
03 May 2023 Customising Azure Data Factory’s “Metadata-driven Copy Task”
Azure Data Factory (ADF) offers several options for data ingestion, the most well-known being “Copy data activity”. When dealing with only a few data objects and sources, defining an activity for each of them might be the way to go for most of us. However, as the solution scales up and the amount of data objects increases, the loading process can become inefficient and hard to maintain.
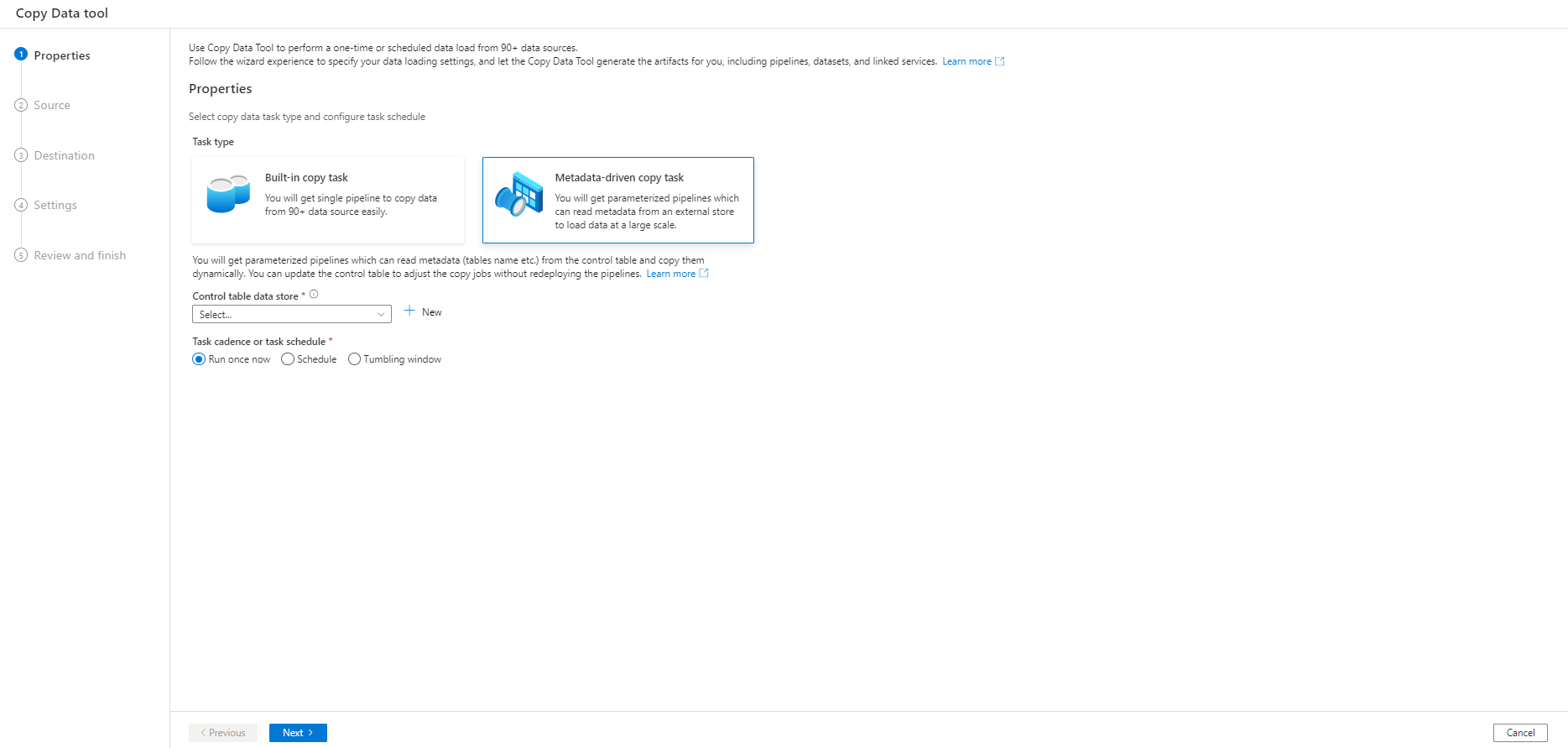
Figure 1: ADF wizard initial tab. We can choose between a basic “Copy activity” or the “Metadata-driven copy task”
ADF has its own built-in solution, the “Metadata-driven copy task”. In short, this tool writes a control table with the names of all the data objects, their copy behaviour and the destination of the data, among other information, and uses parameterised pipelines to read this metadata and perform the desired actions. Moreover, this tool has a user-friendly wizard that helps us to define all the settings of the copy task, so ADF can automatically generate all the parameterised pipelines and the SQL scripts to create the control table.
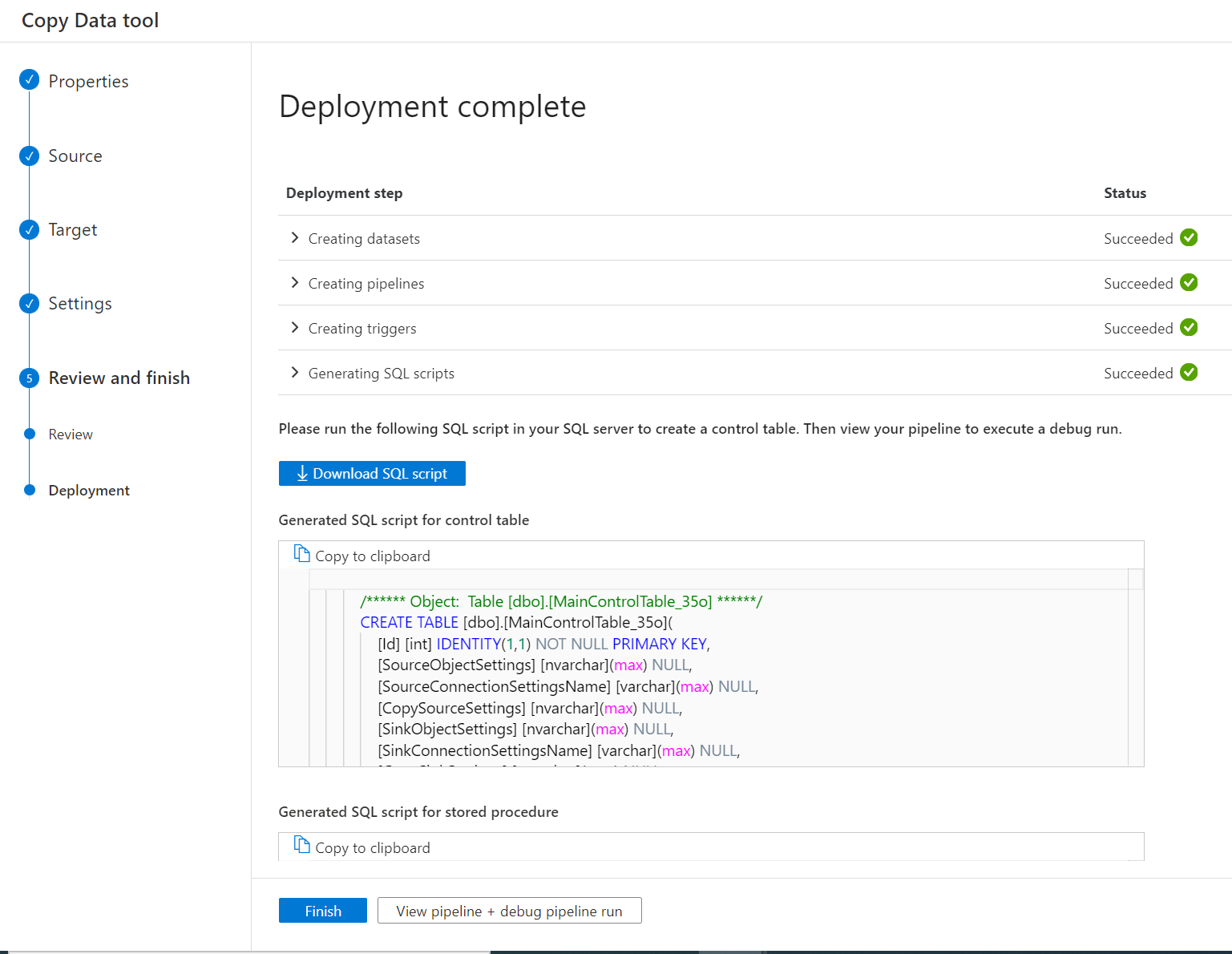
Figure 2: ADF wizard deployment tab. Creation of ADF objects and SQL scripts
For a better understanding of this blog post, we recommend taking a look the official documentation on the “Metadata-driven copy task”; and if you want a use case example, check out this blog post.
In this blog post, we’ll be discussing some limitations we encountered when using the configuration wizard to copy tables incrementally, which Azure refers to as Delta Load behaviour. We’ll also be sharing a workaround that we developed!
Configuration of Loading Behaviour
First of all, let’s see how copy behaviour is configured in this tool. The control table generated by ADF comes with a column named DataLoadingBehaviorSettings with the following JSON schema:
{
"dataLoadingBehavior": ,
"watermarkColumnName": ,
"watermarkColumnType": ,
"watermarkColumnStartValue":
}
With this approach, we treat the watermark as a column in the source table that allows us to load the object incrementally while storing its last loaded value. If we wanted to load a table incrementally using its “last modified date” as the watermark, starting from 2022, we would write the JSON as:
{
"dataLoadingBehavior": "DeltaLoad",
"watermarkColumnName": "LastModified_DateTime",
"watermarkColumnType": "DateTime",
"watermarkColumnStartValue": "2022-01-01T00:00:00"
}
Our Experience
Here at ClearPeaks we have leveraged this tool in several projects, and in each case it has proved to be the most suitable option for data ingestion, despite a couple of limitations that made us look for a workaround.
On the one hand, there is an issue when the “last modified date” of the table is split into two different columns, date and time (case A): we can’t uniquely define the watermark column, but instead need to concatenate both fields.
On the other hand, we have found cases when the “last modified date” column allows null values for newly inserted rows (case B): the problem here is that, when loading this table incrementally using this “last modified date” as the watermark, SQL doesn’t account for the null values, so we would be ignoring all the new rows. A solution to this problem would be to consider a second option as the watermark if the “last modified date” is null; a good choice would be the “inserted date” of the table, which is usually available in these cases.
The Workaround
When we thought these cases through, we realised that they all had something in common: we do not have an explicit watermark column candidate in the source table, but instead need to perform some data transformation to get one.
To overcome this limitation, what we need to do is redefine the field “watermarkColumnName” (in the DataLoadingBehaviorSettings column of the control table) so that it collects the query that transforms the data and returns the actual watermark. If we use the parameterised language of Data Factory, the query is ready to be consumed by our ADF pipelines.
Besides, we can leverage the flexible structure of JSON to include extra fields we may need to define the query in this column (DataLoadingBehaviorSettings). In case A, we would need the fields like “watermarkDate” and “watermarkTime”, while in case B we’d need “firstdWatermarkColumn” and “secondWatermarkColumn”. You can, of course, choose how to name these extra fields, but it is always good practice to choose meaningful names.
Now let’s run through an example of the modified DataLoadingBehaviorSettings JSON for each case:
Case A
{
"dataLoadingBehavior": "DeltaLoad",
"watermarkColumnName": "concat([@{json(item().DataLoadingBehaviorSettings).watermarkDate}],
' ', [@{json(item().
DataLoadingBehaviorSettings).watermarkTime}])",
"watermarkDate": "LastModified_Date",
"watermarkTime": "LastModified_Time",
"watermarkColumnType": "DateTime",
"watermarkColumnStartValue": "2022-01-01T00:00:00"
}
Case B
{
"dataLoadingBehavior": "DeltaLoad",
"watermarkColumnName":"coalesce([@{json(item().DataLoadingBehaviorSettings)
.firstWatermarkColumn}],
' ', [@{json(item().
DataLoadingBehaviorSettings).secondWatermarkColumn}])",
"firstWatermarkColumn": "LastModified_DateTime"
"secondWatermarkColumn": "Inserted_DateTime",
"watermarkColumnType": "DateTime",
"watermarkColumnStartValue": "2022-01-01T00:00:00"
}
Although these examples are valid for both cases, there are other potential scenarios, such as finding the last modified date in integer format (instead of “2022-01-01” it’s “20220101”), and in such cases we would need to include a statement to format the date as required in the query.
Our solution is robust enough to deal with this and similar situations: we can define any query in the “watermarkColumnName” field, and it’ll still be valid for ADF if we use the appropriate parameter expressions.
Configuration and Maintenance of The Solution
This solution might seem a touch tedious, since dealing with JSONs stored in an SQL database is not the most user-friendly experience! However, we don’t need to build this solution from scratch, neither do we need to rewrite every customised JSON file.
Our suggested approach would be to use the ADF “Metadata-driven copy tool” wizard to implement the solution. Even if the default configuration doesn’t work for us, it can still create all the pipelines and ADF objects we need, as well as providing an SQL script to create the control table and a stored procedure used to update the watermark column value.
For its efficient maintenance, here at ClearPeaks we have designed a set of additional SQL scripts and stored procedures, and so far they have proved very useful when we need to apply customisations and update a large number of data objects. With them, the user experience is smoother, only choosing the proper stored procedure and providing the new values; the procedure itself deals with the table modifications.
Conclusions
In this article we’ve reviewed some of the limitations we encountered when working with the “Metadata-driven copy task” wizard, an Azure Data Factory tool. We found that the best way to deal with these issues was to customise the metadata control table for our cases.
As a matter of fact, a proper definition of this table is key, since it is the object ruling all aspects of the data copy. With the help of our Azure experts, you too can adapt this tool to deal with any data ingestion situation and exploit its full potential.
If you need guidance or assistance in making your ingestion processes more efficient and maintainable, please do not hesitate to contact us, and one of our certified consultants will get right back to you!
