
07 Ene 2019 Big Data just got smaller with Cloudera 6.1
On 18th December Cloudera Distribution for Hadoop (CDH) 6.1.0 became generally available, offering some important new capabilities. As of version 6.0.0, CDH is based on Hadoop 3 instead of Hadoop 2, but it’s the new version that boasts support for HDFS Erasure Coding (EC). This will be the focus of this blog article, in which we will clarify some concepts and discuss some of the implications of this new feature.
Other relevant new features added to version 6.1.0 of CDH are support for Spark Structured Streaming, the possibility to ingest data directly from Flume into Kudu, and the support (in preview) for Azure Data Lake Storage Gen 2. Other “minor” new features include the possibility to test the network latency of all network links with Cloudera Manager, added support for JBOD in Kafka, and the possibility to deploy clusters with OpenJDK8 (in Hadoop 3 the minimum Java version is 8).
1. Hadoop 2 to Hadoop 3
More than 5 years had passed since the release of Hadoop 2 when Hadoop 3 was released at the end of 2017. Remember that the most relevant change in Hadoop 2, with respect to Hadoop 1, was the introduction of YARN, allowing frameworks other than MapReduce to operate on our Hadoop clusters. That was the cornerstone that enabled Spark, Impala and all the other tools we now love and use daily.
Of all the changes in Hadoop 3, the most significant is the addition of HDFS Erasure Coding as an alternative to Replication to provide storage fault tolerance, allowing us to decrease the size of our clusters as we will see later in this article; but first there are certain considerations that must be taken into account.
2. Erasure Coding in HDFS
Erasure Coding is a method of providing fault tolerance when storing data, to avoid data loss when data disks break or fail. Starting with Hadoop 3, Erasure Coding can be used in HDFS as an alternative to Replication, the main benefit being that the storage overhead can be down to 67% instead of 200% when using Replication (with the default Replication 3). However, the storage saving with EC comes at a cost – more CPU and network usage.
In Replication we simply tackle failures by storing various copies of the data elements (HDFS blocks in HDFS) in different devices, which obviously means considerable storage overhead. N-way Replication (N copies of the data are stored) can tolerate up to N-1 simultaneous failures with a storage efficiency of 1/N. In HDFS, the default is to store data elements with Replication 3 which means it can tolerate 2 failures but has a storage efficiency of one-third, i.e. 200% storage overhead. In HDFS, a positive side effect of Replication is that it improves the chances of “data locality” when processing, which in turn improves storage read throughput.
With EC we tackle failures using a different approach. Instead of storing replicas of the data elements, we store some redundant (parity) data that is the result of an operation on different data elements and that can be used to rebuild these elements if they were to become inaccessible due to a disk failure. The simplest way to do this is with the XOR encoder as depicted in Figure 1. Let’s simplify the data element to single bits: if we have two bits (x and y) and we want to provide fault tolerance, instead of storing replicas of x and y we store a parity bit which is the XOR of x and y. In this case, the storage overhead is 50% and if, for example, we lose x we can reconstruct it from y and the parity bit.
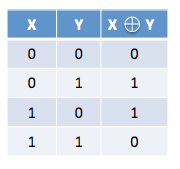
Figure 1: XOR encoder (source: https://blog.cloudera.com/blog/2015/09/introduction-to-hdfs-erasure-coding-in-apache-hadoop/).
Even though it is easy enough to understand, XOR encoding can only tolerate 1 failure so for more robust fault tolerance implementations, Reed-Solomon (RS) encoders are used. RS encoders use more complex linear algebra operations to generate multiple parity cells, and can thus tolerate multiple failures. In this case, the storage overhead is higher than with XOR but provides more data durability (more simultaneous losses are tolerated). For example, using the RS(6,3) encoder (the default in HDFS when using Erasure Coding) we get 67% storage overhead and can tolerate 3 simultaneous failures (better than Replication with factor 3). However, this means increased network and CPU usage, especially relevant in HDFS – now we only have 1 “readable” copy of each data element, so this means less data locality can be leveraged when reading data, which means more network traffic to send data elements between worker nodes. On top of that, when there’s a disk failure, a “recovery” operation must be carried out to “rebuild” the lost data, which leads to extra CPU usage as well as more network traffic.
For a more detailed description about Erasure Coding in HDFS we recommend you take a look at this blog article by Cloudera.
3. Best practices when using Erasure Coding with Cloudera 6
So, Cloudera 6.1.0 includes HDFS Erasure Coding, which is great, but as we mentioned above, certain aspects must be taken into account. Given the novelty of the new feature and its potential implications, here at ClearPeaks we have already observed some concerns and doubts from our customers about what exactly this entails: has Replication gone? Is all the data now Erasure-encoded? How and when should I use Erasure Coding? Does this mean I need smaller clusters? How much smaller? Let’s try to answer these questions.
Replication with factor 3 is still the default fault tolerance mechanism in Hadoop 3 and Cloudera 6.1.0; what has changed is that now Erasure Coding can be used as an alternative fault tolerance mechanism and must be enabled when desired for selected directories.
So, all data is still replicated 3 times by default; however, switching to EC is recommended for certain data access patterns. Considering the impact on storage (much less overhead required) and on CPU and network (higher usage), a balance between when to use Replication or EC must be found – this is now a new lever to play with when implementing a Hadoop-based solution.
The general recommendation by Cloudera is to use Erasure Coding for cold data (data accessed less than once per month) but to keep the hot data in replicated mode. Since fault tolerance mechanisms are specified at directory level, different mechanisms can be used for the same data set. For example, it is possible to have partitioned Hive tables with some partitions (the least accessed) in Erasure Coding, and the other partitions (the most accessed) in Replication mode. In fact, this is also a recommendation by Cloudera.
So, if done properly, combining Replication and Erasure Coding can have a significant impact on storage requirements, meaning smaller clusters (less or smaller storage drives) while minimizing the impact on CPU and network overuse. However, it does not necessarily mean that when sizing a cluster we need to consider 67% overhead instead of 200%, because this will depend on the data access patterns and on the amount of data that is considered “cold”.
Let’s look at a simple example, a fictitious company whose Sales department uses a Cloudera Data Warehouse, mainly for descriptive reporting. The company generates 100 GB per month and keeps data for 10 years (120 months); only data from the last 2 months is used often, so only 1.6% of the data is hot. Without Erasure Coding, when sizing the cluster, we had to estimate 36 PB were required: 120 months x 100 GB/month x 3 replicas. With the introduction of Erasure Coding, we would store current and previous months using Replication (hot) and the rest using Erasure Coding (cold). In this case we would only need 20 PB: (2 months x 100 GB/month x 3 replicas) + (118 months x 100 GB/month x 1.67 EC overhead). So, from 36 to 20 PB, that’s not bad! But note this is a case in which we only consider 1.6% of data to be hot, but in real scenarios there will be different access patterns for different workloads that require a higher percentage of hot data, so the decrease in storage requirements may be not as high as in this example.
In the example given above, note that we would need to develop a processing pipeline that changes the fault tolerance mechanism of the data elements when required (this isn’t automatic). So, a proper combination of Replication and Erasure Coding also implies a certain development effort to create transformation pipelines that switch the fault tolerance mechanisms when required.
Check the Cloudera Data Durability recommendation to understand which EC policies are available and how to set up the layout of racks and nodes for optimal EC – depending on the policy used, the recommendation for the rack and node layout is different.
4. Examples
Enabling and setting Erasure Coding is done through the command-line tool hdfs ec. Check the Cloudera documentation for more information on how to enable EC and check the best practices when using it. The most relevant commands are:
| $> hdfs ec -listPolicies |
listPolicies will list the various available Erasure Coding policies.
| $> hdfs ec -enablePolicy -policy <policy> |
enablePolicy activates a policy, by default only the default policy is enabled. Before being able to use a policy, we must activate it.
| $> hdfs ec -setPolicy -path <directory> [-policy <policyName>] |
setPolicy sets an EC policy to a directory; if the policy optional parameter is not specified the default will be used. It is important to notice than when setting a policy to an existing directory with data, this will not automatically convert the existing data into the different mechanism; only new data will be stored with the new policy.
So, when changing the policy in an existing directory, follow this procedure:
| $> hdfs -mv <directory> <temp_directory> $> hdfs -mkdir <directory> $> hdfs ec -setPolicy -policy RS-3-2-1024k -path <directory> $> hadoop distcp -overwrite -pb -skipcrccheck <temp_directory> <directory> |
This procedure first moves the directory to a temporal location, then recreates the (empty) directory, sets the desired policy and copies back the data using the distcp tool.
Check the Cloudera documentation to learn how to deal with EC with new and existing data managed by Hive. The section that describes how to set EC only for selected “cold” partitions is especially interesting.
Conclusions
CDH 6.1.0 is the first release in Cloudera to support Erasure Coding, the hottest addition in Hadoop 3. When used properly, EC can significantly decrease the storage requirements of Hadoop solutions with minimal performance impact. But as we have seen in this article, there are certain considerations to bear in mind: the main recommendation is to use EC for cold data that is accessed less than once per month, while for frequently accessed data the recommendation is still to use Replication. For partitioned Hive tables we recommend combining both Replication and EC – for frequently accessed partitions use Replication and for cold partitions use EC. Of course, choosing, managing and dynamically switching the fault tolerance mechanisms means extra development efforts but also allows savings since we require smaller clusters (lesser and/or smaller storage devices).
We are excited to see how the introduction of EC in Hadoop enterprise platforms is changing the Big Data landscape and we are also looking forward to seeing how Cloudera 6 evolves in the coming months and years, as well as to the next major Cloudera release (7?) that will perhaps be the first where we will effectively see the merger between Cloudera and Hortonworks, a real game-changer in Big Data.
Here at ClearPeaks we are experts on Business Intelligence, Advanced Analytics and Big Data solutions using the latest market-leader technologies. If you believe our expertise can be of use to you, please contact us and we will be happy to help.