
29 Jun 2022 Building a Lakehouse Architecture with Azure Synapse Analytics
A modern data warehouse lets us easily load any type of data at any scale. This data can then be consumed by end-users through analytical dashboards, operational reports, or advanced analytics. With the rise of Azure Synapse, there’s a growing interest in modernising traditional Business Intelligence (BI) data platforms.
By modernising, we usually think about using Power BI, but this approach only covers the consume layer for end-users: the data models, reports, and dashboards. Power BI can indeed become a modern data platform, offering tools that cover all the stages of building a data warehouse: ingestion and ETL, storage, processing, and serve.
Unfortunately, Power BI isn’t very flexible, so when we need to solve some complex scenarios in the ingestion and/or transformation of data there’s a limited choice of tools. Another problem is access to the data by other teams (data science, for instance) who need to build machine learning (ML) algorithms. Azure Synapse gives us this missing flexibility to build a scalable and agnostic data platform along with Power BI.
In this blog post, we’re going to explain how to build a lakehouse architecture with Azure Synapse from a standard BI approach.
What is Lakehouse Architecture?
The key to understanding this architecture is that we will use a data lake, Azure Data Lake Storage Gen2, to store the data in files, instead of a relational database. It is a low-cost storage solution that contains a set of capabilities dedicated to big data analytics.
This is an example of a high-level lakehouse architecture:
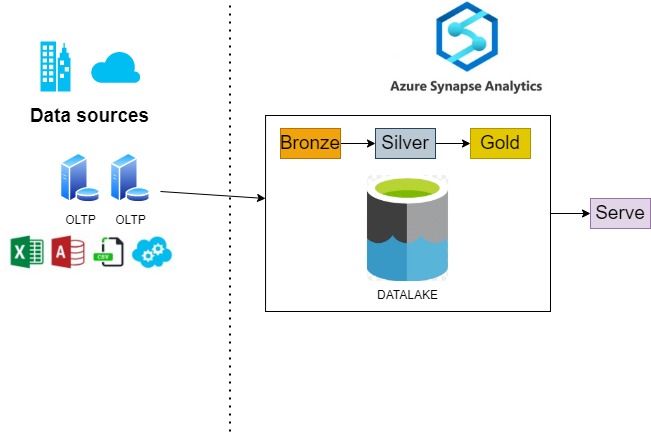
We can see that the data lake is comprised of big pieces: a common method to structure folders within a data lake is to organise data in different folders or layers according to the degree of refinement:
- Bronze (Raw Data): This is the landing area where we will store a copy of the data sources in a file format (CSV, Parquet, JSON, etc.) without any transformation; we will only perform Extract-Load (EL) operations. This layer can also support the storage of any type of data, like videos or photos.
- Silver (Query Ready): This is very similar to what we do in the staging databases in traditional BI: perform some transformations to get cleansed and standardised data. We might face some scenarios like deduplication; it is also where data coming from different sources is merged.
- Gold (Report Ready): The data warehouse with its dimensions and fact tables. We will need to perform Extract-Transform-Load (ETL) operations to load this layer.
The challenge with this approach was how the data lake could handle the capabilities provided by the data warehouse. Delta format turned out to be the solution for providing ACID transactions and CRUD operations (deletes and upserts) to the data lake.
You can read up on the concept of the lakehouse and the history behind it in one of our previous blog posts.
The Databricks team has also published an article explaining the concept and benefits of this architecture.
Building the Lakehouse with Azure Synapse
Azure Synapse Analytics is like a Swiss Army knife, providing us with all the tools we need to load the different layers and make the transformations. It offers a unified analytics platform where you can use and combine different tools and capabilities to perform the ingest and prepare phase. You have the flexibility to choose the right tool for each job/step/process without the complexity of integrating these tools. For example, we can orchestrate the execution of pipelines containing Databricks and/or Spark notebooks:
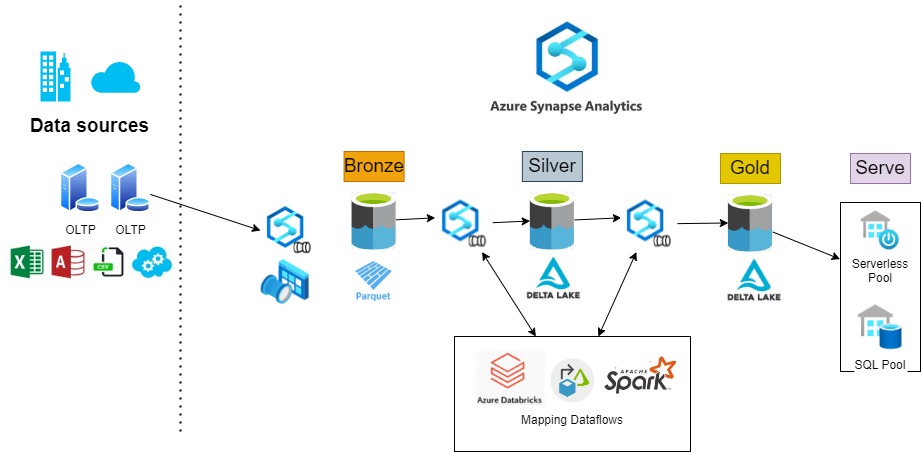
Let’s now look at loading each layer in more detail.
Loading the Raw/Bronze Layer
As we want to copy raw data from our data sources, a great choice for data ingestion is Azure Synapse Pipelines, almost the same as Azure Data Factory (ADF) but with some minor differences (you can see what they are here).
When the data source is a relational store, our recommendation is to use the meta-driven copy task. This is a tool that allows us to build dynamic pipelines that will use the metadata stored in the control table. This metadata contains the name list of the tables to copy with the required synchronised pattern (full or incremental).
In short, we have a built-in framework that acts as an accelerator to our development efforts, and, at the same time, helps us to reduce the number of pipelines and tasks to maintain.
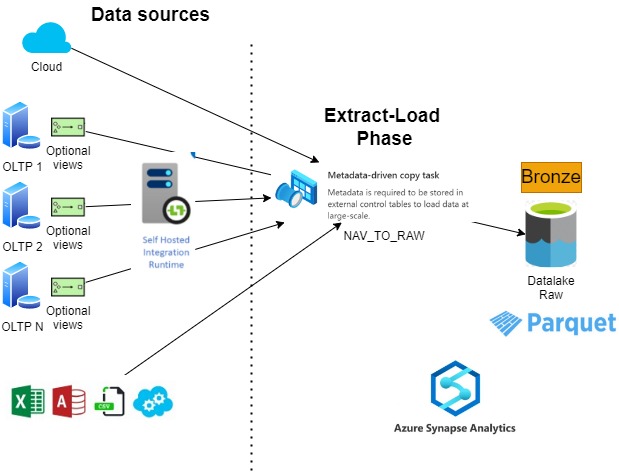
You can find more information in the official documentation.
Loading the Silver and Gold Layers with the SQL Compute
We will need to apply transformations in order to load the Silver and Gold layers. Azure Synapse is a great flexible platform because we can choose and combine different computing environments.
The most common is SQL compute, which comes in two flavours: serverless and dedicated SQL pools. You can catch up on this in our two part series on the topic – you can find Part 1 here and Part 2 here.
With serverless, we can transform data by using T-SQL views and create external tables on top of the data lake; the main difference is that external tables store the transformed data in files in the data lake. With T-SQL views we can even build a logical data warehouse without storing the converted data. At the same time, the serverless pool can act as a serve layer in the same way that Azure SQL Server does.
We can also use T-SQL to ingest data from Azure Blob Storage or Azure Data Lake into tables in the SQL pool. By creating external tables, we can access files as if they were structured tables and load them into tables using PolyBase. There are other options such as BCP and SQL BulkCopy API, but the fastest and most scalable way to load data is through PolyBase. This option will “break” our data lakehouse architecture because we will store the data in tables in a database, instead of the data lake. Of course, the SQL pool is extremely useful for some big data scenarios, for example when we need to serve big data to Power BI in any storage mode: import, direct query, or dual mode.
Loading Silver and Gold for the Lakehouse using Delta Format
We need our data lake to become the data warehouse, and one of the main problems we are going to face is the immense complexity of updating or deleting over Parquet files. However, the Delta format lets us apply these kinds of operations, and moreover it provides ACID transactions to the data lake in the same way as in a database. It is important to clarify that the term Delta lake refers to a data lake with the Delta format.
Azure Synapse Analytics provides the tools needed to implement the lakehouse pattern on top of Azure Data Lake storage. We use Synapse pipelines to orchestrate the load and transformation stages. These pipelines can make use of different technologies that are prepared to work with Delta: Databricks, Mapping Dataflows, and Spark:
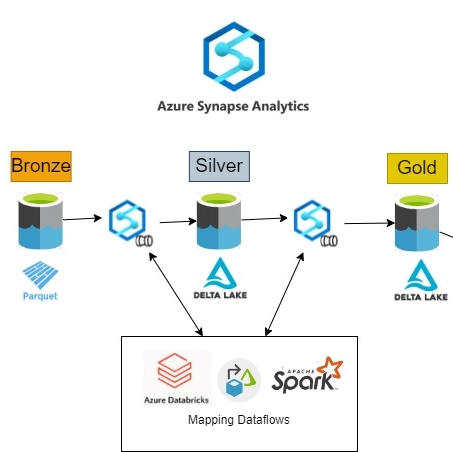
Mapping Dataflows allows us to develop data transformations without writing code. Behind the scenes, there is a translation into Spark notebooks that are executed in scaled-out Spark clusters – that’s why it’s compatible with Delta.
We can also create and configure a serverless Apache Spark pool and write notebooks to transform data using Python, Scala, Java, or C#.
We can access Azure Synapse from Azure Databricks, as there’s a shared Blob storage container that allows the exchange of data between the Databricks cluster and the Synapse instance. There are other scenarios too, like when we have to integrate the information extracted from images and videos into our data warehouse, or our Machine Learning team wants to develop advanced analytics algorithms with Databricks. In cases like these we can forget about complex integration operations!
SQL serverless pool can read files in Delta format but we can’t apply merge operations, so SQL is not (yet) an option to use as the transform compute for Delta files.
Lake Database Utility in Synapse
Recently Synapse added a new feature, Lake database, that provides a relational metadata layer over the files in our data lake. It is a graphical database design interface, where we can define tables, create relationships, and use appropriate naming conversions for tables, columns, and other database objects. You can query these tables using SQL while the storage of the data files is decoupled from the database schema.
Behind the scenes, we are creating Spark tables; we can use the Azure Synapse Apache Spark pool to work with the tables using the Spark SQL API.
At the time of writing, we haven’t been able to incorporate this utility into our lakehouse architecture, since it is only compatible with Parquet and CSV files (so Delta is not supported).
Conclusions
In this article we have reviewed the different options that Azure Synapse Analytics offers us to modernise or build our data platform.
It is important to understand all the pieces of the puzzle to choose the best combination for storage, computing, and serve. It will depend on different factors, like the volume and type of data, the complexity of transformations, the cost of processing and storage, the kind of access needed by applications and other teams (like ML), and the programming experience of the data team: this is why it is important to understand the tools properly, so that we can choose the ones that best suit our needs.
One of the advantages of a lakehouse is that we can easily build a data platform that can accept any data format, and, at the same time, storage is cheap when compared to more traditional options.
And don’t forget that Synapse is not only for big data projects: we can start small but think big in the mid- to long-term, because we can leverage the cloud to scale fast. Wherever and whenever we need the extra power (ingestion, transformation, compute, processing, serve, etc.), we are just a click away.
I hope that you have enjoyed reading this blog post and that you now have a better understanding of Azure Synapse Analytics and how to build a modern data warehouse.
If you require guidance or assistance in choosing the most suitable data platform architecture for your organisation, as well as the technologies and methodologies to implement it, please do not hesitate to contact us, and one of our expert consultants will get straight back to you!
