14 Jul 2015 Big Data Ecosystem – Spark and Tableau
In this article we give you the big picture of how Big Data fits in your actual BI architecture and how to connect Tableau to Spark to enrich your current BI reports and dashboards with data that you were not able to analyse before. Give your reports and dashboards a 360º view, and understand what, when, why, who, where and how. After reading this article you will understand what Big Data can offer you and you will be able to load your own data into HDFS and perform your analysis on it using Tableau powered by Apache Spark.
1. The Big Data ecosystem
When considering a Big Data solution, it is important to keep in mind the architecture of a traditional BI system and how Big Data comes into play. Until now, basically we have been working with structured data coming mainly from RDBMS loaded into a DWH, ready to be analysed and shown to the end user. Before considering how this structure may change when taking Big Data into the field, one could wonder how exactly the use of Big Data technology benefits my current solution. Using this technology allows the system to process higher volumes of data much faster, which can be more diverse, giving the chance to efficiently and safely extract information from data that a traditional solution can’t (high fault tolerance). In addition, using Big Data permits the hardware structure to grow horizontally, which is more economical and flexible. So, how does Big Data enter this ecosystem? Well, the main architecture concepts are quite the same, but there are big changes. The main differences are a whole new set of data sources, specifically non-structured and a completely new environment to store and process data.
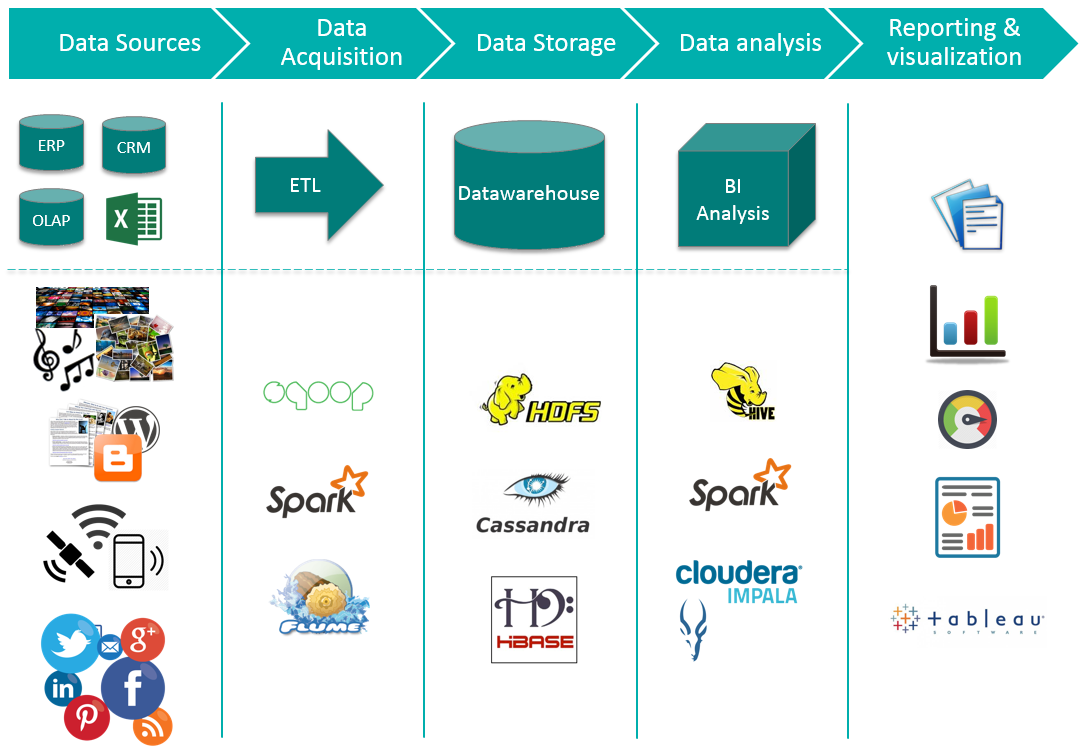
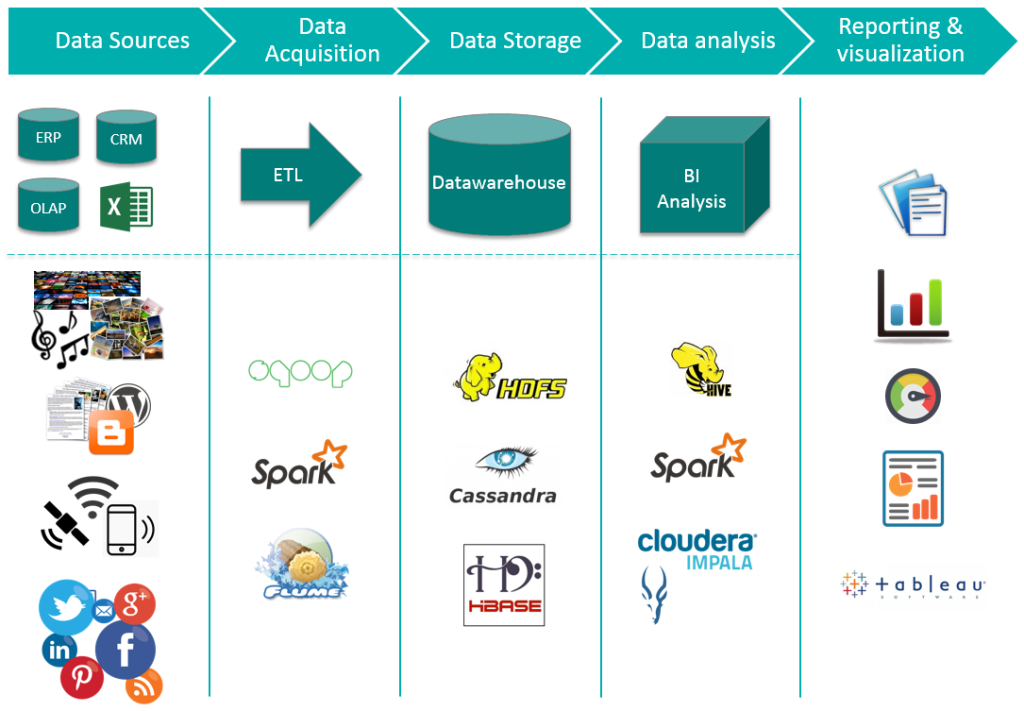
In the picture above, at the top we have our traditional BI architecture. Below we can see how the new Big Data architecture still preserves the same concepts, Data Acquisition, Data Storage, etc. We are showing a few Big Data tools from the ones available in Apache Hadoop project. What is important to point out is that Reporting & visualization must be combined. We must combine data from traditional and Big Data storage to provide a 360º view, which is where the true value resides. To combine it there are different options. We could administer our aggregation calculations from HDFS, Cassandra data etc to feed the Data warehouse with information we were unable to compute before. Or we could use a reporting & visualization tool capable of combining traditional Data warehouse and Big Data storage or engines, like Tableau does.
2. Big Data implementation: Apache Spark + Tableau
When approaching a Big Data implementation, there are quite a lot of different options and possibilities available, from new data sources and connectors to the final visualization layer, passing through the cluster and its components for storing and processing data. A good approach to a Big Data solution is the combination of Apache Spark for processing in Hadoop clusters consuming data from storage systems such as HDFS, Cassandra, Hbase or S3, and Tableau such as the visualization software that will make the information available to the end users. Spark has demonstrated a great improvement in terms of performance compared to the original Hadoop’s MapReduce model. It also stands out as a one-component solution for Big Data processing, with support for ETL, interactive queries, advanced analytics and streaming. The result is a unified engine for Big Data that stands out in low-latency applications and iterative computations, where fast performance is required, like iterative processing, interactive querying, large-scale batch computations, streaming or graph computations.
Tableau is growing really quickly, and has already proven to be one of the most powerful data discovery and visualisation tools. It has connectors to nearly any data source such as Excel, corporate Data Warehouse or SparkSQL. But where Tableau really stands out is when transforming data into compelling and interactive dashboards and visualizations through its intuitive user interface. The combination of Apache Spark with Tableau stands out as a complete end-to-end Big Data solution, relying on Spark’s capabilities for processing the data and Tableau’s expertise for visualisation. Integrating Tableau with Apache Spark gives the chance to visually analyse Big Data in an easy and business-friendly way, no Spark SQL code is needed here.
3. Connecting Tableau with Apache Spark
Here, at ClearPeaks, we are convinced that connecting Apache Spark to Tableau is one of the best approaches for processing and visualising Big Data. So, how does this solution work? We are already working with this technology, and are proud to show a demonstration of Tableau connected to Apache Spark. Prerequisites:
- Tableau Desktop, any version that supports SparkSQL connector.
- Apache Spark installed either on your machine or on an accessible cluster.
a. Integration
Tableau uses a specific SparkSQL connector, which communicates with Spark Thrift Server to finally use Apache Spark engine.

b. Software components
Tableau Desktop
Apache Spark Driver for ODBC with SQL Connector
Apache Spark (includes Spark Thrift Server)
c. Set up the environment
Installing Tableau Desktop and Apache Spark is out of the scope of this article. We assume that you have already installed Tableau Desktop and Apache Spark. Apache Spark needs to be built with Hive support, i.e.: adding –Phive and –Phive-thriftserver profiles to your build options. More details here.
d. Install Apache Spark Driver for ODBC with SQL Connector
Install Apache Spark connector from Simba webpage. They are offering a free trial period which can be used to follow this article. It has an installation wizard which makes installation a straightforward process.
e. Configure and start Apache Spark Thrift Server
Configuration files
Spark Thrift Server uses Hive Metastore by default unless another database is specified. We need to copy hive-site.xml config file from Hive to Spark conf folder.
cp /etc/hive/hive-site.xml /usr/lib/spark/conf/
park needs access to Hive libraries in order to connect to Hive Metastore. If those libraries are not already in Spark CLASSPATH variable, they need to be added. Add the following line to /usr/lib/spark/bin/compute-classpath.sh
CLASSPATH=“$CLASSPATH:/usr/lib/hive/lib/*”
Start Apache Spark Thrift Server
We can start Spark Thrift Server with the following command:
./sbin/start-thriftserver.sh –master <master-uri>
<master-uri> might be yarn-cluster if you are running yarn, or spark://host:7077 if you are running spark in standalone mode. Additionally, you can specify the host and port using the following properties:
./sbin/start-thriftserver.sh \ –hiveconf hive.server2.thrift.port=<listening-port> \ –hiveconf hive.server2.thrift.bind.host=<listening-host> \ –master <master-uri>
To check if Spark Thrift Server has started successfully you can look at Thrift Server log. <thriftserver-log-file> is shown after starting Spark Thrift Server in console output.
tail -f <thriftserver-log-file>
Spark Thrift Server is ready to serve requests as soon as the log file shows the following lines: INFO AbstractService: Service:ThriftBinaryCLIService is started. INFO AbstractService: Service:HiveServer2 is started. INFO HiveThriftServer2: HiveThriftServer2 started INFO ThriftCLIService: ThriftBinaryCLIService listening on 0.0.0.0/0.0.0.0:10000
f. Connect Tableau using SparkSQL connector
Start Tableau and select option to connect to Spark SQL. Select the appropriate Type depending on your Spark version and the appropriate Authentication depending on your security.
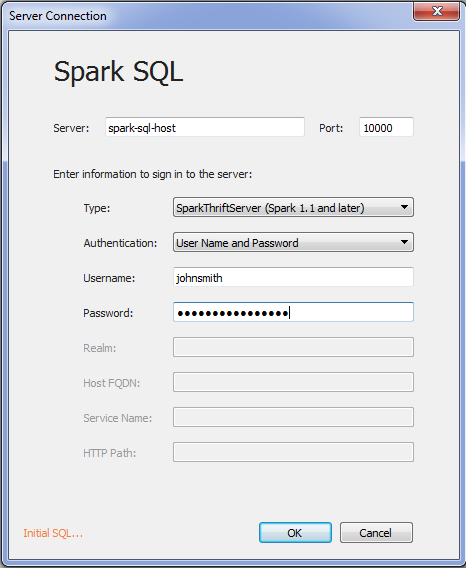
The next steps are selecting schema, tables and desired relations, the same as when using any other Tableau connector. Now you are able to run your own analysis on Big Data powered by Spark!
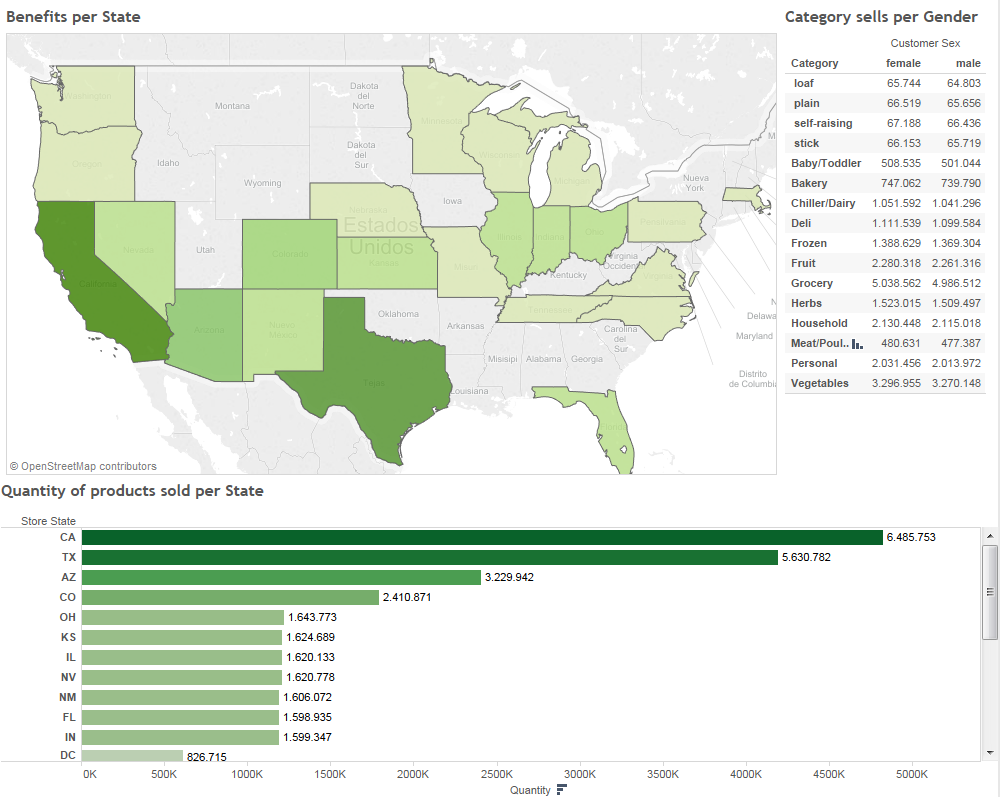
The dashboard above has been created in Tableau 9.0 after following the instructions provided. Apache Spark is used by Tableau to transparently retrieve and perform calculations over our data stored in HDFS. Show us a capture of your Spark powered dashboards and reports. Share with us your impressions about Apache Spark and Tableau tandem in the comment section at the bottom. Happy analytics!
Bonus: Add data to Hive Metastore to consume it in Tableau
If you are not familiar with the process of loading data to Hive Metastore you will find this section very useful. This section describes how to load your csv from your file system to Hive Metastore. After this process you will be able to use it from Tableau using the process described in this article.
For this example we are going to use the following file that contains the well-known employee example:
my_employees.csv
123234877,Michael,Rogers, IT 152934485,Anand,Manikutty,IT 222364883,Carol,Smith,Accounting 326587417,Joe,Stevens,Accounting 332154719,Mary-Anne,Foster,IT 332569843,George,ODonnell,Research 546523478,John,Doe,Human Resources 631231482,David,Smith,Research 654873219,Zacary,Efron,Human Resources 745685214,Eric,Goldsmith,Human Resources 845657245,Elizabeth,Doe,IT 845657246,Kumar,Swamy,IT
As we can see it follows the schema: Employee Id, Name, Last Name, and Department. We are going to use beeline to connect to Thrift JDBC Server. Beeline is shipped with Spark and Hive. Start beeline from the command line Beeline Connect to Thrift JDBC Server.
beeline> !connect jdbc:hive2://localhost:10000
Create the table and specify the schema of it:
beeline> CREATE TABLE employees (employee_id INT, name STRING, last_name STRING, department STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’;
Now you are ready to load your my_employees.csv file into the previously created table:
beeline> LOAD DATA LOCAL INPATH ‘/home/user/my_employees.csv’ INTO TABLE employees;
We can even perform operations over employees table using beeline:
beeline> SELECT COUNT(*) FROM employees;
Conclusion
If you want to give your reports and dashboards a 360º view, and understand what, when, why, who, where and how check our Big Data Services and contact us!
Eduard Gil & Pol Oliva