
11 May 2023 DataWash: An Advanced Snowflake Data Quality Tool Powered by Snowpark – Part 1
The increasing importance of data in modern businesses makes it absolutely necessary to ensure its quality and reliability. Dirty data can lead to incorrect insights, faulty decisions, and ultimately financial losses. That’s where DataWash comes in, a data quality tool that provides a comprehensive set of modules to detect and correct data issues in an automated, efficient way.
DataWash monitors your data with complex business rules and warns you as soon as an error appears. By automating the data cleaning process, DataWash can reduce the time and resources needed to achieve high-quality data, improving the accuracy and consistency of analytical results.
In this mini-series of 2 blog posts, we will explore its features and benefits and demonstrate how it can be used to improve data quality in Snowflake. In this, the first part, we will explore the features, advantages, and use cases of DataWash and compare it to other popular solutions on the market. We will also provide some tips and best practices to get the most out of the tool and so ensure the quality of your data.
Whether you’re a data analyst, data engineer, or business stakeholder, this mini-series will provide valuable insights into how DataWash can help you maintain high-quality data in Snowflake. And after this, stay tuned for the second blog post in the series, where we’ll dive deeper into technical details and customisation options. Let’s get started!
Data Quality
What is Data Quality?
Data quality is a critical aspect of managing information in organisations. It involves ensuring that data is accurate, complete, consistent, relevant, and timely, and that it meets the needs of its intended use. In today’s data-driven world, the quality of data has a significant impact on your organisation’s success.
Good data quality can lead to informed decision-making, improved efficiency, compliance with regulations, and increased customer satisfaction. On the other hand, poor data quality can result in incorrect insights, misinformed decisions, wasted resources, and a lack of customer satisfaction. It is important for organisations to prioritise data quality and invest in the processes, tools, and resources needed to maintain high-quality data.
Here’s a more detailed explanation of each of these key aspects of data quality:
- Accuracy: The extent to which data is correct, precise, and free from errors, a fundamental data quality dimension that is critical for ensuring that data is reliable and trustworthy. Organisations should prioritise accuracy when assessing and improving the quality of their data, in order to support informed decision-making and better business outcomes.
- Completeness: The extent to which data contains all the necessary information to meet the specific needs of the user or organisation. Complete data is considered to be of high quality because it provides a full and comprehensive picture of the subject matter. In other words, completeness refers to the presence of all the required data elements and attributes in a dataset.
- Uniqueness: Is a characteristic most often associated with customer profiles; a single piece of information could be all that separates your company from winning an e-commerce sale and beating the competition. Greater accuracy in compiling unique customer information, such as each customer’s associated performance analytics related to individual company products and marketing campaigns, is often the cornerstone of long-term profitability and success.
- Consistency: The extent to which data is uniform and follows a defined set of rules or standards. Consistency ensures that data is comparable across different sources and time periods, whereas inconsistent data can lead to mistakes and impaired decision-making.
- Timeliness: This refers to how up to date the data is. For example, a customer’s information should be updated in real time to guarantee accuracy and relevance.
- Validity: This concept refers to information that fails to follow specific company formats, rules, or processes. For example, many systems ask for a customer’s birthdate, but if the customer does not enter their birthdate using the proper format, the level of data quality is automatically compromised. Nowadays, many organisations design their systems to reject birthdate information unless it is input using the correct format.
- Conformity: The degree to which data adheres to predefined standards or guidelines. Conformity ensures that data is consistent, accurate, and reliable. For example, if a company has a defined data format, then data should be collected and stored in that format. Non-conformance can lead to errors, inconsistencies, and redundancies in the data, which can result in poor decision-making, amongst other issues.
- Integrity: Is the data reliable and trustworthy? For example, if your database has an email address assigned to a specific customer, but the customer deleted that account years ago, then there’s an issue with data integrity.
- Precision: This is critical when dealing with quantitative data, such as numerical values. For instance, in financial data, precision is essential to ensure that calculations are accurate and that financial statements are error-free. Precision can be affected by various factors such as measurement errors, rounding errors, or sampling errors.
- Currency: How accurate the data is compared to the entity’s state in the real world. It is an important data quality dimension, because outdated data can be inaccurate, irrelevant and can hinder effective decision-making. Currency is particularly important for data that is time-sensitive or subject to frequent changes, such as financial data, stock prices, or inventory levels.

Figure 1: 10 ways to determine data quality.
(Source: https://icedq.com/6-data-quality-dimensions/)
Why Does Data Quality Matter?
Data quality is of crucial importance for organisations of all sizes and across all industries. Here are some of the key reasons why:
- Better business decisions: High-quality data provides organisations with accurate and reliable information to support informed decision-making, leading to improved efficiency, cost savings, and better outcomes overall.
- Improved customer satisfaction: Data quality directly affects the customer experience. Poor data quality can result in incorrect information being given to customers, causing potential frustration and dissatisfaction. On the other hand, high-quality data can help organisations to provide accurate and timely information to customers, leading to greater trust and loyalty.
- Compliance with regulations: Many industries are subject to regulations that require them to maintain certain data quality standards, like, for example, the healthcare industry which must maintain the privacy of patient information, or the financial industry which has to record transactions accurately
- Reduced risk of errors and inconsistencies: Poor data quality increases the risk of errors and inconsistencies in information, which can lead to incorrect conclusions, misinformed decisions, and wasted resources. Maintaining high-quality data helps to reduce these risks.
- Competitive advantage: Organisations that prioritise data quality are better equipped to make better decisions, to respond quickly to changing market conditions, and to remain competitive in a rapidly changing marketplace.
Overall, data quality is a key factor in your success. By prioritising data quality, companies can improve the accuracy and reliability of their information, enhance the customer experience, comply with regulations, and maintain a competitive edge.
Use Case Analysis
Before we introduce our data quality solution, let’s imagine the following use case: CarPartX specialises in the design and manufacture of car parts, and is currently facing issues with data management, which is impacting their business operations. The company’s data is not fully accurate, complete, or consistent, leading to issues with decision-making, process efficiency, and customer satisfaction.
CarPartX stores their data in Snowflake, a cloud-based data warehousing platform, about which you can read more in other ClearPeaks blog posts. Despite the advantages of using Snowflake for data storage, CarPartX is still facing some challenges with data quality, such as:
- Inaccurate data from an API: The API they use to obtain the distances between warehouses for their MRO (Maintenance, Repair, and Operations) inventory optimisation is now providing the distances in miles instead of kilometres. This can cause problems with inventory optimisation, and potentially lead to delays in production or increased costs.
- Broken sensors: One of the sensors in the machine used for predictive maintenance is broken and is now reporting a value of 0 instead of the usual data. This can lead to inaccurate predictions and, in turn, machinery failure or downtime.
- Data duplication: Due to the way their CRM (Customer Relationship Management) works, some new users are being stored twice under different email addresses, leading to communication problems and a potential loss of business.
- Data drift: The newly integrated predictive maintenance solution is starting to misbehave due to data drift in the sensor data, meaning inaccurate predictions and associated problems.
These issues are not isolated cases; sometimes they can even go undetected for a while, making them much harder to fix once found, so it is essential for the company to find a solution that can continuously monitor their data in real time and detect any issues promptly, alerting the relevant person when necessary. Such a solution will allow CarPartX to resolve any issues quickly and prevent any potential harm to their equipment, processes, personnel, and business.
To address these challenges, CarPartX needs to implement a data quality management system that can monitor quality metrics, detect anomalies and data drift, provide alerts and notifications when issues are detected, as well as define the actual data quality rules that need to be implemented and controlled.
They will also have to establish data governance practices to guarantee the accuracy, completeness, and consistency of their data, and also set up the necessary roles and responsibilities, so that data quality is improved in a sustainable, efficient way. This will help the company to improve data quality, to reduce the risk of errors, and ultimately to improve their business operations.
DataWash
What is DataWash?
DataWash is a new and advanced Snowflake data quality tool powered by Snowpark that provides organisations with a comprehensive solution for improving data quality in Snowflake. The tool utilises the Snowflake cloud data warehousing platform and Snowpark, its serverless data engineering platform, to provide a scalable and efficient solution.
DataWash is designed to be fully integrated with Snowflake, making it easy for companies to access their data and perform data quality tasks directly within the Snowflake environment, helping to streamline the whole data quality process and reduce the need for manual cleansing.
It leverages Snowpark’s powerful capabilities to provide a comprehensive suite of data quality modules that can be easily integrated into Snowflake pipelines. With DataWash, organisations can perform various data quality checks, including validation and de-duplication, across their data at scale. By ensuring data accuracy, consistency, and completeness, it helps to increase operational efficiency and reduce those risks associated with poor data quality.
DataWash also provides advanced reporting and visualisation tools, enabling organisations to monitor and track the impact of their data quality initiatives over time, helping them to stay informed about the quality of their data and how to improve it.
In addition to its data quality capabilities, the tool also includes advanced features such as machine learning-based data quality algorithms, real-time data quality monitoring, and automated data quality workflows, offering impressive management of data quality and thus driving optimum outcomes more effectively.
Overall, DataWash is a comprehensive tool that gives organisations a scalable, efficient solution for improving the quality of their data in Snowflake. With its advanced features, integrated reporting capabilities, and support for a wide range of tasks, DataWash helps companies towards better decision-making and reaching their data-driven goals.
How can DataWash Help Solve the Above Use Case?
DataWash can provide a comprehensive solution for improving the quality of CarPartX’s data. Once the root causes have been identified, DataWash can be used to implement solutions, starting with an in-depth analysis of customer data, the setting up of different tests, and finally culminating in a dashboard that helps them to detect potential errors.
Why Choose DataWash and What Makes it Different from Other Data Quality Solutions?
DataWash is a powerful data quality solution that offers several advantages over its rivals:
- Cost-effective: DataWash is a cost-effective solution for CarPartX as it is built on top of Snowflake, which is already being used for data storage. In this way, costs can be reduced and efficiency increased. It’s important to note that it still requires a system to run the Python code that executes the tool’s modules, but this doesn’t necessarily mean a significant investment in hardware or infrastructure. In fact, it can be run on a small virtual machine, cheaper than larger servers or clusters. Furthermore, due to the high cost of state-of-the-art data quality tools, it is worth noting that the cost of using DataWash is much lower than other data quality solutions, making it ideal for small and medium-sized businesses.
- Customisable: DataWash is highly customisable, allowing CarPartX to tailor the solution to their specific needs. This is a major advantage, as other data quality tools often come with a set of predefined features and functionalities that you don’t need. With DataWash, businesses can choose the modules that are relevant to their needs and configure them as required, thus obtaining maximum efficiency and effectiveness./li>
- Advanced Use Cases: In addition to being highly customisable, DataWash is designed to support advanced use cases that are not commonly found in similar tools, making it ready to handle more challenging and demanding scenarios. For example, it can be used to validate large amounts of data, detect and correct errors, and maintain the quality and integrity of data over time. This enables CarPartX to address a wide range of data quality issues and improve the accuracy, completeness, and consistency of their data, as well as making better data-driven decisions.
- Easy Integration: DataWash is fully integrated with Snowflake, making it easy for CarPartX to access and manage their data within the Snowflake environment, streamlining the data quality process and reducing the need for manual data cleansing.
- Modular Architecture: DataWash is designed as a modular solution, with each module dedicated to a specific data quality task, making it highly flexible and customisable: you can choose the modules you need and configure them to meet your specific requirements.
- Powered by Snowpark: DataWash is built on Snowpark, a powerful data processing engine that provides lightning-fast performance and scalability. This means that the tool can handle large volumes of data with ease and process it quickly and accurately.
What is Snowpark and What is it Useful For?
As we explained in one of our latest blog posts, Snowpark is a collection of user-defined functions, user-defined aggregate functions, user-defined types, and procedures, that runs inside Snowflake. Snowpark enables you to perform complex data processing and transformations within Snowflake, without having to transfer the data to another service or tool.
Snowpark is also an open-source project, allowing users to write and run Spark-style computations in Snowflake. It allows developers to use familiar Spark APIs and programming languages like Scala, Java, and Python to build data processing applications in Snowflake’s cloud data platform. It also enables fast and efficient processing, with the ability to scale resources as needed, making it the perfect tool for building large-scale data processing pipelines in Snowflake.
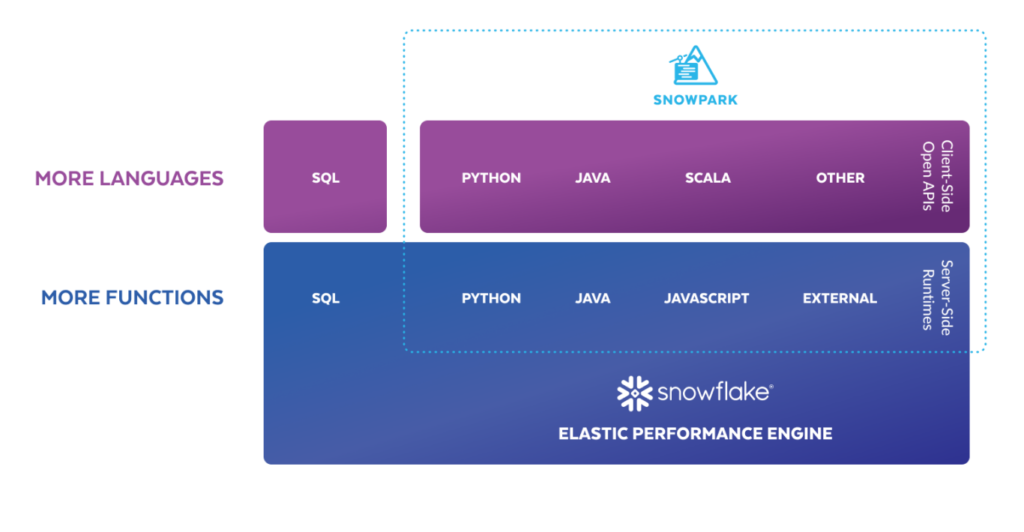
Figure 2: Snowpark programming languages and compute engine.
(Source: https://www.snowflake.com/en/data-cloud/snowpark/)
Snowpark can be useful for many data processing and transformation tasks, such as data quality checks, data standardisation, data enrichment, and data integration, among others. By leveraging Snowpark, you can perform these tasks in Snowflake, greatly improving the performance and efficiency of your data processing pipelines, as well as simplifying the management of your data infrastructure. Additionally, Snowpark can help you to build custom data processing and transformation logic that can be easily integrated into your existing Snowflake environment.
Why Choose Snowpark to Implement DataWash Modules?
One of the main benefits of using Snowpark is that it allows for the creation of highly performant and scalable data quality modules. It also provides several features and optimisations that help to speed up the processing of large datasets, such as data caching and indexing, ensuring that the implemented modules can handle large amounts of data efficiently and with minimal latency.
It should be noted that Snowpark provides a familiar and flexible programming environment for working with Snowflake data. This helps to streamline the development and implementation of data quality modules, as developers can leverage their existing knowledge of Snowflake and Snowpark to build new functionality quickly and effectively.
In addition to its excellent performance and scalability, Snowpark also provides several tools and resources to help with the development and maintenance of data quality modules. This makes it easier for developers to build, test, and debug their modules, and to collaborate with other members of their team to deliver high-quality solutions.
In summary, Snowpark is designed to be easy to use and to integrate with existing data management systems. This makes it a versatile and flexible platform for building custom data quality solutions that can be tailored to meet the specific needs of each customer.
Conclusions
As we have seen here, DataWash is a powerful tool that can help companies to improve the accuracy and reliability of their data. With its modular architecture and ability to run on Snowpark, DataWash offers a flexible and customisable solution for a wide range of data quality needs.
By detecting and resolving issues promptly, DataWash can help organisations reduce the risk of errors and improve data-based decision-making. What’s more, it’s cost-effective, making it an accessible option for organisations of all sizes. With its automated monitoring capabilities, this tool provides continuous monitoring of data quality, guaranteeing accuracy and reliability.
In our next blog post, we’ll take a closer look at how it works and show it in action. In the meantime, don’t hesitate to contact our team of top-quality consultants if you have any questions about what you’ve read, or if you just want to see how data can drive your business forward.
