
22 Jun 2023 Cloudera Image Warehouse – End-to-End Computer Vision Use Cases in Cloudera
Overview
Artificial Intelligence (AI), as we all know, is taking the technological world by storm, and it’s no secret that it is drastically changing how businesses are run. Through AI, companies are constantly looking for ways to enhance their operations and stay ahead of the competition in today’s fast-paced and constantly changing market. Computer vision is one of the buzziest fields in AI right now, and it involves enabling machines to interpret and understand visual data from the world around them.
One of the most widely used applications of computer vision is image classification, in which images are recognised and categorised by computers according to their visual characteristics. This has many applications in industries like aerospace, logistics, healthcare, security, entertainment, etc., and the demand for accurate and efficient image classification algorithms is increasing rapidly as the volume of data continues to expand exponentially. Thanks to advancements in deep learning, image classification has become more sophisticated, precise, and faster than ever before.
Here at ClearPeaks, we have a long history of working with Cloudera and we pride ourselves on our deployments of their latest technologies for our customers. Recently, our team successfully executed an inventory management optimisation use case using image classification with the Cloudera stack for one of our customers in the aerospace industry. It was during this project that we saw how we could extract a blueprint from the solution we were building, that could be reused for other computer vision implementations with Cloudera. That idea has now materialised into what we’re going to present in this blog post, Cloudera Image Warehouse.
Today we’ll dive into Cloudera Image Warehouse and its components through a dummy use case that is simple enough to understand, but at the same time, covers all aspects of the blueprint, so that you can start imagining what applications it could have for you and your organisation!
Use Case Overview

Figure 1: CIFAR-10 dataset.
(Source: https://www.cs.toronto.edu/~kriz/cifar.html)
Our dummy use case is essentially an image classification using the CIFAR-10 dataset. The CIFAR-10 dataset consists of 60,000 32×32 px colour images in 10 classes, with 6,000 images per class. There are 50,000 training images and 10,000 test images. The 10 classes are airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck.
We are going to build a real-time Python image classifier. The 50,000 images are used to train a model (then tested against the 10,000 test images) that can be later used to classify new images.
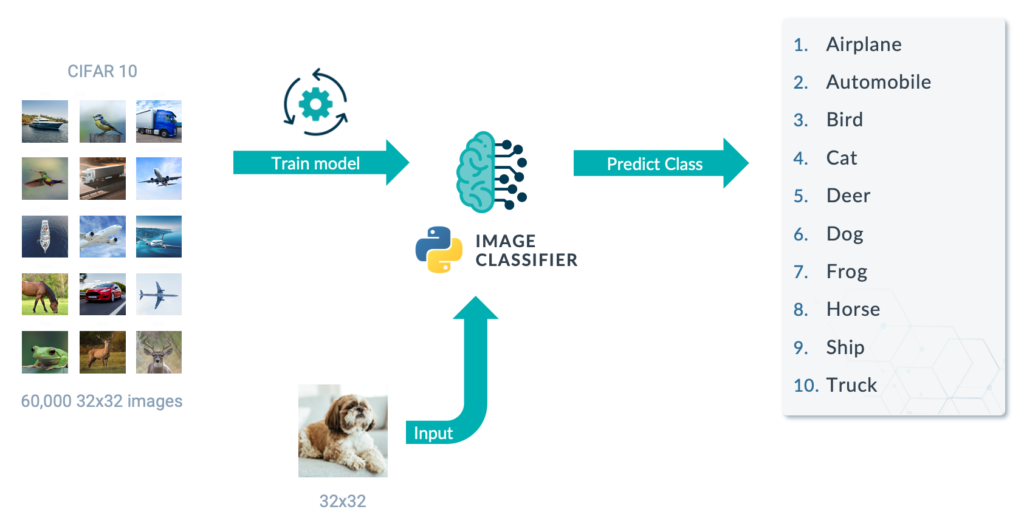
Figure 2: Python Image Classifier.
We want to provide the image classifier to end users so that they can upload and classify new images in real time. Not only that, but we also want to be able to store all the new images and their related metadata (file name, predicted class, source IP, source users, timestamp, etc.) and to run analytics on top of them (for example, to know how many new images from each class we get each day).
Cloudera Image Warehouse
Cloudera Image Warehouse is a combination of services in Cloudera Data Platform (CDP) that work together to tackle end-to-end computer vision use cases; it can run both on-premise and in the cloud. In this blog post we’ll use it to tackle the demo use case presented above, but it can be used for much more complex and ambitious use cases too.
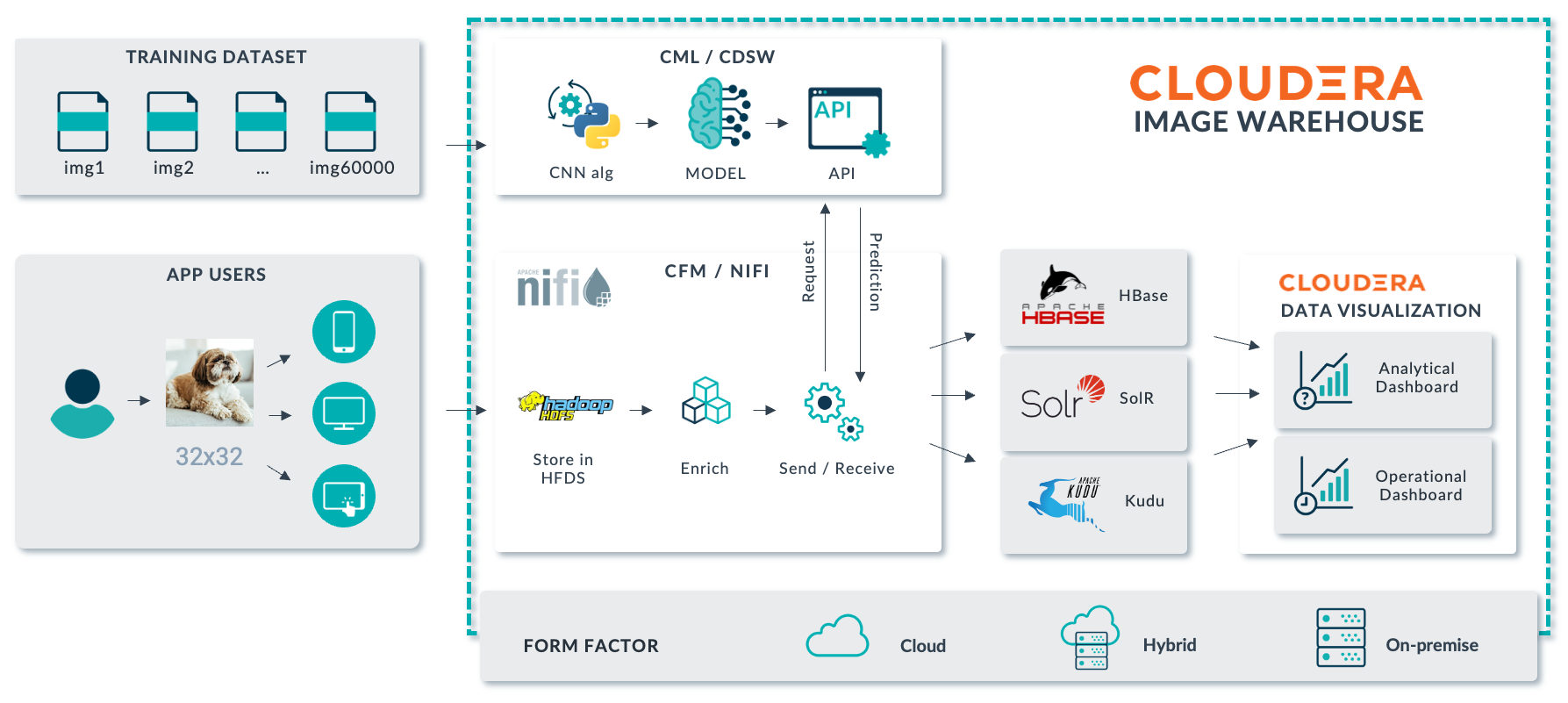
Figure 3: Cloudera Image Warehouse.
Images uploaded by users are ingested with NiFi and stored in any of the possible storage options supported by CDP (HDFS in the above image, but it could also be Ozone or cloud storage – AWS S3, Azure ADLS or GCP CS). Cloudera Data Science Workbench or its evolution Cloudera Machine Learning (a Cloudera Data Service that is available both on-premise and in the cloud) is used to train deep learning models; these models can then be used for real-time inference (predictions) of new images via scalable and fault-tolerant REST APIs.
The images, their related metadata, and the information extracted from the inference (for example, the class of image) can then be stored using NiFi in any of the data stores in CDP such as Kudu or Solr to serve analytical use cases (the first one for SQL-like analytical queries with real-time needs; the second for Google-like searches), or HBase for operational use cases. To create analytics dashboards we can use Cloudera Data Visualization (though it is also possible to use third-party dashboarding tools such as Power BI).
In the next sections we will look at the various components of Cloudera Image Warehouse, employing our dummy use case to illustrate how they work.
Cloudera Data Science Workbench / Cloudera Machine Learning
Cloudera Data Science Workbench (CDSW) is an enterprise data science platform designed to make it easy for data scientists and analysts to build, manage, and deploy machine learning and data science models at scale. With the introduction and proliferation of the Cloudera Data Services offering, both on-premise and in the cloud (which enable the most used CDP services to run on Kubernetes, with all the benefits that offers), CDSW has evolved into Cloudera Machine Learning (CML). You can check out the key differences between CDSW and CML here.
CML, like CDSW, is a comprehensive data science platform that provides powerful tools for model management and deployment. One of its key advantages is the ability to deploy models as REST APIs that then can be used for real-time inference. CML leverages Docker and Kubernetes to allocate resources for isolated container environments. It ensures that each project has its own isolated environment, with all the necessary dependencies and libraries pre-installed, allowing data scientists to focus on building models and experimenting with data without having to worry about managing infrastructure or dependencies.
While we have used CDSW for our dummy use case, please note that either CDSW or CML can be used for the Cloudera Image Warehouse (or for any AI use case for that matter). So, from now on we will refer to CDSW only, but remember that CML could also be used.
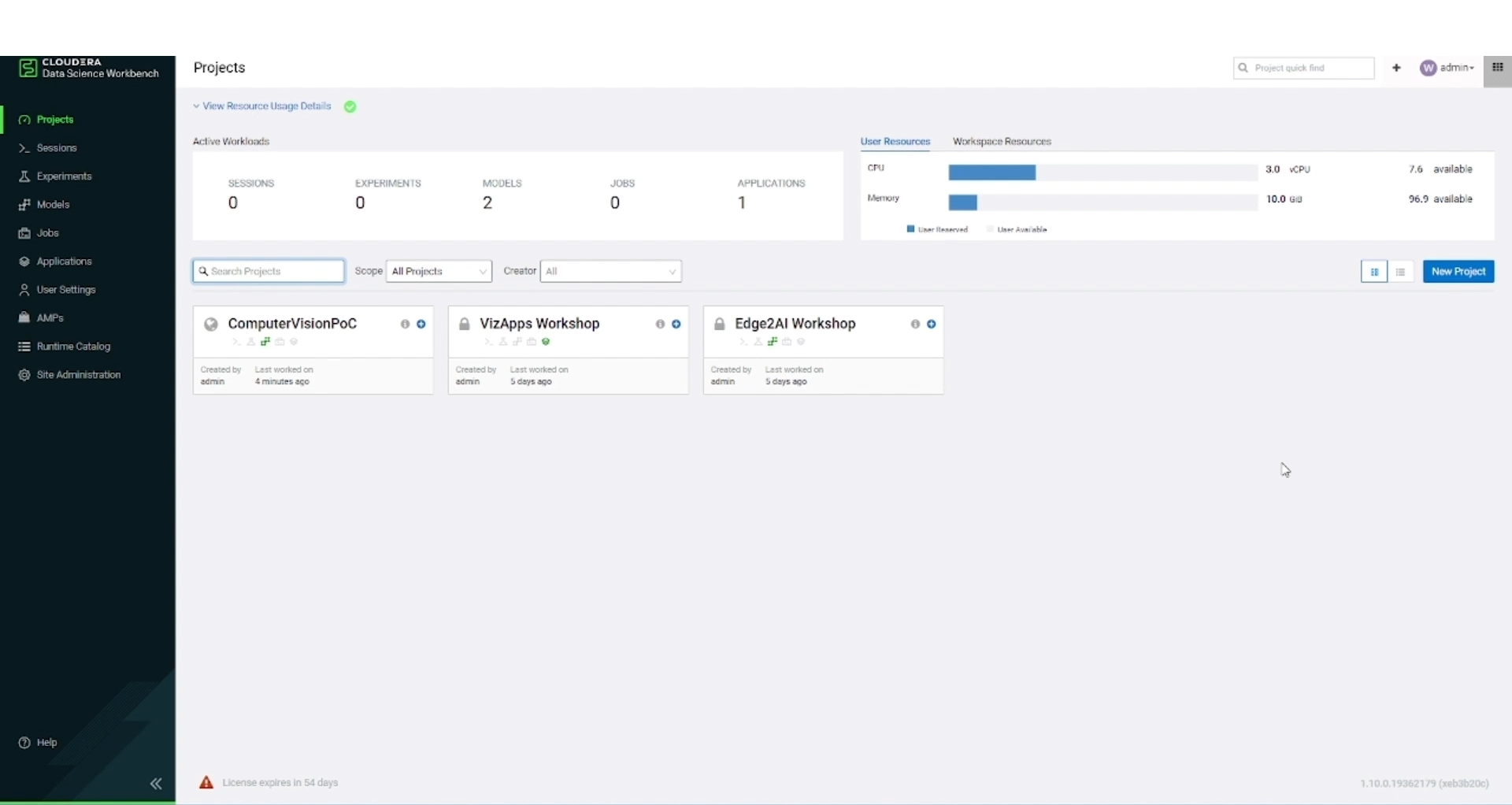
Figure 4: Cloudera Data Science Workbench UI.
In the image above, the CDSW UI showcases a list of ongoing projects, along with the status of any sessions or jobs that are currently in progress. It also offers an overview of the allocated resources. For our demo use case, we have created a project called ‘ComputerVisionPoC’ and within that project we will (a) train a deep leaning model, (b) create an image classifier that, using the model, can classify a new image, and (c) deploy a REST API (called model in CDSW) that can be used for real-time inference.
Training a Deep Learning Model
Deep learning models to tackle challenging computer vision use cases are on the rise, and the most common technique is a Convolutional Neural Network (CNN). Without going into too much detail, CNNs are inspired by the visual cortex of the human brain and consist of a series of interconnected layers, each of which performs a specific function in analysing and processing visual data.
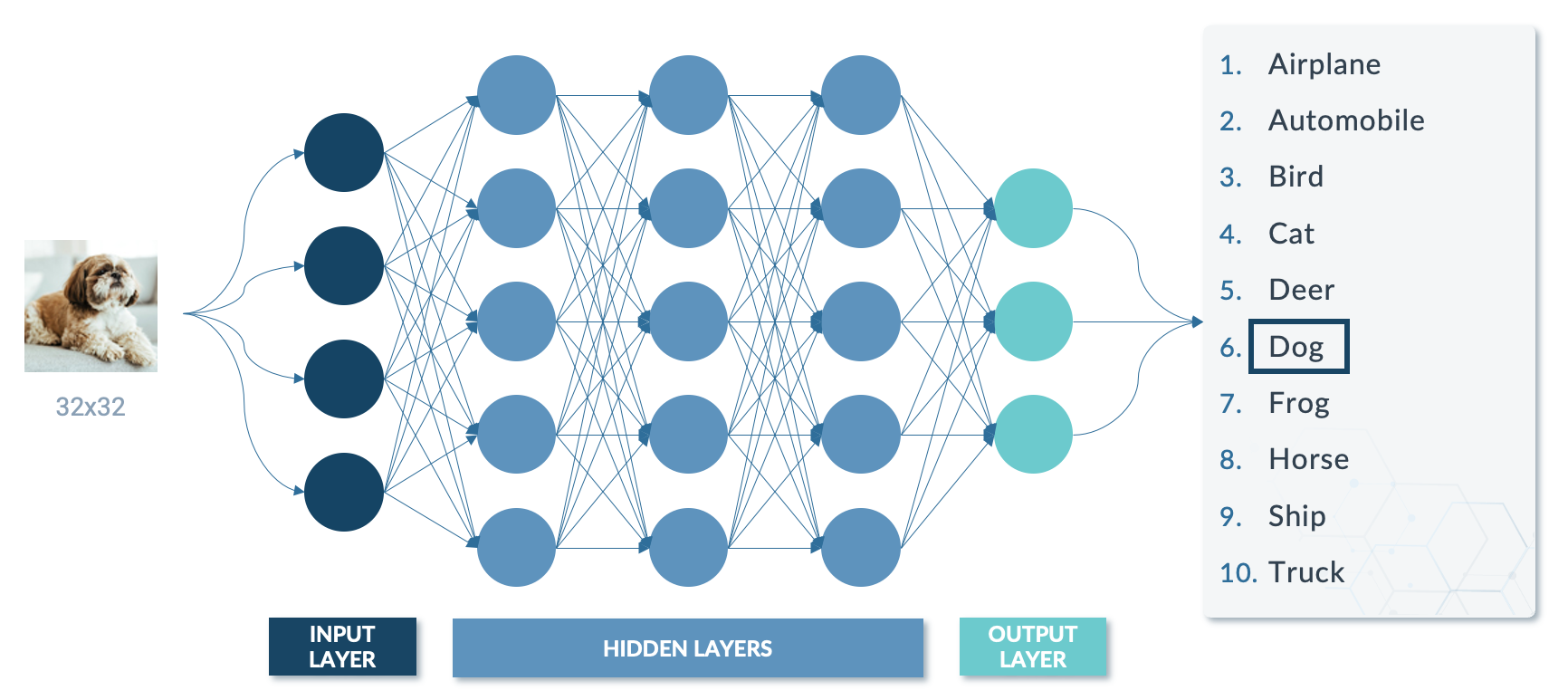
Figure 5: Visual representation of CNN.
We can use CDSW to train CNN models. Note that training these models can be time-consuming, and distributed model training approaches can be used to increase training speed. For the sake of simplicity, we used a single Python runtime to build the model in CDSW in our dummy use case, but in real-life situations the use of other approaches might be more recommendable either within Cloudera (see this Cloudera blog post for an example of using Spark for training a CNN using deeplearning4j) or outside (in the end, a trained model is a serialised file, so it is possible to train the model outside Cloudera and import it once trained in order to use it within Cloudera).
The image below shows a snippet of the Python file used to train the CNN model. The script reads the images from the CIFAR-10 dataset and goes through several processes, including data pre-processing, training, evaluation, and finally, saving the model. When training a deep learning model, it is essential to split the dataset into training and testing sets. In our case, we had 60,000 images, divided into 50,000 for training and 10,000 for testing. After training the model, we evaluate its performance using various classification metrics. Finally, we save the model in H5 format within the files of our CDSW project environment, ensuring that we can easily access it for later use.
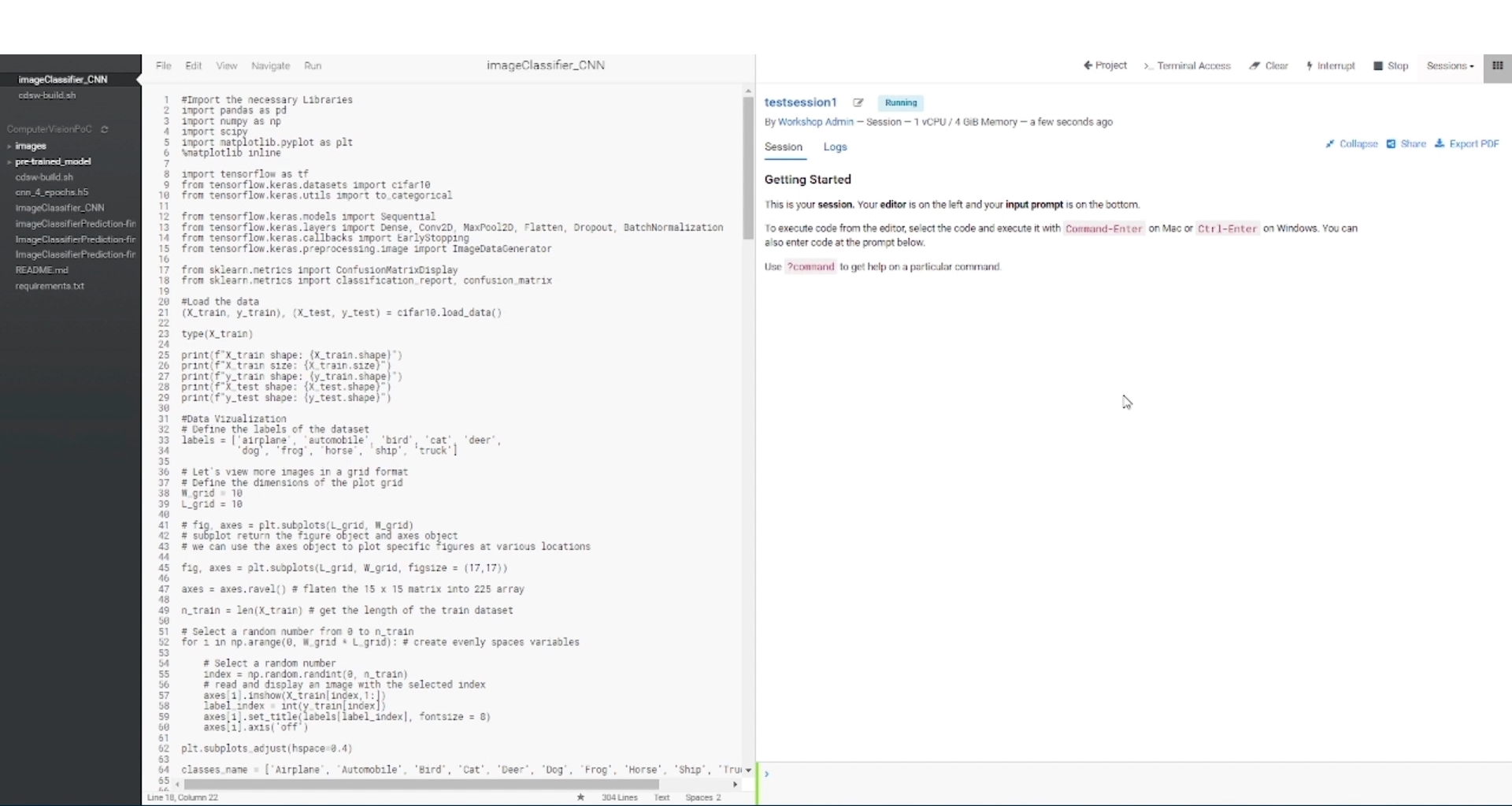
Figure 6: Python file used to train the CNN model.
When we want to execute the Python file to train the model (and also to develop it), we need to start a session. Launching a session can be done with the CDSW UI. When doing so, it is possible to customise session details such as the session name, kernel type (e.g., R, PySpark, Python), or the CPU and memory allocation. After launching a session, it runs in a secure docker container, and we can access the workbench which contains a file editor on the left and an output pane on the right.
Creating an Image Classifier
Once we have trained the model (either within or outside Cloudera), we are ready to create our image classifier. This is a Python function (see the snippet below) that loads the trained model, reads an input image from a HDFS location, performs pre-processing on the image, and finally, makes the prediction and returns it.
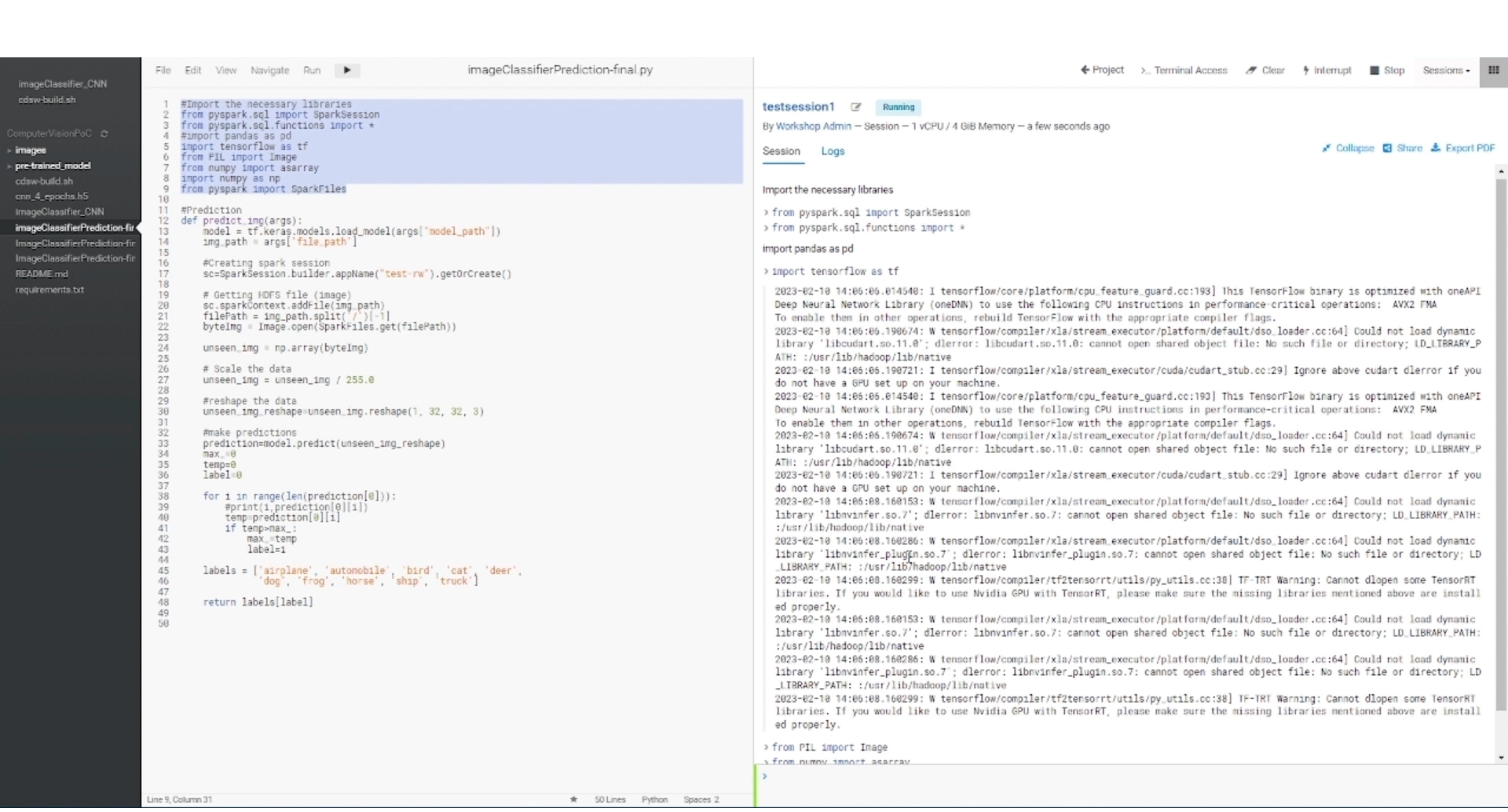
Figure 7: Python function for image classifier opened in the workbench (on the left we have the file editor, and on the right the output pane).
There are two steps to image pre-processing: first, we scale the pixel values of the image that range from 0 to 255 to a range between 0 and 1 to help the model generalise well and to produce better results; secondly, we reshape the image to 32 x 32 pixels so as to reduce the consumption of compute resources.
Deploying a Model Accessible via REST API
Now that our Python image classifier is ready, we can deploy it into a CDSW model, i.e., a prediction function which is accessible via a REST API. This process is crucial for enabling other applications and services to interact with the models and make predictions.
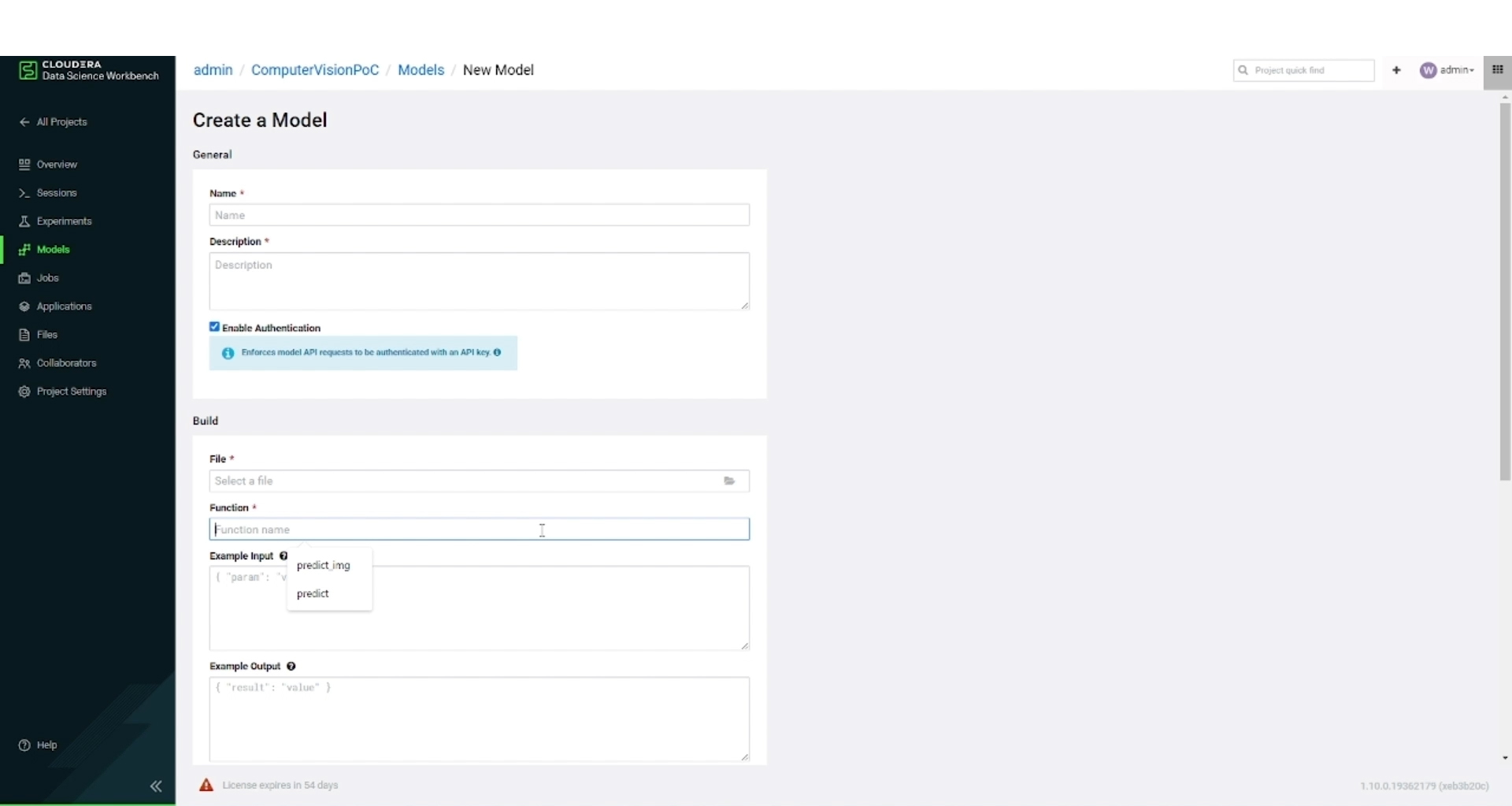
Figure 8: Model Creation in CDSW.
The image above depicts the creation of a CDSW model. We need to provide a name and a description for the model and to select a specific function within a project file that will be invoked when the model is called. We can also choose the resources and number of replicas that we want to allocate to the model.
Finally, the model can be deployed by clicking on the Deploy button: then CDSW will create a docker image for the model, which includes a snapshot of the project code, model parameters from training, and all the dependencies mentioned in the build script. The built model will be deployed to a REST endpoint that accepts JSON arguments as input. As part of the build process, CDSW will install any dependencies specified in the build script.
In this section, we have seen how CDSW (or CML) makes it easy to deploy the complete lifecycle of a machine learning project from research to deployment with its powerful features and user-friendly interface. In the next section, we will see how Cloudera Image Warehouse leverages NiFi (in any of its shapes within CDP) to ingest data, as well as to interact with CDSW to use the deployed REST API for real-time inference, with any of the selected data stores where we will store the images and their metadata.
Cloudera Data Flow – Cloudera Flow Management / (NiFi)
Cloudera Data Flow (CDF) is a set of addons on top of the private cloud form factor of CDP, used for real-time streaming analytics, providing data ingestion, curation, and analysis for immediate insights. One of the components of CDF is Cloudera Flow Management (CFM) which leverages the robustness of Apache NiFi to offer a user-friendly, no-code solution for data ingestion and management. By harnessing NiFi’s intuitive graphical interface and efficient processors, CFM empowers enterprises with scalable capabilities for seamless data movement, transformation, and overall management. On the public cloud form factor of CDP we also find Cloudera Data Flow for Public Cloud, the evolution of CFM that allows you to run NiFi on Kubernetes or on serverless cloud functions such as AWS Lambda.
For Cloudera Image Warehouse, we use NiFi as the main flow controller (in our dummy use case we used CFM, but CDF for Public Cloud would work just as well). The image below shows the four sections into which the NiFi flow is split: Handle Request, Pre-processing, Prediction, and Storing Result.
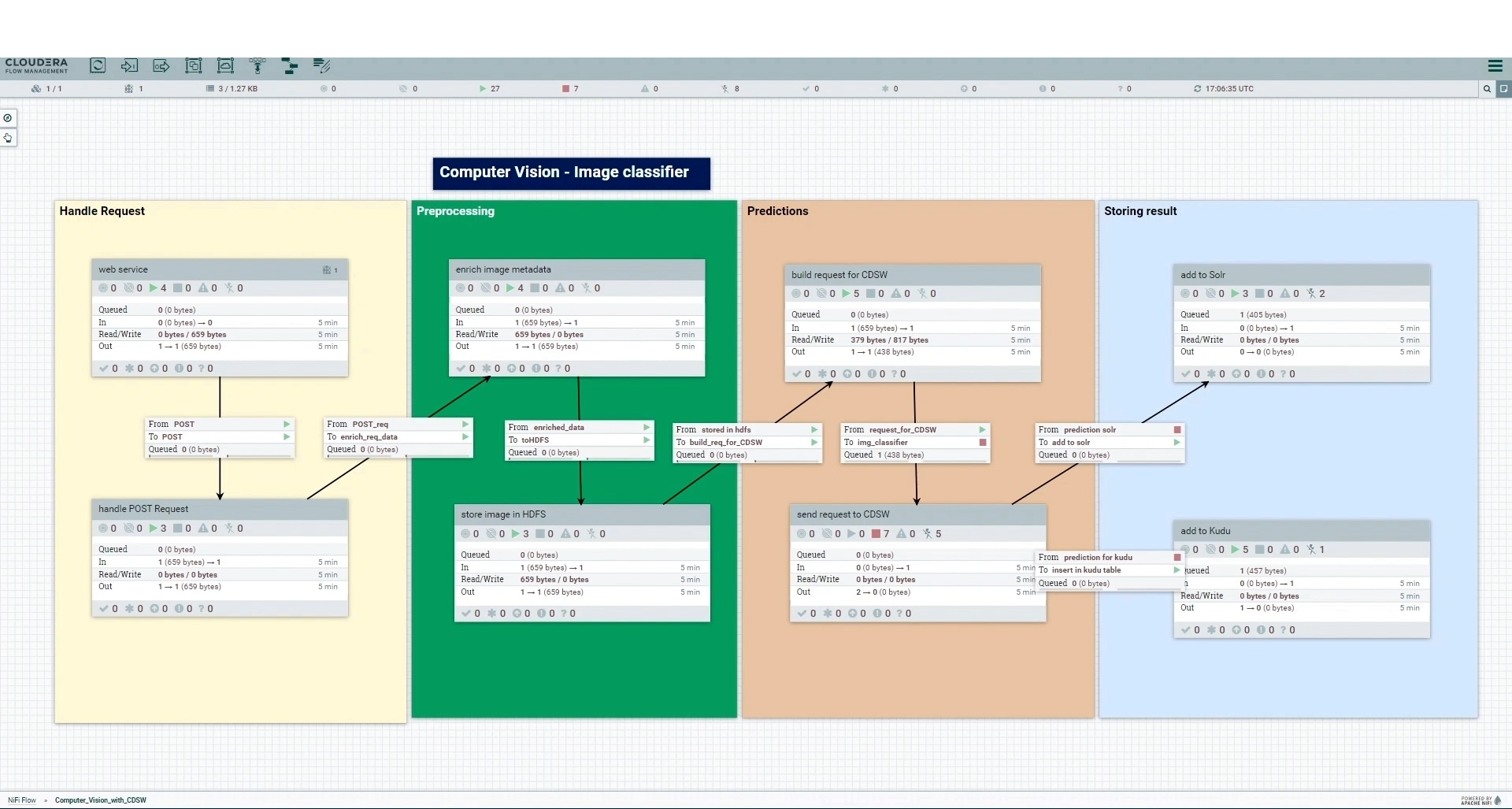
Figure 9: NiFi canvas depicting the 4 tasks done for Cloudera Image Warehouse.
The Handle Request section is responsible for creating HTTP endpoints on a particular port on the NiFi nodes. Users can submit new images to these endpoints (for our dummy use case we just used Postman to submit new images, but we could have web or mobile apps as user data ingestion interfaces too, as long as they can interact with HTTP endpoints). We only handle POST requests containing images as resources; any non-image data is rejected after filtering requests based on their type and content. Check out our previous blog post that outlines working with HTTP endpoints in NiFi.
Moving on to the Pre-processing section, we enhance the metadata of the received image by incorporating essential details (like flowfile attributes in NiFi) such as timestamp, size, image format and source IP, and then we also store the image on HDFS. We used HDFS for this dummy use case, but other options such as HBase, Ozone, or cloud storage would also be possible (actually, HDFS would eventually suffer small-file problems with such small images, so using HBase, Ozone or cloud storage would be preferable, although for simplicity we opted for HDFS for this example).
The Prediction section of the NiFi flow plays a crucial role in classifying images based on the trained deep learning model. First, we build the HTTP request including an access key and the image location on HDFS. Second, the HTTP request is sent to the CDSW model, i.e. the REST API endpoint, that classifies the image and gives us the prediction in real time.
Lastly, the Storing Result section receives the image metadata (now including the predicted class) and stores it in the selected data stores. In our use case, we store it is as a Kudu table record and a Solr document; these two data stores allow the later querying of image metadata for analytics and search purposes. Note that other CDP data stores could also be used here (but given the single-record orientation of the use case we would not recommend using data stores such as Hive due to the eventual small-file problems).
In this section, we have seen how NiFi can control the overall flow of the data through the various components of CDP that make up Cloudera Image Warehouse. Now that our images and their metadata are stored in different data stores, we are ready to tackle analytics and operational applications. In the next section we will see how we can create data analytics dashboards with Cloudera Data Visualization within CDP.
Cloudera Data Visualization
Cloudera Data Visualization (often referred to as Cloudera Data Viz, or also CDV) is a tool within CDP for fast and easy self-service data visualisation. It is integrated within the CML Data Service (and also CDW) and for on-premise, you can also use it as part of CDSW.
For our dummy use case we created a simple dashboard, depicted below, that shows some metrics such as the number of images in total, per predicted class, per time, and per IP. The data is segregated into specific time periods, including today, yesterday, seven days ago, last week, and 30 days ago. What’s more, the dashboard presents frequently predicted object calls and request details, which offer valuable insights into the performance of the prediction model.
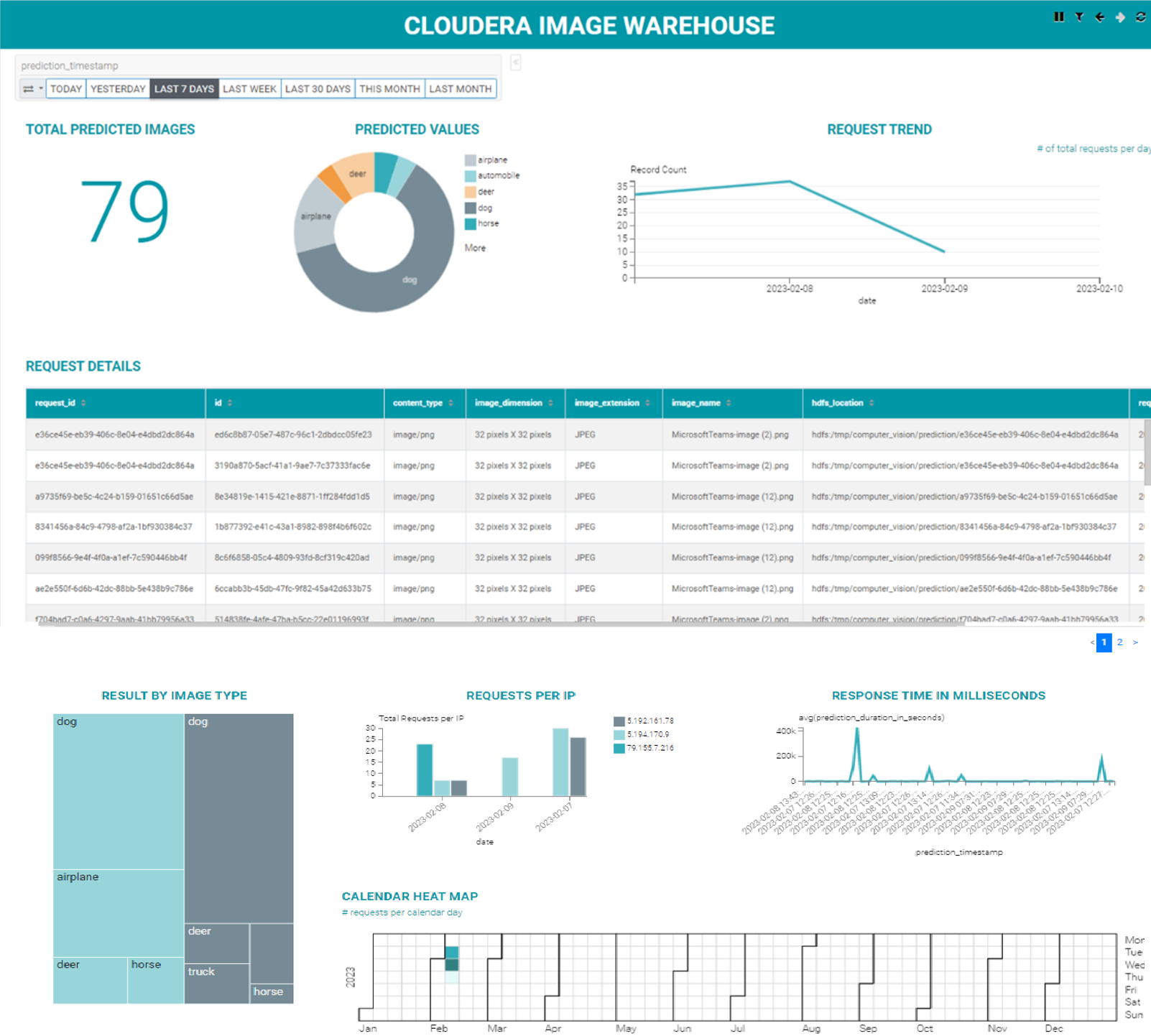
Figure 10: Cloudera Image Warehouse analytics dashboard with CDP Data Viz.
Conclusions
In this blog post, we have presented Cloudera Image Warehouse. While it was initially developed for an inventory management use case in the aerospace industry, we have generalised it into a framework for tackling any end-to-end computer vision use case leveraging the Cloudera stack.
Imagine what it can do for you! Think automation use cases such as predictive maintenance and fault detection, product damage detection and faster claims processing, property valuation and management, goods tracking and the optimisation of logistic operations, detection and classification of environmental hazards, quality control for manufacturing processes, or even analysis of drill cuttings and geologic characterisation. You can watch this video to see a demo of Cloudera Image Warehouse.
If you would like further information about this solution and whether it can meet your specific needs, don’t hesitate to contact us – we are here to help! Our certified experts will be more than happy to guide you along your journey to leverage AI for the benefit of your organisation.
