
07 Jul 2022 Cool Features in Azure Machine Learning
Azure Machine Learning is a cloud service developed by Microsoft that can be used to train and manage machine learning algorithms.
In this blog post we are going to learn about some of the cool features we can find in Azure Machine Learning to help data scientists to create and publish models to deliver insights for strategic decision-making and to drive business value too.
Azure Machine Learning
With Azure Machine Learning we can build, deploy, and manage our models at cloud scale. It’s a pay-as-you-go service, and provides a nice, user-friendly interface where you can drag and drop components to reduce code development. It offers a wide range of well-known algorithms that can easily be configured, and it also allows you to publish the model as a web service.
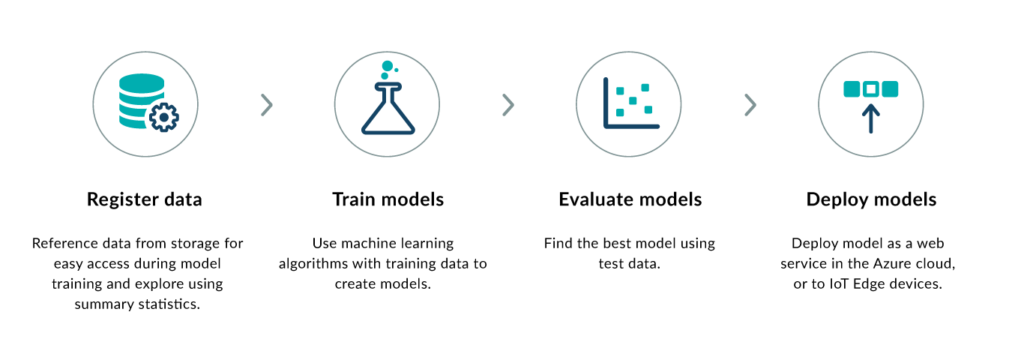
During the development of machine learning (ML) solutions, the most interesting assets in Azure, compared to code-based solutions, are the following.
ML Experiments
In an ML life cycle, a data scientist will experiment using different techniques of pre-processing, multiple models, various sets of hyperparameters and validation techniques in order to improve the performance of a model.
To prove the model’s capability and performance, it is important to keep track of the results of this process, and we can do this using Experiments in Azure ML:
An Experiment can be created using:
- Azure notebooks.
- Auto ML.
- Pipelines.
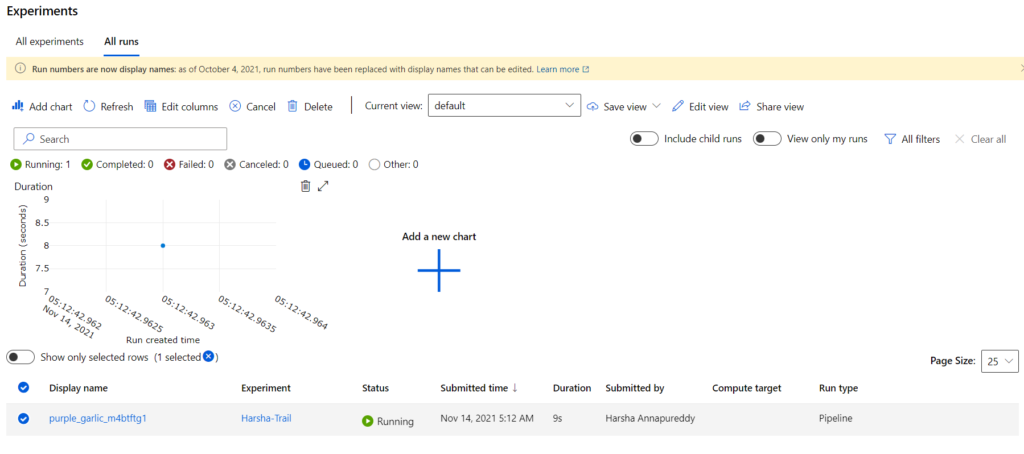
We can track the experiment runs/results in the Experiments window in Azure:
As part of the pipeline in an experiment, we can save our models in the model registry with the model performance parameters and hyperparameter attributes, which can be further used for validation/tracking.
ML Pipelines (Predefined and Custom)
Machine learning pipelines are the workflows used to define the steps in an ML life cycle sequentially for training and prediction. These ML pipelines can then be used in the web app as a REST-API, or they can be scheduled for recurrent executions as a job.
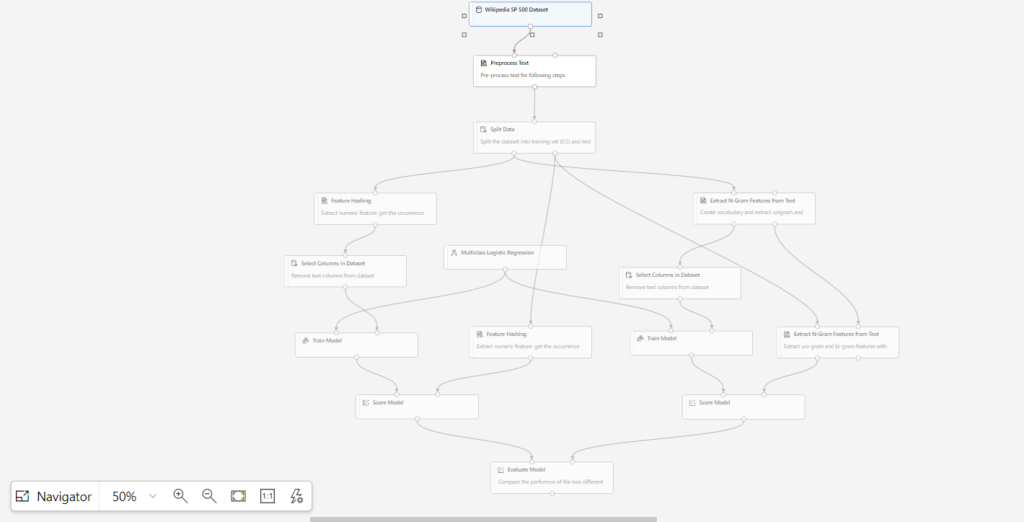
Example: For Wikipedia text classification, below we can see the general pipeline steps to be followed.
- Extract the Wikipedia data using web scraping or API.
- Pre-process the text: cleaning, stop word removal, lexical normalisation, etc.
- Text to vector conversion (using vectorisers like BoW, TF-IDF, word2vec, etc.).
- Train and test data splitting for training and validations.
- Train the model using the training data and perform hyperparameter tuning.
- Score the test data using the trained model.
- Apply different evaluation metrics to check the model’s performance.
- Create a feedback loop (if required).
A predefined pipeline is shown below for text classification. Alternatively, we can create our own custom pipelines using the drag-and-drop features available in Azure ML Studio/Designer.
Auto ML
What if an optimal ML model can be created with little or no coding and trained on your data? You can do it with Azure Auto ML!
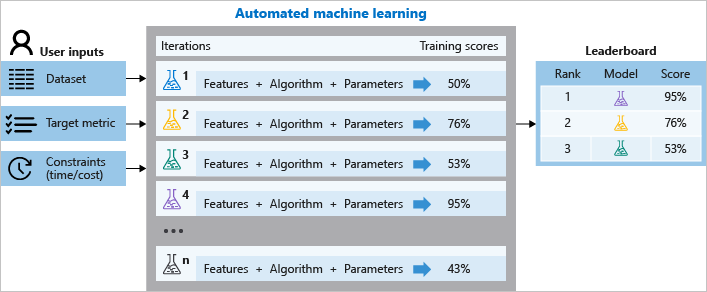
Azure Auto ML can train the model with any given dataset on use cases like classification, regression, forecasting and computer vision, by applying multiple feature engineering techniques to reduce loss and error, then validation techniques to remove the bias, training on various machine learning models to provide the best accuracy possible.
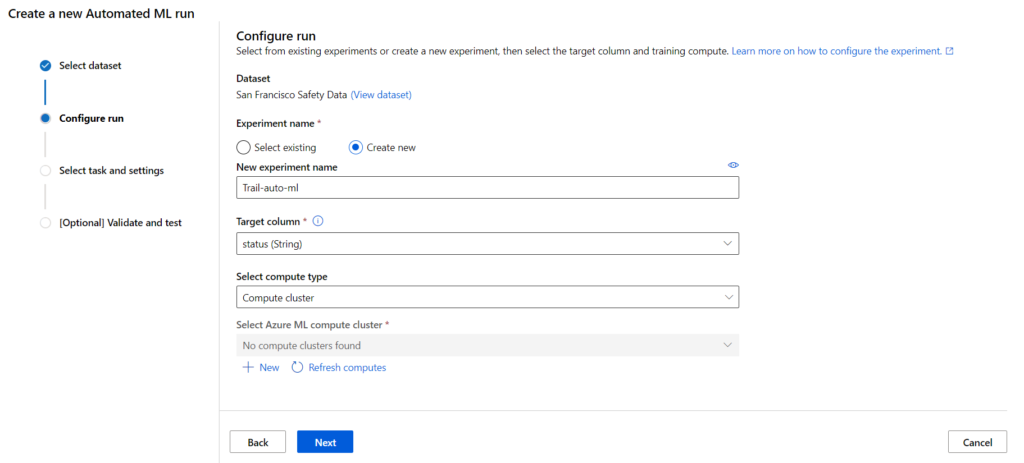
The important step when creating the automated model run is the parameter configuration to terminate the run process. This determines how many iterations there are to be over different models, the hyperparameter settings, pre-processing/featurisation, and what metrics to look at to determine the best model.
We can also deploy the best model from the model registry and use it for inferencing:
Data Labelling
Imagine we have hundreds of images to be labelled and need to create bounding boxes to train the image classification model. Manually labelling and creating the bounding boxes for a huge set of images is pretty hard work, but luckily Azure ML provides the handy capability of labelling the images using an iterative approach or an ML-based image tagging approach.
ML-assisted labelling consists of two phases:
- Clustering.
- Prelabelling.
Clustering: After a certain number of labels have been submitted, the ML classification model starts to group similar items together. These images are presented to the labellers on the same screen to speed up manual tagging. Clustering is especially useful when the labeller is viewing a grid of 4, 6, or 9 images.
Prelabelling: After enough labels have been submitted, a classification model is used to predict tags, or an object detection model is used to predict bounding boxes. The labeller now sees pages with predicted labels already present for each item; for object detection, predicted boxes are also shown. The task is then to review these predictions and correct any mislabelled images before submitting the page. Once the model has been trained on your manually labelled data, the model is evaluated on a test set of manually labelled items to determine its accuracy at different confidence thresholds.
Feature Importance
Feature importance refers to a set of techniques to assign scores to input features in a predictive model, indicating the relative importance of each feature in predicting a target value. Feature importance really helps us to get interesting and useful insights into the data we are using.
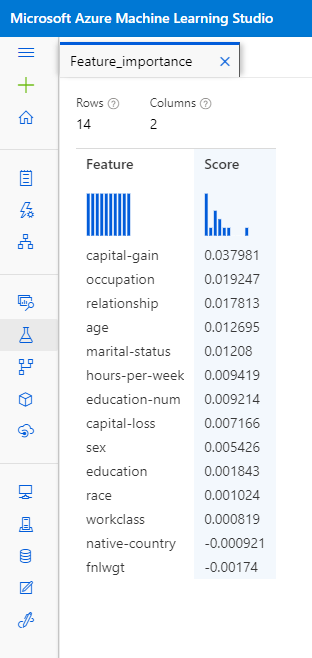
In the example above, we can see a model that tries to predict the income level of adult individuals in which the four features that contribute the most when predicting the target value are capital gain, occupation, relationship, and age.
Tune Model Hyperparameters
Every ML model has a different set of input parameters, depending on the type of algorithm we are trying to use. These parameters are determined during training and need to be tuned to get optimal performance. In the image shown below, we can see the results and rank of different metrics with different sets of input parameters:
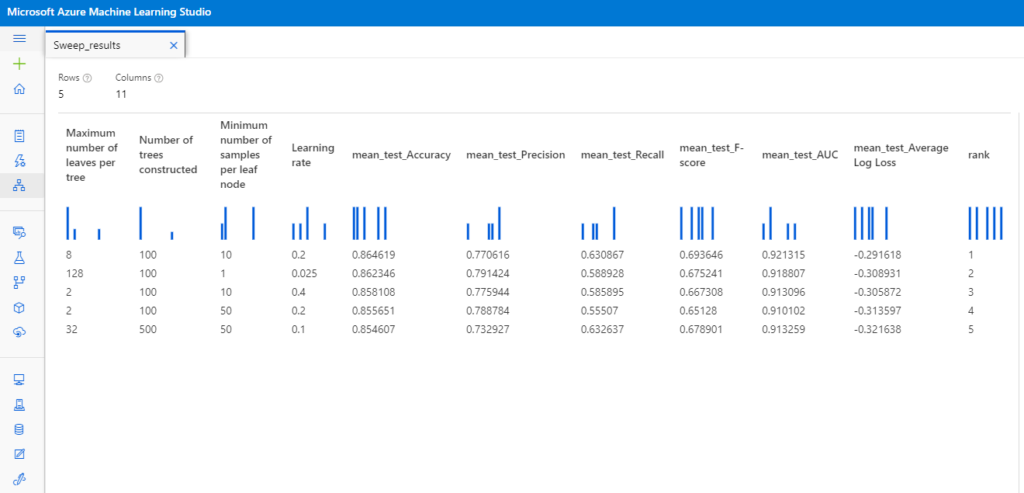
Moreover, Azure Machine Learning allows us to select the best model for the prediction, based on the evaluation metric chosen.
Pre-process Text
The goal in text analytics is to uncover insights, trends, and patterns in text data. This module allows us to clean and simplify text, although at the moment it only supports English.
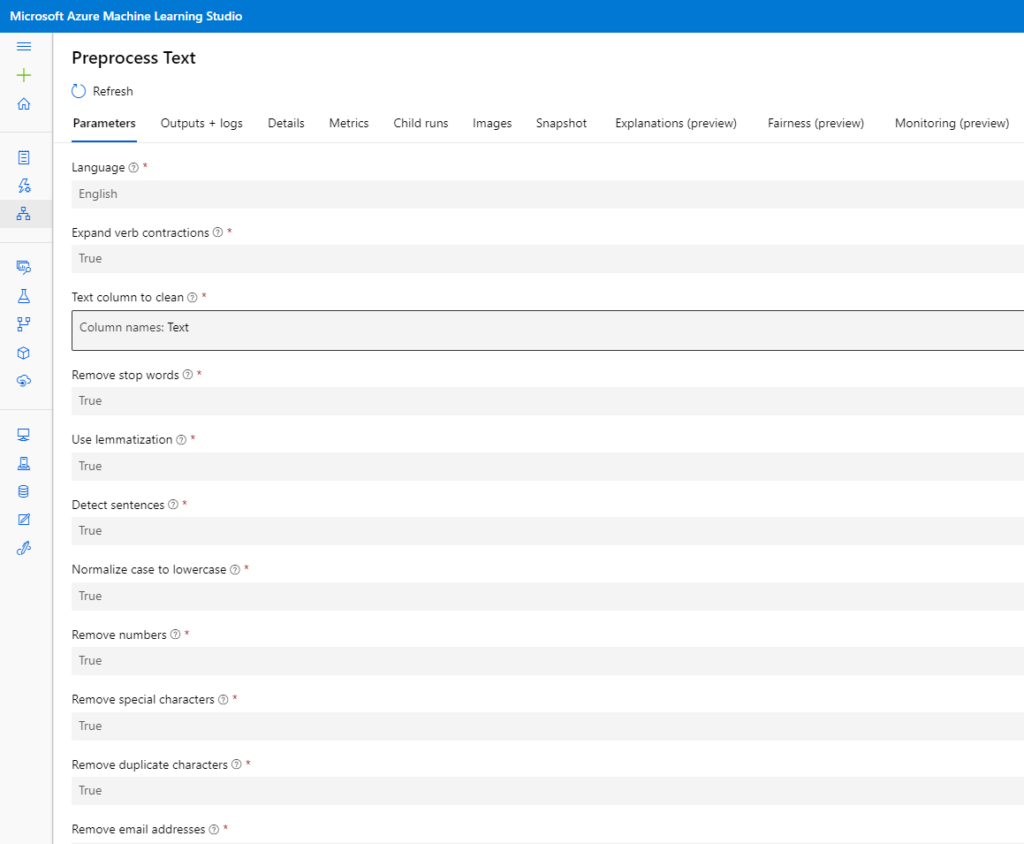
As we can see, this module unifies many text processing tasks, such as the identification and removal of stop words, text lemmatisation, token removal, etc.
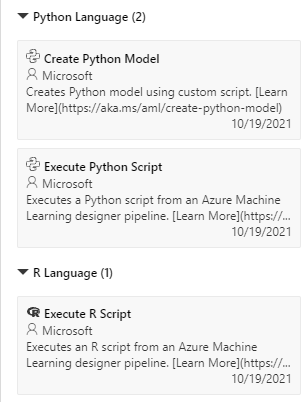
Versatility
It is possible to run Python and R in Azure Machine Learning, opening the door to custom data transformations, to building new ML algorithms, and to using functionalities that are otherwise not supported.
Conclusion
Azure Machine Learning offers an intuitive, effective, drag-and-drop platform that can help businesses to create codeless machine learning solutions using different techniques such as clustering, deep learning, text analytics, computer vision, recommenders, and anomaly detection. The possibility of adding Python or R scripts helps to extend the potential of the models, creating custom features, or implementing new algorithms.
Moreover, it lets us follow a white box approach, showing the features that impacted the most during the training of the models. This interpretability leads to the creation of solutions focused on business understanding, helping companies to stay accountable for their data-driven decisions.
If your organisation needs some professional pointers on how ML solutions can grow your business, don’t hesitate to get in touch with one of our specialists.
