
25 Ene 2023 Data Governance with Apache Atlas: Introduction to Atlas (Part 1 of 3)
In some of our previous articles we introduced you to the evolving concept of data governance, and reviewed the need for governance in a digital enterprise: in this article we described data governance and saw how it relates to other hot topics like data mesh, the data lakehouse, DataOps, and data observability. In this other blog post, we talked about Azure’s new data governance service offering known as Purview. Today, our focus will be on Apache Atlas.
This is the first in a series of three articles on the topic. In this entry, we’ll start with the basics and introduce Atlas, describing its functionalities, architecture and usage; in the next, we’ll look at Atlas as a CDP service; and finally, we’ll close the series by walking you through some more advanced topics, like creating custom Atlas governance entities.
Introduction to Apache Atlas
We all know that organisations do not rely on a single vendor nowadays, but tend to pick and choose service offerings from multiple vendors. For example, enterprises can adopt databases from Oracle, ETL tools from Informatica, data platforms from Cloudera, and so on, depending on what technology suits them best, from the perspective of both functionality and cost. To be able to build connected governance for all these heterogeneous services, enterprises need something like Apache Atlas.
Apache Atlas is a metadata management and data governance tool, which helps in tracking and managing mutations to dataset metadata. It provides a solution for collecting, processing, storing and maintaining metadata about data objects. It also boasts a rich REST interface for a multitude of operations, such as creating object types using REST calls.
In Atlas, incoming data can be classified as public or private (internal and confidential), and it can also be categorised based on patterns and regular expressions, which can help to determine whether the data belongs to a specific category. For example, classifications can be based on numerous patterns: a phone number, zip code, vehicle number plate, etc.
Atlas is also able to handle metadata about object relationships, thus providing powerful lineage capabilities as well. Data lineage illustrates the origin, movement, transformation and destination of data; and describes and depicts the data lifecycle, beginning with where the data originated, how it progressed through the system(s), what transformations it went through, and where it finally ended up. As seen in the picture below, data lineage is essentially a map of the data journey, showing all the steps along the route:
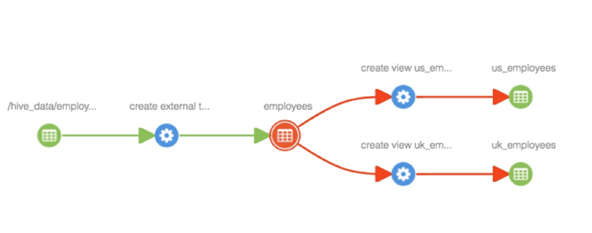
Figure 1: Showing the data lineage of a file
In this example, the employee data is loaded from a Hive database and is then segregated based on location, i.e. us_employees and uk_employees. Once the data has been segregated, two different views are created, one for each of these two groups. All these are shown graphically in the data lineage diagram and can easily be interpreted.
Understanding the origin of data sources is beneficial for various reasons:
- Assessing the dependability of the data based on its provenance.
- Recognising and fixing error causes.
- Recognising improper data assumptions which may affect analysis.
- Maintaining audit trails for data governance and regulatory compliance.
- Ensuring that data transfers are secure and unaffected by changes.
- Identifying and minimising data redundancy in order to streamline processes and cut costs.
Apache Atlas Architecture
Atlas components are classified into four major categories – Core, Integration, Metadata Sources, and Apps:
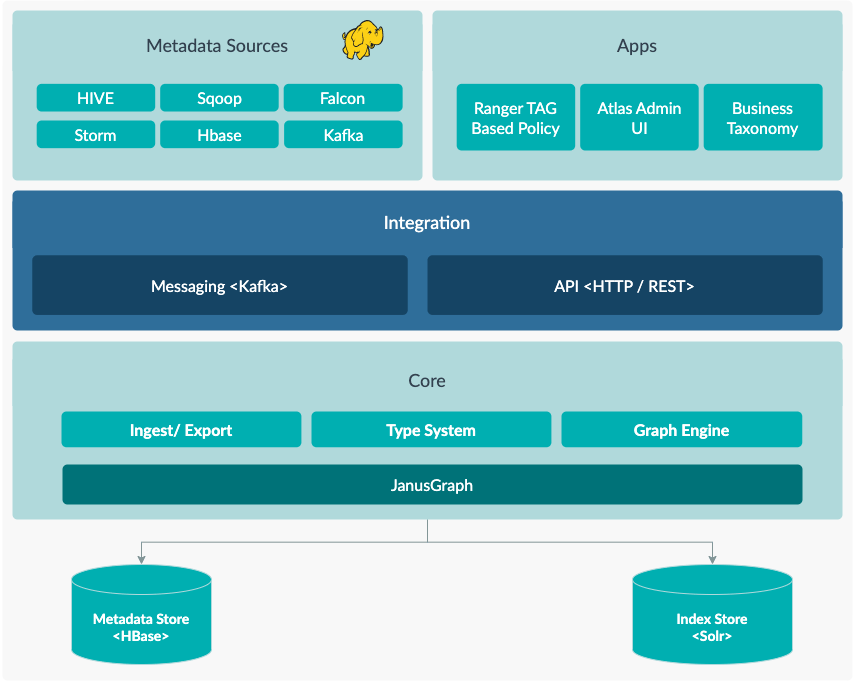
Figure 2: Atlas high level architecture — overview
(Source: https://atlas.apache.org/2.0.0/Architecture.html)
Atlas Core: This is the central component, which interfaces with the backend layer and feeds metadata and lineage information into the Atlas database. Atlas stores info in the backend using the HBase database and indexes using Apache Solr. The core component consists primarily of a Type System, which allows users to build and manage types and entities, a Graph Engine, which handles relationships between metadata objects, and Ingest/Export, which adds metadata and raises an event if there’s a change in the metadata.
Integration: Users utilise this layer to connect with Atlas. Atlas users can manage metadata in two ways:
- API: Atlas’s entire functionality is provided to end users via a REST API, which allows types and entities to be created, changed, and destroyed.
- Messaging: In addition to the API, users can interact with Atlas via a Kafka-based messaging interface.
Metadata Sources: This layer contains the data sources that are supported by default in Apache Atlas. This means that if a user has a data source of these types, they can begin recording their metadata in Atlas via REST APIs right away. Atlas natively supports the following data sources: HBase, Hive, Sqoop, Storm, and Kafka.
Atlas: Basic Concepts
In Atlas, metadata information is structured according to four different concepts: type, entity, attribute, and relationship:
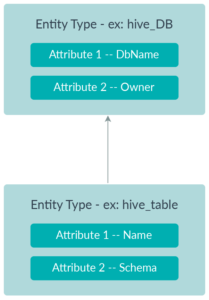
Figure 3: Pictorial representation of Atlas Concepts
Types
Type is a notion that governs how a certain type of metadata object can be saved in Atlas. A type is the programming equivalent of a class.
- A type is always identified by a distinct recognisable name.
- A type can have a variety of characteristics – attributes and relationships.
- Each attribute allows a particular data type.
- We can add any attribute depending on our business use case.
Although there are pre-defined types of different metadata, Apache Atlas provides an excellent interface to create our own: types can have primitive attributes, complex attributes and object references, and can also inherit from other types.
Entities
Each metadata object in the actual world is represented by an entity, which is an instance of a type. As previously stated, a type in Atlas is comparable to a class, and an entity is comparable to its object; a type can have several entities.
- Each entity is connected to a type, which is referred to as typeName.
- Each entity is given a GUID (a globally unique identification).
- An entity can be accessed at any time with its GUID.
- Each entity is also given a qualified name, which like its GUID, uniquely identifies it.
- The attribute values must be compatible with the specified type.
Attributes
In Atlas, an attribute is a property of the type or entity that we’re working with. An attribute has name and value. The data type of an entity’s attribute value should match the data type described in types.
Relationships
We can use Atlas not only to store metadata in the form of entities, but also to create relationships between them; a relationship establishes the connection between two entities. Atlas can show a pictorial depiction of connected entities by mapping their linkages, which can help to understand how one entity is reliant on the other.
If a database contains a table with columns and foreign key references, the Relationship feature will display each object and its relationships:
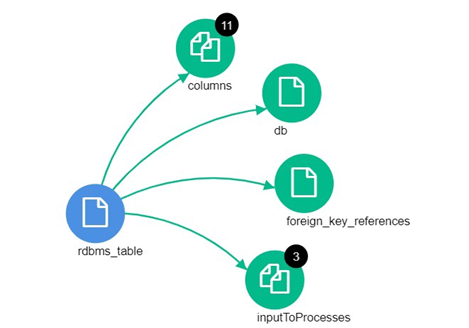
Figure 4: Atlas Relationships – a table entity related to other entities
Above, we can observe the following relationships:
- rdbms_table to columns, which indicates that rdbms_table has 11 columns.
- rdbms_table to db, which shows that rdbms_table belongs to db.
- rdbms_table to foreign_key_references, which shows that rdbms_table has foreign key references.
- rdbms_table to inputToProcesses, which shows that this rdbms_table has a relation with 3 inputs to the processes.
We will learn how to create entities and relationships for a custom entity type later on in this series of articles.
Apache Atlas Dashboard
The Apache Atlas Dashboard is its main interface, and it contains a wide range of information and functionalities. Let’s take a look at them one by one:
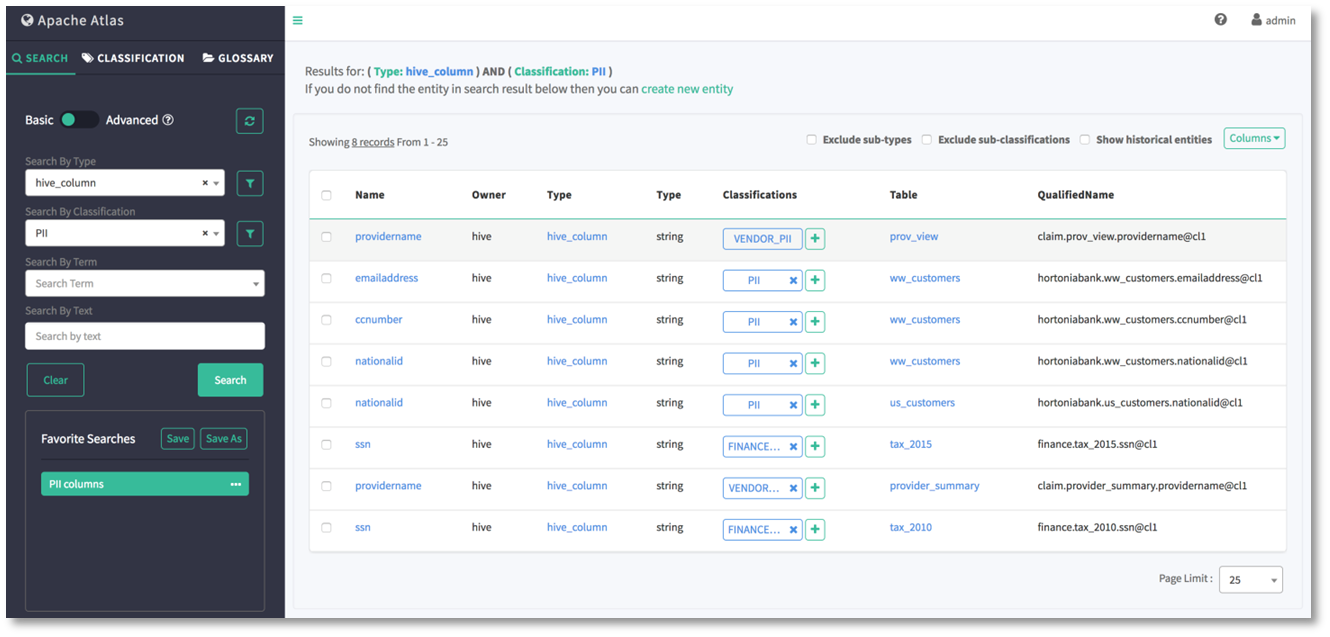
Figure 5: Atlas dashboard view
(Source: https://atlas.apache.org/public/images/twiki/search-basic-hive_column-PII.png)
Search
On the left side of the dashboard window we can see the search pane, with all the basic options required to perform successful searches, as shown in the image below:
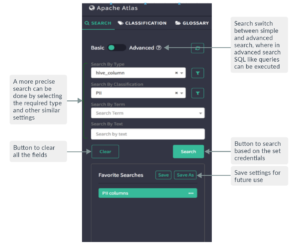
Figure 6: Apache Atlas search bar
Search Results
After entering a valid search query in the search pane, the search result appears on the right side of the dashboard:
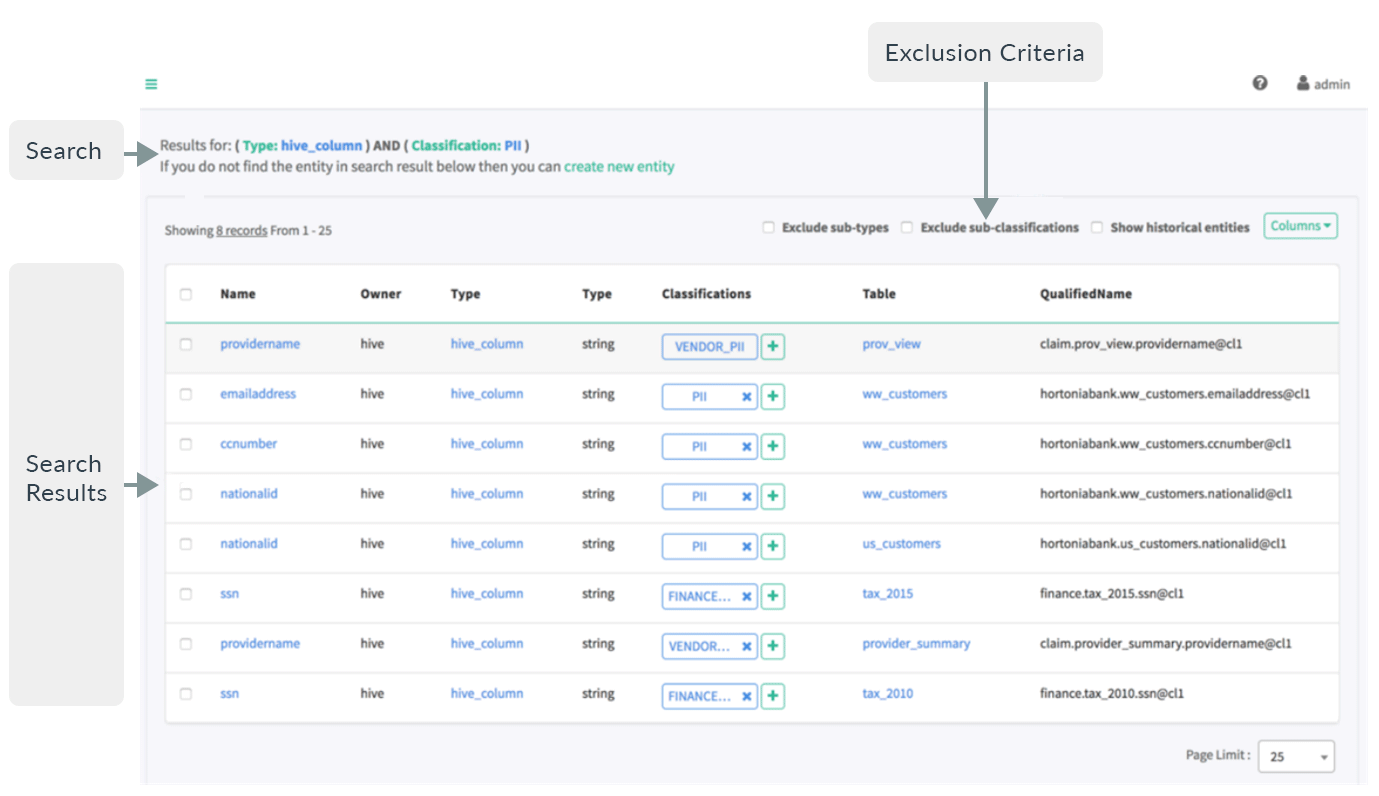
Figure 7: Search results in Apache Atlas
As we can see, the «search criteria» give us our «search results».
The following parameters about the sought entity appear in the search results:
- Name: provides the entity’s name.
- Owner: identifies the entity’s owner.
- Type: indicates the entity’s type.
- Classifications: the string-like labels that are utilised for certain searches.
- Table: the table where the data is stored.
- QualifiedName: the entity’s unique name, which can be used for reference.
More Details About the Entity
In addition, we can click on any entity to view its details: when you click on the entity name, a new page containing information about the entity appears. We can see the following details:
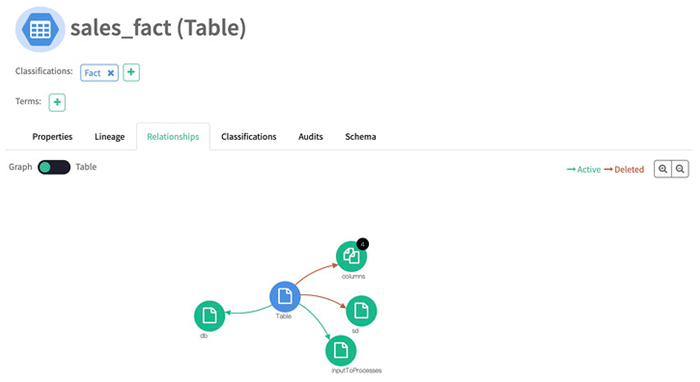
Figure 8: Entity details view
Properties: This tab displays the entity’s system metadata as well as any user-defined characteristics that have been added. It also includes a list of labels that have been assigned to the entity. You can use a free-text search to find this object by entering values from any of the «string» data type fields.
Lineage: For each entity, Atlas UI presents a lineage graph. The lineage graph for data asset entities illustrates when the entity was an input or output from an operation; the lineage graph for process entities displays all input and output entities utilised or produced by the operation.
Relationships: This tab displays the other entities that have relationships with this entity, and is used to move between them. The list of connected items can be displayed as a list or as a graph. The entities that comprise the lineage are included in the special relationship types «input» and «output».
Audits: Atlas tracks any changes to entity metadata; these modifications are detailed in the Audit tab of the entity details page. When Atlas updates the entity metadata, audits reveal the following changes:
- Classifications that have been added or withdrawn.
- Entity attributes that have been changed.
- Labels that have been added, changed, or removed.
- Relationships that have been added, changed, or removed.
- Terms in the glossary that have been added or removed.
Schema: When the current object is a table, the Schema tab appears and lists the table columns. This option allows you to dig down into a specific column or to add subcategories to columns.
Next Steps
In this article we’ve taken a close look at Apache Atlas, and gone through its architecture, the core components of its type-system, and its user-friendly interface. In a Hadoop context, Cloudera offers Atlas in its set of public and private cloud distributions. It would be interesting to know how metadata information from Hadoop systems is seamlessly integrated by the Cloudera offering, and we’ll be focusing on this in the next part of this series.
If you have any questions, doubts, or are simply interested in discovering more about Cloudera, Apache Atlas, or any other data tool, don’t hesitate to contact us at ClearPeaks. Our certified experts will be more than happy to help and guide you along your journey through Everything Data – Business Intelligence, Big Data, Advanced Analytics, and more!
Read the next parts of this series: Part 2, Part 3.
