
09 Feb 2022 Choosing your Data Warehouse on Azure: Synapse Dedicated SQL Pool vs Synapse Serverless SQL Pool vs Azure SQL Database (Part 2)
This is the second and last part of our blog series about Azure Synapse Analytics. As we explained in the first blog post, Azure Synapse Analytics is a relatively new analytics service in Microsoft that Azure is positioning as its flagship for Data Analytics.
The aim of this series is to introduce Synapse and to compare its querying capabilities, provided via its SQL pools (dedicated and serverless), to Azure SQL database, in order to help the reader in deciding when to choose one or the other to act as their Azure data warehouse. In the first blog post we explained how to configure a Synapse workspace and introduced the two types of SQL pool Synapse provides to query data: Serverless SQL Pools and Dedicated SQL Pools. We also presented a suitable Azure SQL database to compare it to a Dedicated SQL Pool.
In this second part we will give you a hands-on example of the different ways that Synapse can query data: first, we will query data in a data lake using external tables via a Serverless SQL Pool and also using a Dedicated SQL Pool; second, we will load the data into internal tables inside Synapse internal storage and use a Dedicated SQL Pool to query it. Finally, to compare its querying capabilities to other Azure services that can also act as data warehouses, we will load and query the data in an Azure SQL database and see how they all compare to each other.
Hands-On Example
Having introduced Azure Synapse, let’s put it to the test. Our test has two parts: firstly, we will explore the capabilities of Synapse SQL querying data in a data lake and check how it performs on different formats (CSVs, Parquets, and partitioned Parquets). We will use external tables in both serverless and dedicated SQL pools, pointing to the files in Azure data lake storage. It is important to remember that the Dedicated SQL Pool can only query Parquet files, since creating external tables for CSVs is not supported. Secondly, we will load data into the Synapse Dedicated SQL Pool and into an Azure SQL database and compare their performance when querying this data.
The Dataset, Versions and the Queries
As mentioned earlier, the data we will be working with is from the well-known TPC-H benchmark dataset which emulates a global company distributing or selling products. It is organised in eight tables that store information about orders, suppliers, customers, etc. The tables composing the data model are, from the smallest to the largest: region, nation, supplier, customer, part, partsupp, orders, and lineitem. The relationships between them are presented in the schema below:
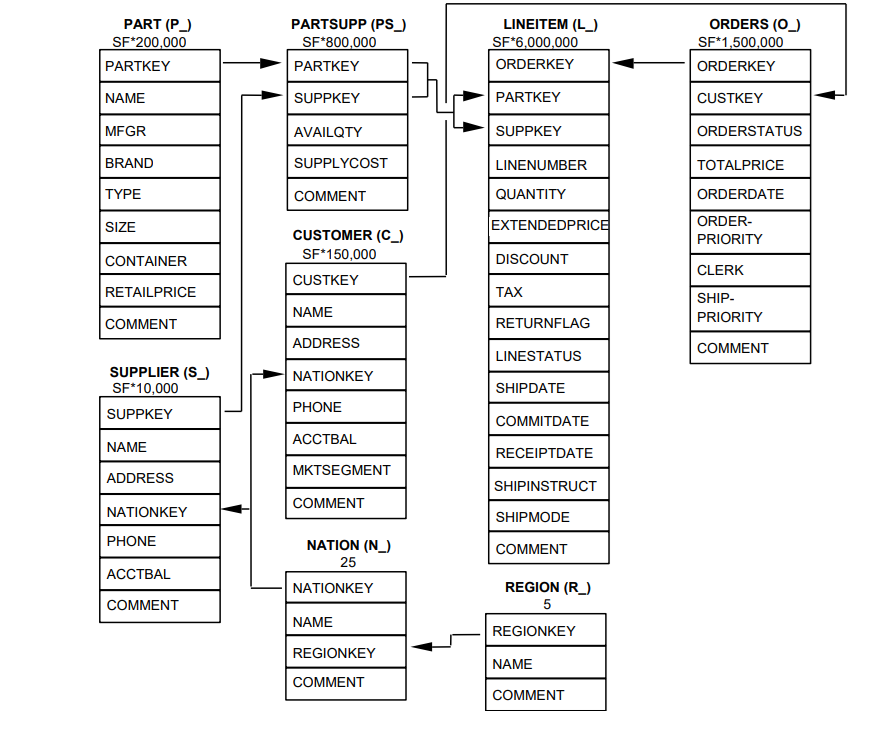
Figure 1
The numbers below the table names give us an idea of the table size, representing the number of rows proportionally. Note that lineitem and orders are significantly larger than the rest of the tables, whereas region and nation only have a few rows.
Furthermore, the TPC-H benchmark includes a set of business-oriented queries, and we chose ten of them for our own benchmark: Q1, Q2, Q3, Q4, Q6, Q9, Q10, Q12, Q14 and Q15. An overview of the operations these queries involve is presented in the following table. Most of the chosen queries filter by the columns l_shipdate from lineitem and/or o_orderdate from the orders table, fitting in with our idea to use these fields as partition columns in their tables.
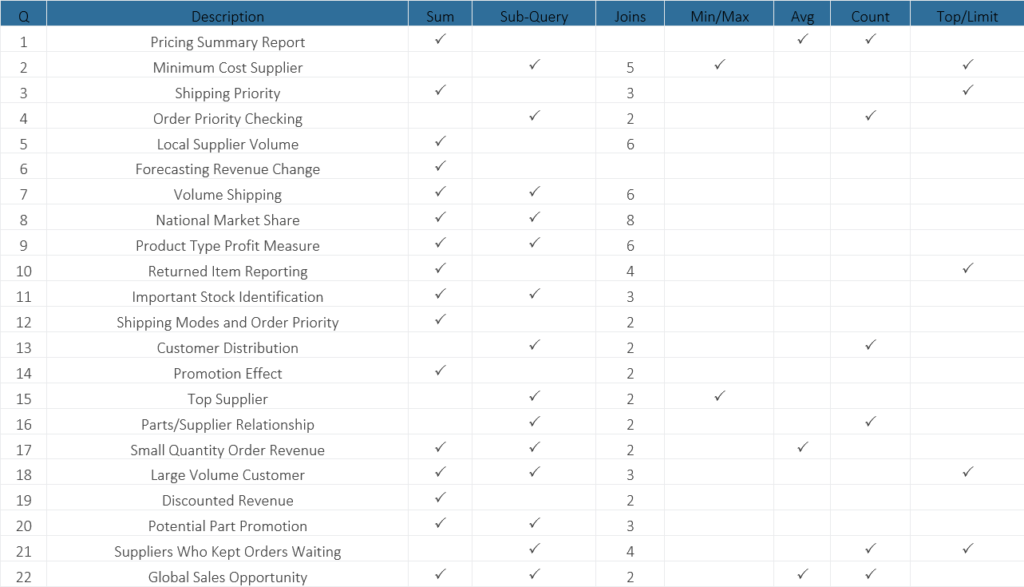
Figure 2
We used exactly the same dataset in our previous blog series Data Lake Querying in AWS. So, our data was first sitting in AWS S3 storage, and as we wanted this benchmark to be specific to Azure resources, our first step was to copy the data from S3 to the Azure data lake. This destination store is the primary storage account of our Synapse workspace, and to do so we leveraged the Copy Activity pipeline in the Integrate Tab.
We took 8 tables (in 8 different folders in a bucket) from S3, and each table (folder) was composed of one or more files in CSV format, using a pipe (‘|’) as the field delimiter. Because Synapse SQL does not support this character as a valid delimiter, we had to convert the dataset to real comma-separated-values files, so our first version of the dataset in Azure is a set of real CSV files.
We also converted the data to Parquet files to obtain our second version of the dataset; finally, we created partitioned versions of the two largest tables, order and lineitem, to make the third version. For more details about partitioning and its advantages, please check out this blog post. Following best partitioning practices, we chose a date field as the partition column, and we used the year part of ORDERDATE in order and SHIPDATE in lineitem, making one partition per year.
To make the conversions described above to generate the three versions of the dataset (1-CSV dataset, 2-unpartitioned Parquet dataset, 3-Parquet dataset with the two largest tables partitioned), we used Data Flow mappings in the Synapse Develop Hub.
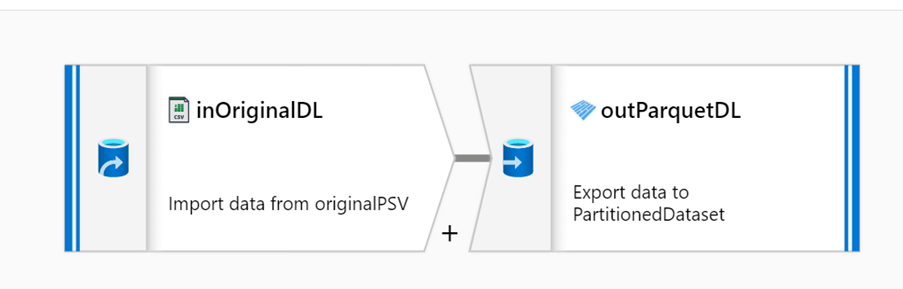
Figure 3
This mapping basically consisted of a source transformation, representing the dataset in its original format, and a sink dataset that represented the new format. In the sink transformation we can choose the type of partitioning. In our case, we used a keys partition strategy and the pertinent date field as the partitioning column.
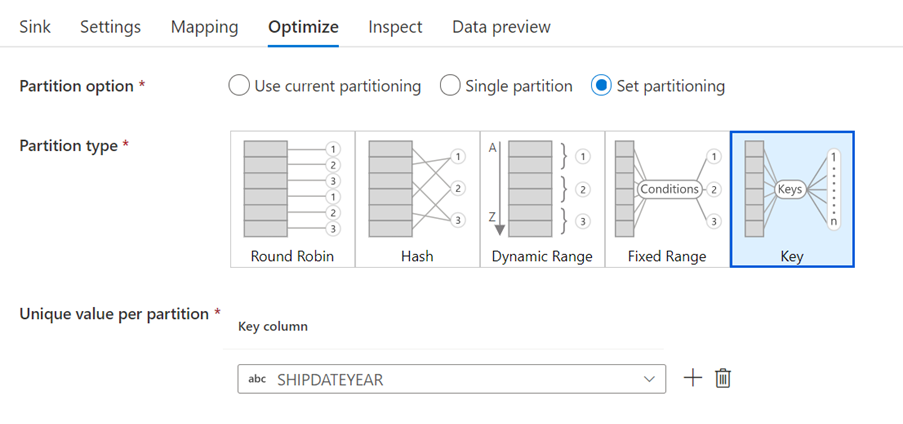
Figure 4
Such Data Flow designs are really simple when compared to the full capabilities of the tool. However, exploring and testing them is not the aim of our work.
Preparing Serverless SQL Pool
To start exploring this dataset in its three versions in the data lake, Synapse workspace comes with Serverless SQL Pool. This is a built-in service, meaning that no extra configuration is required, and we can query the dataset immediately after the creation of the workspace. The fastest way to explore data is using the OPENROWSET function of T-SQL. However, if we are to design and execute complex queries, it may be more practical and user-friendly to create external tables and then use these objects in the queries, as we did.
To create an external table with T-SQL, follow these steps:
- Create a new database in the serverless pool; the built-in master database does not support external tables. Alternatively, we can create a schema in the new database.
- Create an external data source that will point to the external data, in our case, the Azure data lake.
- Create an external file format with the characteristics of the file format we are querying. Supported formats are PARQUET, ORC, DELIMITEDTEXT, and RCFILE.
- Finally, create the external table itself in the new database and use the external data source and the external file format as arguments.
This entire process can be developed with a SQL script (T-SQL) in the Synapse Studio Develop Hub. Let’s look at an example of external table creation, more specifically the creation of the external table to query the Nation table (TPC-H data model) in CSV format (delimited text).

Figure 5
In the above code snippet, there are several things worth noting: first, when creating an EXTERNAL FILE FORMAT for delimited text, we need to specify format options like the string delimiter and the field terminator. In our case, since we are working with a CSV, it is a comma (‘,’). This is not the case when creating an EXTERNAL FILE FORMAT for a Parquet file. We can also configure the column names, datatypes, nullability and collation when creating an external table.
However, we do not have absolute freedom in the configuration: the datatype and number of columns provided in the table must match the original source. Finally, remember that we can query all the files matching a name pattern in a folder using the ‘*’ character.
Following this procedure, we created external tables for the different versions of the dataset. In total we had 8 external tables for the CSV dataset, 8 tables for the Parquet dataset, plus the partitioned versions of orders and lineitem.
Querying Serverless SQL Pool
To obtain the results we performed the query executions first over the CSV external tables, then over the Parquet external tables using the unpartitioned versions of orders and lineitem, and finally over the Parquet external tables using the partitioned versions of orders and lineitem. To design and execute these queries, Azure Synapse Studio has the option to create SQL scripts in its Develop hub, without needing to use an external tool to write SQL queries. Despite the usage of this tool, the queries run on the Serverless SQL pool.
Preparing and Loading in Dedicated SQL Pool
We followed the same procedure to execute the queries using external tables in the Dedicated SQL Pool. In fact, we used the same SQL scripts, only changing the database where they run. In this case though, we only queried Parquet files. External CSVs are not supported in a Dedicated SQL Pool.
We also wanted to load and query the data in the Dedicated SQL Pool’s internal store. As we mentioned in the configuration section, there are several ways to load data into the Synapse’s Dedicated SQL Pool, but the easiest and most customisable is by using pipelines. They can be built in the Integrate tab in Azure Synapse Studio, and the Copy Data tool further simplifies the process by asking the user what to do and building the pipeline in the background.
The Copy Data tool is designed to be user-friendly: first, we selected the source and a connection method with the required authentication to access the data; then, as the data needs to be extracted from files, additional information about the file layout was given; finally, by providing a destination table for the data, the pipeline was up and running.
Preparing and Loading in Azure SQL Database
We followed a similar process to load the data into the Azure SQL database; in fact, we could have used the same pipeline and only changed the destination to get the data there, but we wanted to try loading the data from the Dedicated SQL Pool instead.
In this case, as the source was already a table, it was even simpler as no information about the file layout was needed.
The time taken to load the data into Azure SQL database was significantly higher compared to the data load into the Dedicated SQL Pool. This exemplifies how the Dedicated SQL Pool uses Azure storage to locate internal tables, while Azure SQL database comes with independent storage.
Optimisations When Storing Data in Dedicated SQL Pool and in Azure SQL Database
Additionally, as in real case scenarios, we sorted the tables with clustered indexes in their key values from both services and created non-clustered indexes for the dates in the ORDERS and LINEITEM tables (the biggest tables). Creating non-clustered indexes is a way to optimise the performance of a database by minimising the number of disk accesses required when a query is processed.
In the specific case of the Dedicated SQL Pool, we also partitioned the biggest tables (ORDERS and LINEITEM) by years, thus further facilitating queries that use the date columns.
Querying Dedicated SQL Pool and Azure SQL Database
With the tables loaded into the Synapse Dedicated SQL Pool and Azure SQL database, we were ready to query the data.
To query the data in the Dedicated SQL Pool, we used the Develop tab from Azure Synapse Studio; the same tool as used to query the Serverless SQL Pool allows us to query the Dedicated SQL Pool just by changing the source:
Figure 6: Azure Synapse Studio. Develop tab. Selecting pool
Unfortunately, Azure SQL database cannot be queried through the online platform and required installing programmes locally, such as Microsoft’s SQL Server Management Studio (SSMS) or Azure Data Studio (ADS).
SSMS is the best-known choice as it has been around for longer, but it is more focused on configuring and administrating the database. On the other hand, ADS is really focused on editing queries, and includes Jupyter-like notebooks that can be written in different programming languages and can add charting options for the results.
Figure 7: Azure Data Studio
Currently, within Azure Portal, a Query Editor, which will simplify the process by removing the need for specific software is being previewed. However, it has a 5-minute timeout for query execution, which was not enough for the queries used in the PoC.
Results
Serverless SQL Pool
The queries had to be done to files from the Synapse Serverless Pool, as it has no internal storage.
The same 10 queries from the TPC-H benchmark were executed with each of the file types (CSV, Parquet, and partitioned Parquet), but queries 2 and 15 were skipped in the partitioned Parquet as they did not access the tables we chose to partition.
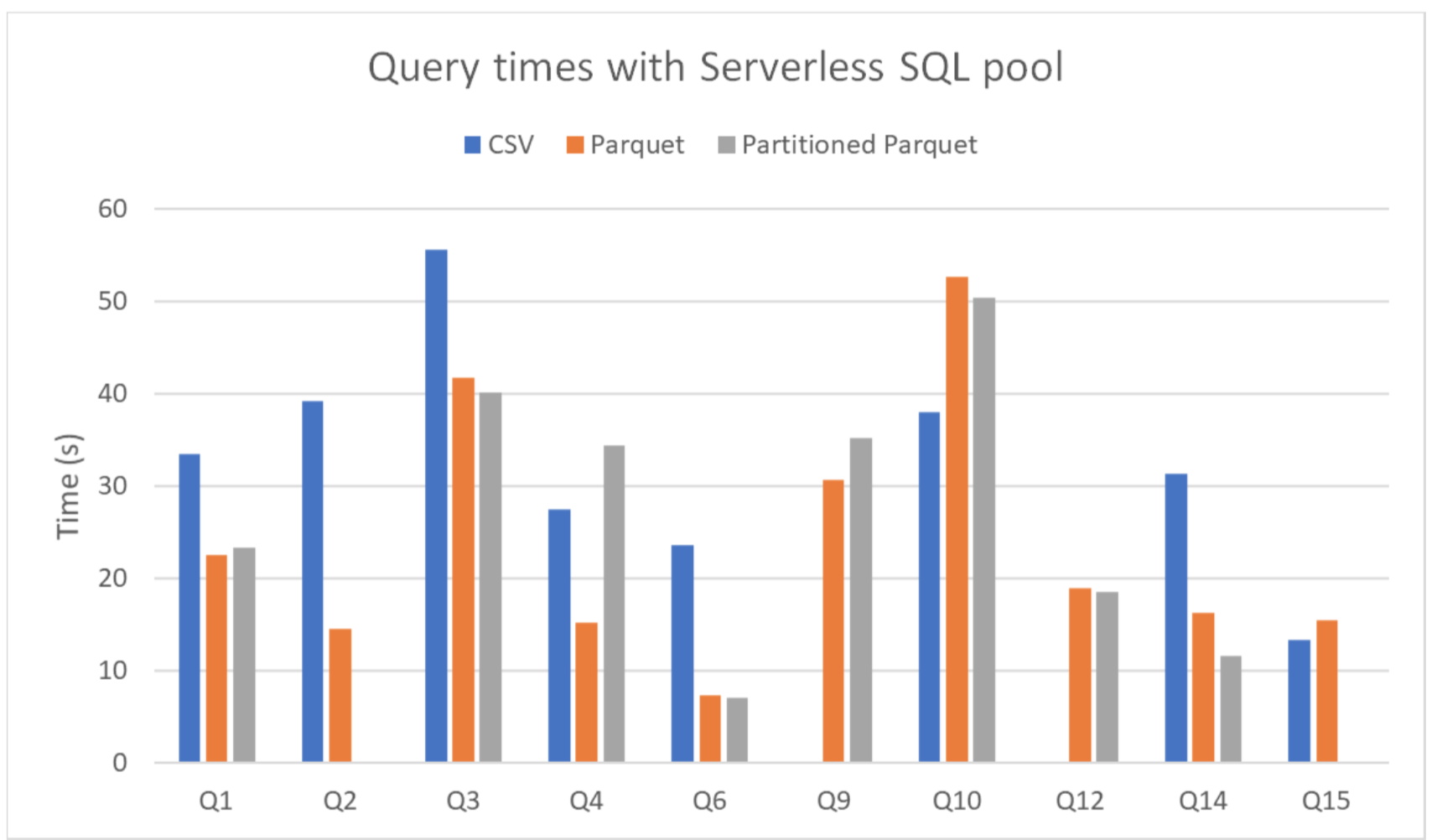
Figure 8
We can see that Parquet files are, in most cases, faster to query than CSV files, while the partitioned tables only reduced the times in specific queries that benefitted from the partition. However, there are also queries where this rule is not followed, due to the automatic scaling of resources in the Serverless SQL Pool.
It is important to keep an eye on the cost, as it is based on the amount of data processed rather than the execution time.
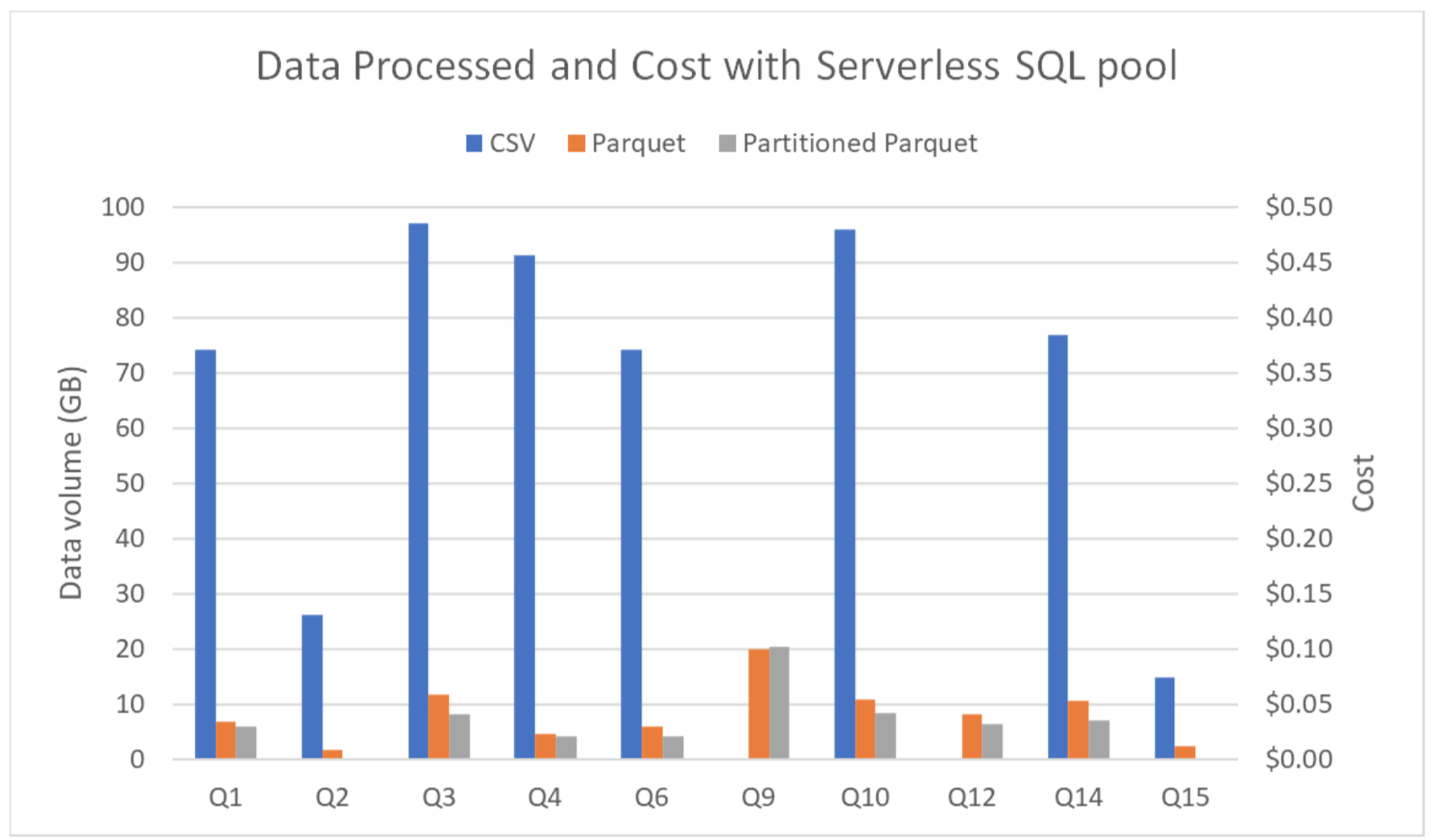
Figure 9
To get an idea of how much each query cost, Azure bills $5 per TB of data processed in the Serverless SQL Pool.
Dedicated SQL Pool & Azure SQL Database
In this case, multiple comparisons were made. From the Dedicated SQL Pool using the DW100c performance level (which translates to a single compute node with 60 GB per data warehouse) we compared the different optimisations within its internal storage as well as how internal storage compares to external. Additionally, we compared the performance of the Dedicated SQL Pool internal storage with an Azure DQL database (with the serverless compute tier maxed out at 2 virtual cores), obtaining the following times:
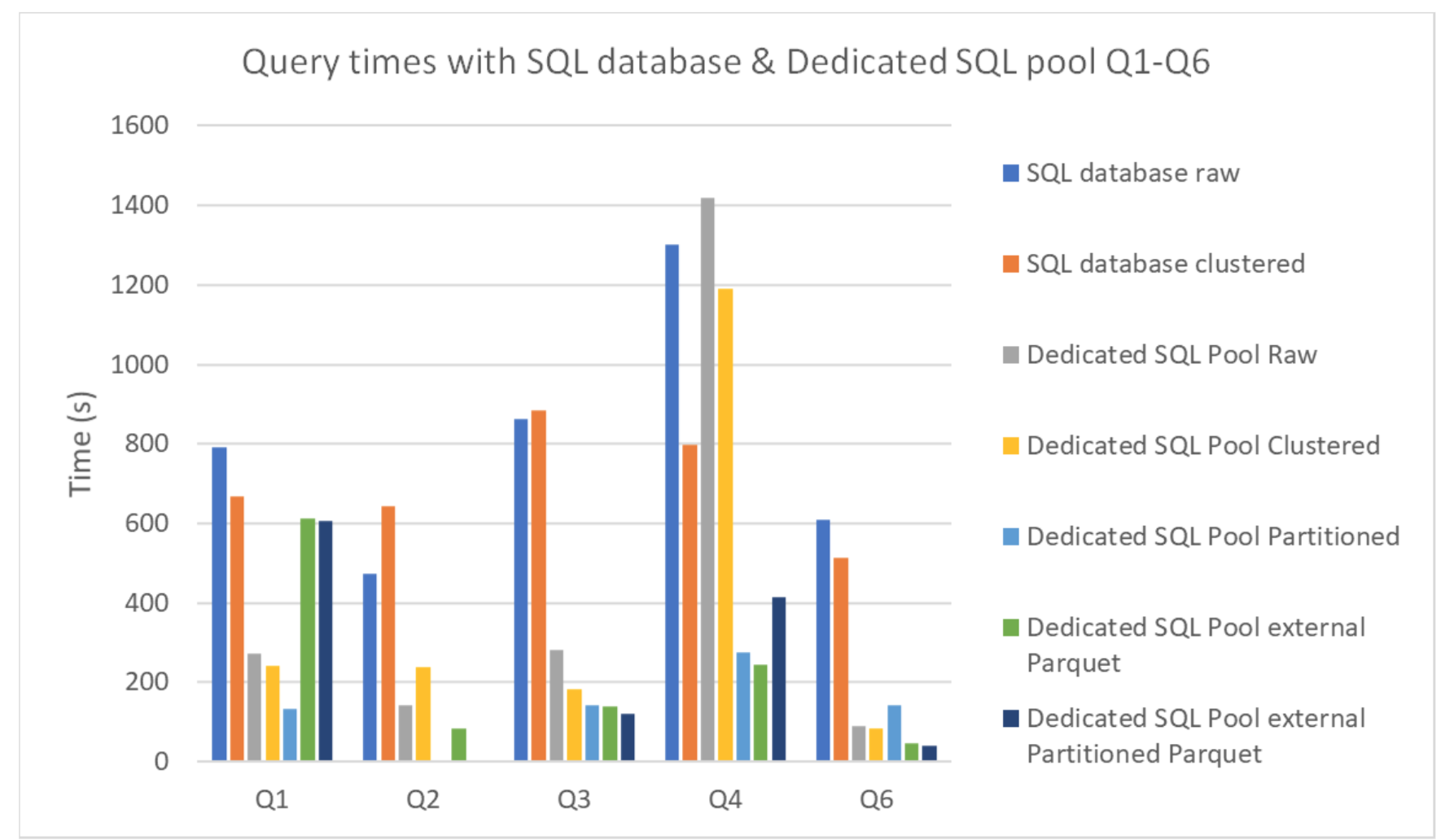
Figure 10
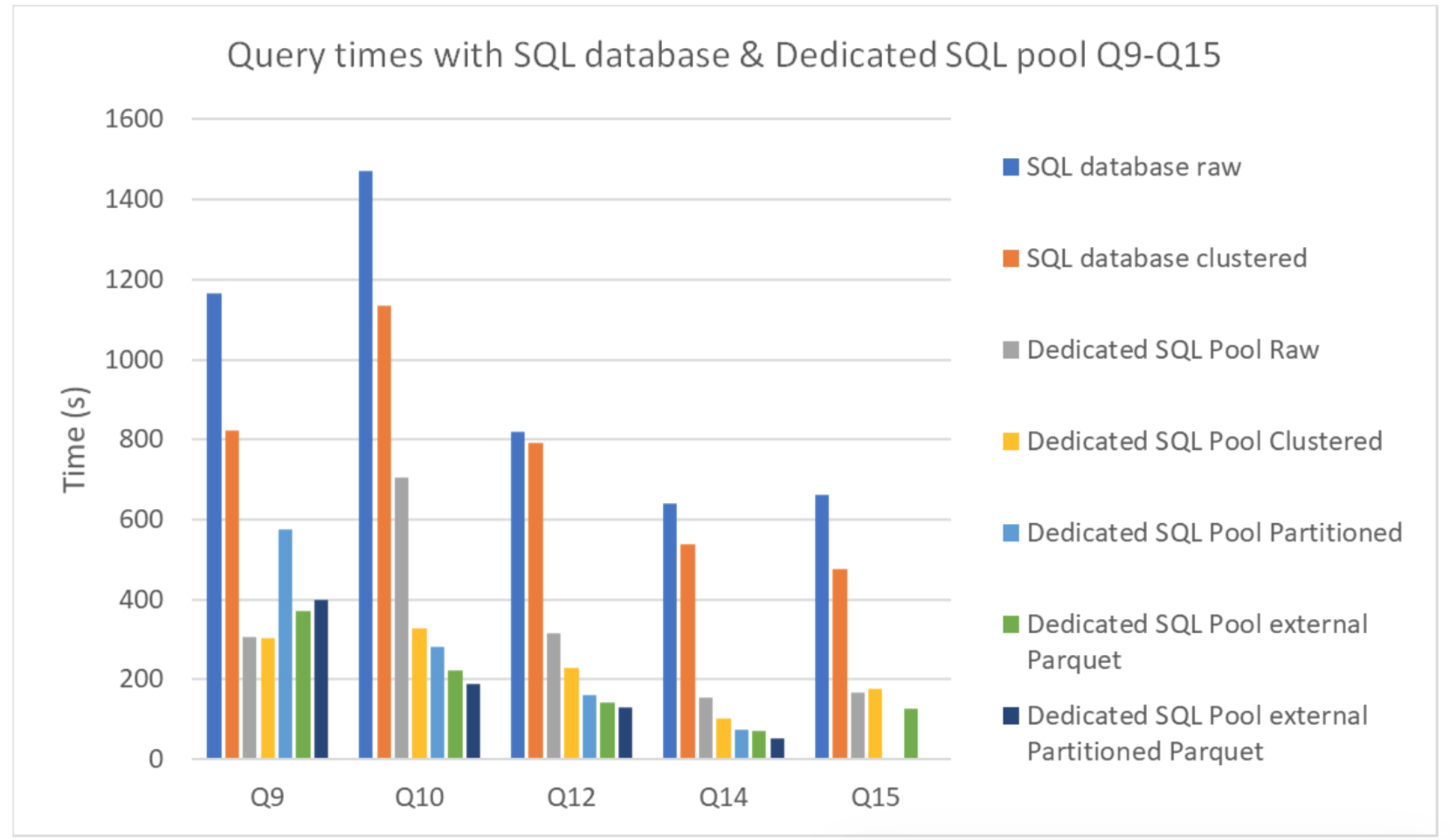
Figure 11
Surprisingly, the Dedicated SQL Pool graphs show how in most cases the external tables led to faster execution times compared to the internal ones. As we’ve seen, these internal tables are located in Azure Storage, which in this case is also where the external tables are; furthermore, their other advantage – using columnar storage – is shared with Parquet tables. As a result, external Parquet tables are technically really similar to internal ones. From the Azure SQL database, we can see how in almost all situations, clustering the indexes implied a reduction in query times.
Finally, we also found that the Dedicated SQL Pool performed better than the Azure SQL database for the dataset and queries we used and for the service sizings we chose. Despite Synapse costing slightly more, the difference was not that significant compared to the differences in performance.
Conclusion
Synapse proved to be an excellent analytics solution, as it is a user-friendly service that allows you to conduct high-performing analytics on big data stored in either files in data lake or in a relational database, provided by the Synapse Dedicated SQL Pool internal storage (formerly Azure SQL Datawarehouse).
We found that its main advantages were the ease of management of the vast variety of resources available in Azure Synapse Analytics through Synapse Studio and its hubs, coupled with its user-friendliness, offering you built-in templates for the most frequent processes in data analysis and warehousing.
It is also worth noting how Synapse uses different pools to solve different use cases. The Serverless SQL Pool is perfect for ad hoc queries, as it requires no extra configuration and the resources scale automatically. However, for a data warehouse solution where the processed data is difficult to predict, it could mean unexpected costs. In a case like that, Synapse offers the Dedicated SQL Pool, where resources are chosen by the user and the costs can be easily measured by the active time.
Moreover, the usage of external tables to query Parquet files in the Dedicated SQL Pool proved to be better than querying its internal table for our use case and test dataset; the first procedure is also cheaper in terms of compute costs. Since the queries are faster, the Dedicated SQL Pool spends less time active; of course, this also saves on storage costs.
We must add that this analysis would stand in a case like ours where we executed a varied set of queries and had a short-lived dataset without exhaustive optimisation. In such a case, the Dedicated SQL Pool can leverage the native Parquet optimisations, making it the preferable format. Nevertheless, if we were building a data warehouse (a long-term database), it would be worth considering the costs (creating indexes and partitions takes time, and time means money) of properly optimising the database in the Dedicated SQL Pool; this method would be recommended if you have to run similar queries periodically.
Comparing the Dedicated SQL Pool and the Azure SQL database, we can see that the Dedicated SQL Pool provided better performance, though its costs per hour were slightly higher. Nevertheless, for big data analytics, there is no doubt that the optimal tool is the Synapse Dedicated SQL Pool; the main handicap here is that the smallest configuration is relatively powerful, which supposes a significant cost, so for smaller amounts of data an Azure SQL database would be a more suitable solution, as it allows more specific configurations.
And with this, we conclude our Synapse blog series. We hope you enjoyed it. For more information on how to use Synapse and how to exploit its functionalities, do not hesitate to get in touch with us. We would be happy to assist and advise you in making the finest decision possible for your business!
