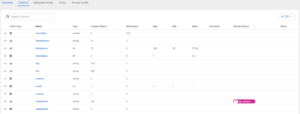
Figure 15: Customer ID tag assigned by the Sensitivity Profiler
This Classification tag is also visible if we drill down to the column asset. At this point, we can use it in a Ranger tag-based rule by setting the following details:
- TAG: dp_customerid
- Groups/Users: those who should not see the full value of this column
- Permissions: HIVE
- Masking Option: partial mask, showing the first 4 characters
To ensure the rule works correctly, we add our own user to the list for testing purposes. Once verified, we save:
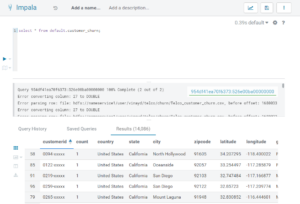
Figure 16: Ranger rule based on Data catalog tags
If we go back to our Policy tab in the asset, this rule is now also visible:
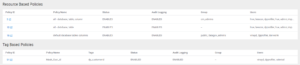
Figure 17: Tag-based rules in the Policy tab
As a final step, we can enable a Ranger audit profiler to generate additional metrics related to access patterns for our asset. Once the profiler has run, the updated information becomes available at the bottom of the Overview tab on the Asset page. This data provides valuable insights, such as the top users accessing the asset, request trends, helping to identify usage patterns, an overview of user activity, including the most relevant users, the typical actions performed on the asset, and the percentage of denied access attempts. A high percentage of denied access attempts could indicate one of two things – additional users might require access to this data, or more critically, these could be malicious attempts to access the asset:
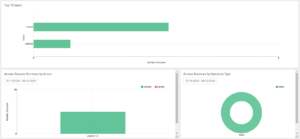
Figure 18: Ranger audit metrics
Conclusion
In this blog post, we’ve explored the capabilities of Cloudera Data Catalog by stepping into the role of a data owner at a telco company. Our objective was to define a churn data asset and to perform an initial exploration of the available data.
We saw how Cloudera Data Catalog can be a powerful tool for such tasks, and how it seamlessly integrates with the rest of your CDP cluster, offering the familiar Apache Atlas features in a revamped way, plus many more useful capabilities such as dataset collaboration and profilers.
For organisations utilising a CDP-based data lake, Cloudera Data Catalog presents an excellent solution for implementing Data Governance. It is effectively included in your Data Services or available by default in public cloud environments.
From the four DG principles that we mentioned at the beginning (Data Quality, Data Catalog, MDM, DevOps), this new addition to the Cloudera stack covers the catalog (as the name implies) but not the others. Fortunately, here at ClearPeaks we’re always one step ahead, and we’re already working on some ideas to fill this gap, and in our next blog post we’ll present our custom framework for Data Quality within Cloudera, so stay tuned! In the meantime, if you’re looking to unlock the full potential of your Cloudera environment or need assistance implementing robust DG strategies, our skilled team is here to help. Get in touch!
