
29 Apr 2020 Big Data Analytics in Amazon Web Services
Designing a big data pipeline in Amazon Web Services (AWS) can be a challenging task for any company due to the large number of services this cloud provider offers. ClearPeaks has a wealth of experience in this process with a wide range of customers with different business requirements. In this article we will guide you through the process of architecting a big data platform in AWS, introducing a use case that we have tackled recently.
1. Introduction to the Case Study
For reasons of confidentiality, we are not going to describe our client’s use case nor show their data; instead, we will use the data generated by New York Citi Bike, the bike-sharing system in New York. For the purpose of this blog, we will also adapt the use case of our real customer to something Citi Bike may have faced. Actually, we have already used the Citi Bike dataset in the past in our ‘Big Data made easy’ series, where we went through a variety of big data technologies:
- Working with Talend Open Studio for Big Data and Zoomdata to create interactive dashboards with a Cloudera cluster.
- Working with StreamSets to ingest and transform real-time data with a Cloudera cluster.
- Working with Arcadia Data to create interactive dashboards natively with a Cloudera cluster.
- Working with Datameer to ease end-to-end operations in a Cloudera cluster.
As mentioned, Citi Bike is a bike-sharing service in New York which makes their trip data available to anyone. Users can pick up a bike from any of the stations at any time of the day and leave it in another station, just by using an app in their smartphones. Planning the logistics and operations of the fleet is very important for the company; they rely heavily on their data to know which stations might be empty and which at full capacity, in order to deploy their vans to relocate the bikes around the city. They built their data architecture using AWS in the first years of their existence, with Snowflake as their data warehouse. Their current process loads and transforms data to their data warehouse 5 times a day from the mobile application for the user data, from the stations for capacity planning, and from other third-party APIs. They have been expanding to many new cities over the past months and, in consequence, so have their needs in terms of data storage and compute resources. Moreover, they are planning to start analysing near real-time data to improve their operations.
Our client has asked us, to design and implement their new data architecture in the cloud, using AWS, building upon their existing platform. At ClearPeaks we provide analytics consulting for a wide range of client profiles, getting exposure to data architectures of companies who are just starting out with analytics all the way up to some of the most advanced data organizations in the world. Over recent months we have been seeing more and more companies starting their journey in the cloud and many of them do it with AWS. This article summarizes ClearPeaks’ experience while implementing a batch architecture in AWS.
2. Requirements
The main customer requirements for the design of the batch data platform were the following:
- Data needs to be refreshed 5 times a day: the operations department needs the latest capacity of stations to plan the relocation of bikes for the next day.
- The data warehouse where data is loaded is Snowflake: the company is already using Snowflake data warehouse and plans on keeping it.
- Services must follow an elastic scale approach: the company wants to use services that are fully managed, either PaaS or SaaS over IaaS service; their end goad is to reduce IT department maintenance tasks.
3. Introduction to AWS
AWS is the Amazon cloud data platform that provides on-demand cloud computing resources, services and APIs to individuals, companies, and governments, on a metered pay-as-you-go basis.
Amazon provides a set of web services completely hosted on cloud in a single account; these services are easy to manage through the AWS console. The services are paid for on demand, helping us to scale up the resources needed and to create a budget plan that can be managed and modified easily; it also allows the removal and addition of new services on demand.
To get a sense of all the different services and applications that you can deploy in AWS, below you can find all the available services in the platform, grouped by categories. We have highlighted the ones that are used for data and analytics applications.
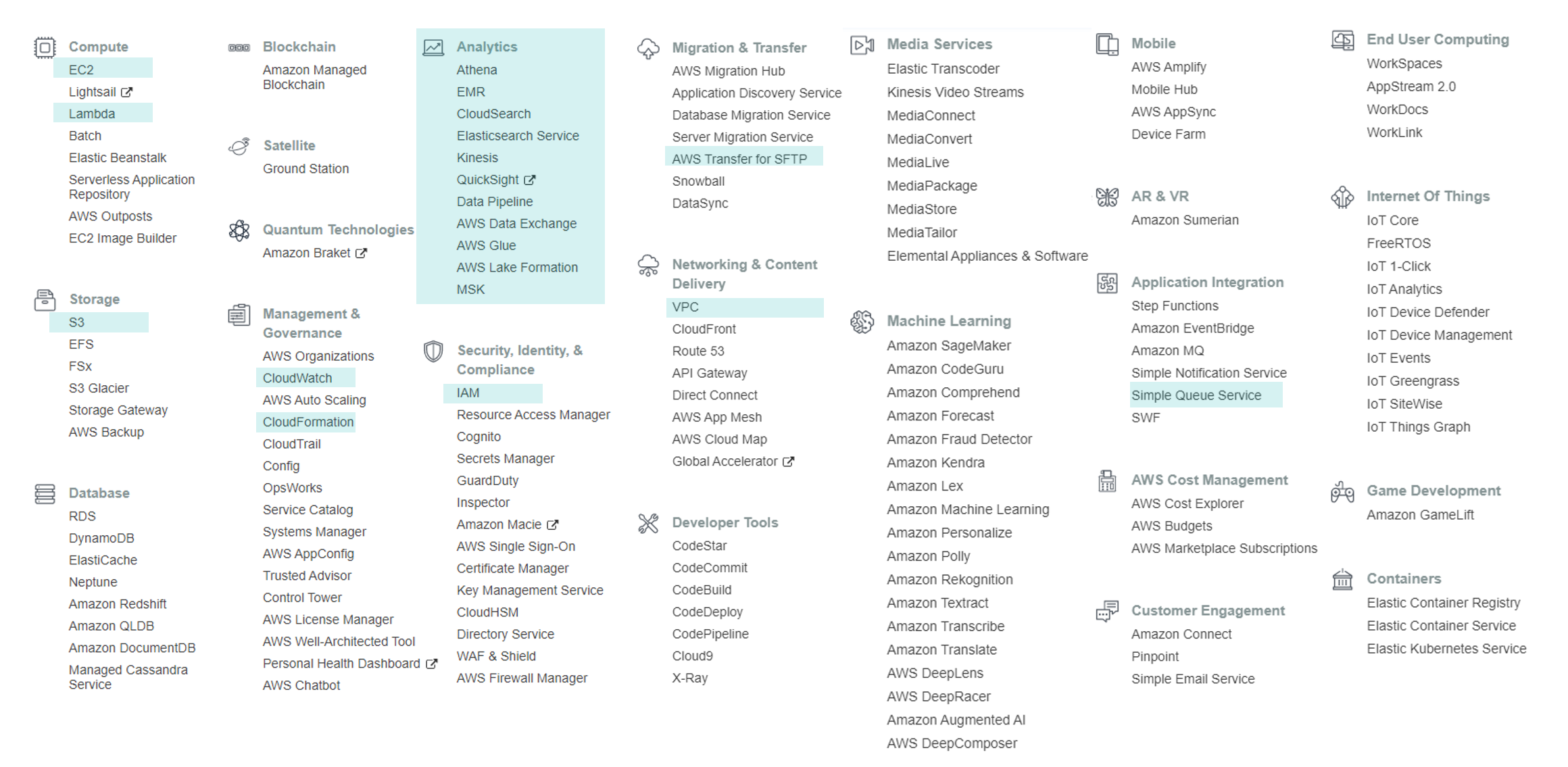
Figure 1: AWS Services grouped by category
In addition to the Analytics and Databases services, we have also relied on:
From the large list of services available in AWS, some of the most important ones to build your data platform and BI infrastructure in the cloud are:
- EC2 (used to host the servers, ETL and reporting software).
- S3 (file storage service).
- Redshift (data warehouse).
4. Batch platform architecture
In this section we will go over the architecture that was built in AWS, explaining each of the different services, their features, and the best practices to use them. At this stage, it is important to take into account the requirements of the project: the data had to be available in the Snowflake data warehouse five times a day, and the customer preferred PaaS services. The architecture that we built consisted of the following elements:
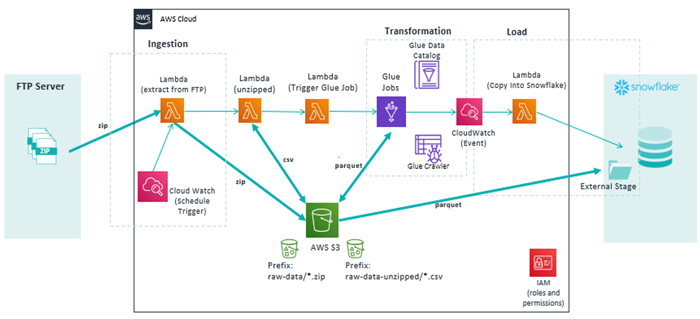
Figure 2: Overview of the architecture of the data platform
At first glance, it might be overwhelming to see so many different logos and connections between services, but we want to show the image now so you can have an initial high-level overview of the architecture. We will first describe the basics of the data flow from left to right and then we will look into the details of each step and the use cases of the different services employed.
Starting at the left of the image, the data was made available from the software that managed the stations through an FTP Server. Five times every day, their tool uploads a zip file containing all the trips that took place during the last time interval. The pipeline takes this file and makes some transformations to the data to calculate, for example, the capacity of the stations. Finally, the data is loaded into their data warehouse and consumed by the BI tools.
4.1. Ingestion
The first step in every data pipeline is the ingestion of the data, in this case into AWS. The services that we used in this part of the process are the following:
- FTP is running on premise so we cannot rely on “AWS FTP Transfer” service because the client wants to keep the FTP on premise.
- Lambda is a serverless compute resource, and lets you run code without provisioning or managing servers. You pay only for the compute time you consume (for a maximum of 15 minutes). The languages supported are: Node.js, Python, Java, C#, Go, PowerShell and Ruby.
- Cloud Watch is a monitoring and observability service. It allows developers to monitor different metrics of the deployed services. It is also useful to execute triggers over other services. In our case, we used it to schedule a trigger over the first Lambda function.
- S3 is Amazon’s storage flagship. It is a simple storage service that offers an extremely durable, highly available, and infinitely scalable data storage infrastructure at very low cost.
The following image describes the steps in the ingestion workflow:

Figure 3: Ingestion workflow
Firstly, a Cloud Watch trigger scheduled to run five times a day (once the files are available in the FTP server) executes a Lambda function consisting of a Python script that connects to the FTP server and downloads the most recent file. It then unzips the file and uploads it to a folder in S3.
AWS provides another service called Transfer for SFTP, a fully-managed highly available SFTP service which integrates tightly with S3 and allows you to write AWS Lambda functions to build an “intelligent” FTP site that processes incoming files as soon as they are uploaded, and connects easily to your existing data ingestion process. However, it does not fit in our use case as we consider an FTP running on premise. This service sets up an FTP Server from scratch; it does not connect to an external FTP server, so does not exactly meet our requirements.
Once we have the file unzipped and ready to be processed, we have to trigger the service that will do the transformations of the data: AWS Glue. To do that, we must use another Lambda function which triggers a Glue job through the API that AWS offers to interact with the console programmatically.
This Lambda function is triggered when a new file arrives to the unzipped folder in the S3 file. When the first Lambda function has ingested the file from the FTP server, it unzips it and uploads it back to S3; a trigger is made to the second function. Lambda functions have many triggers available for many services within AWS, one of the reasons why Lambda is used a lot for integrating services and processes together.
Figure 4: Different options to trigger a Lambda function
In our case, we used the trigger that is executed when a new file arrives to a specified path in S3.
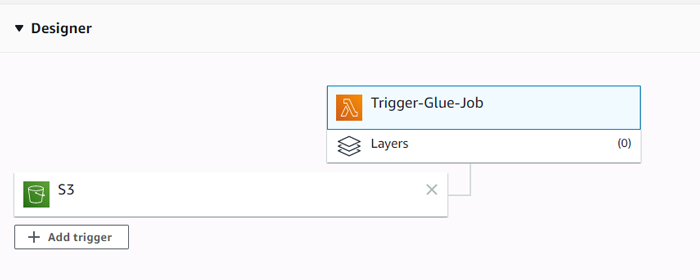
Figure 5: When a new file arrives to S3, this Lambda function is executed
This last Lambda function uses Amazon’s API to execute a trigger over another service which will do the necessary transformations: AWS Glue.
4.2. Transformation
In order to clean and transform the data, we need an engine to compute these tasks, and for big data applications we need a cluster with some software to optimize the workloads for parallel processing. There are 3 major services in AWS that allow you to do this:
- AWS Glue is a fully-managed extract, transform, and load (ETL) service that makes it easy for customers to prepare and load their data for analytics. As mentioned, it is a fully-managed (PaaS) service which deploys a Spark cluster for every job that you need to perform on your data. You don’t need to worry about deploying any infrastructure or managing any of the instances behind it.
- EMR (Elastic Map Reduce): Amazon EMR provisions a hosted Hadoop cluster. It is a similar service to Azure HDInsight. Unlike Glue, once the infrastructure is deployed you can manage the cluster via the HUE portal.
- Databricks in AWS is a unified data analytics platform on top of Apache Spark for accelerating innovation across data science, data engineering, and business analytics, integrated with your AWS infrastructure. However, it is not provided as a native AWS service, so you must purchase it via the Marketplace.
As you might have seen in the architecture diagram, we chose to use AWS Glue. Databricks was discarded due to the requirement to use native AWS services.
Choosing between EMR and AWS Glue is more challenging because they have similar use cases. The decision might depend on the requirements of your project and other external factors, such as the experience of the developers or company policies.
In our context, AWS Glue was chosen because it is completely managed, you can run the cluster on demand, it integrates better with the rest of AWS services and it also provides a Data Catalog. On the other hand, EMR might require more admin work in order to manage the cluster deployed by AWS. All said, both are great options to process your data effectively. However, it is not recommendable to use AWS Glue as a NoSQL Database, in case you need multiple engines instead of Spark, or if you need complex orchestration.

Figure 6: Basic elements in AWS Glue service and how they interact with each other
Once in AWS Glue, jobs can be developed in Python or Scala and executed on demand. Jobs can also be orchestrated using ‘Workflows’, a feature that was recently released. Another important feature of Glue is its Data Catalog, which allows you to easily share table metadata across AWS Services and access the data from the jobs you script. Crawlers are responsible for scanning through your files and databases to populate the Data Catalog.
Data Catalog: a collection of metadata, combined with data management and search tools, which helps analysts and other data users to find the data that they need, acting as an inventory of available data in the platform.
Crawler: you can use a crawler to populate the AWS Glue Data Catalog with tables. This is the primary method used by most AWS Glue users. A crawler can crawl multiple data stores in a single run. Upon completion, the crawler creates or updates one or more tables in your Data Catalog.
The typical workflow when you start working with Glue might look like this:

Figure 7: These are the steps to take when working with AWS Glue
You start populating the Data Catalog, then you author your Pyspark jobs and schedule them together with the crawlers to keep updating the metadata. All these steps are orchestrated by the workflows. The following image shows an example of a workflow that concatenates jobs and crawlers:
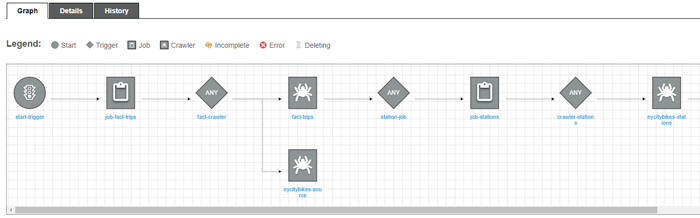
Figure 8: Screenshot of the workflow feature in AWS Glue
Finally, these are some of the limitations we found while working with AWS Glue:
- Glue jobs took 10 minutes to provision the cluster before starting the execution (AWS is working on getting down to 1 minute). In our case, execution time wasn’t an issue, but if it is you might consider using EMR instead.
- Managing the software development lifecycle is hard with Glue Jobs. If you want to interactively develop, test and debug jobs through notebooks or an IDE, you need to deploy a development endpoint which will provision a cluster to run your tasks.
- There is some management and cost overhead in deploying a development environment; you can read a tutorial on how to deploy them here.
- The Development Endpoint is expensive, especially if you do not have a team of several developers that are using it. Billing for a development endpoint is based on the Data Processing Unit (DPU) hours used during the entire time it remains in the ‘ready’ state; to stop charges you need to delete the endpoint. Cost starts at approx $20 per day.
- The options for orchestrating the jobs and crawlers are very limited compared with Azure Data Factory V2, Informatica or Talend.
4.3. Load to Snowflake
Finally, the last step of the pipeline is to take the files that have been processed by Glue and load them into a Snowflake table. Again, we will use a Lambda function to script a Python file that will send a SQL statement to Snowflake to copy the data. The following diagram explains the process:
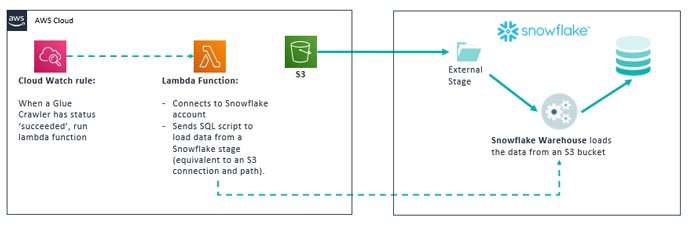
Figure 9: Workflow to load data to Snowflake data warehouse
Before sending data to Snowflake, we have to create a stage in Snowflake that points to AWS S3. If you want to find out more about how to configure these steps or about Snowflake in general, go to this blog post entry.
We first trigger a Lambda using an event-rule of Cloud Watch. The rule is set to trigger the function when the last crawler of the Glue workflow has finished running; then the Lambda function will use Snowflake’s Python connector to authenticate into the account and send a SQL statement that copies the data from S3 to a Snowflake table.
Last but not least, once the data is available in Snowflake DWH, it is ready to get consumed via a visualization tool or a database client.
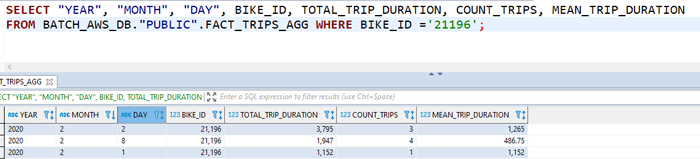
Figure 10: We can connect from any database client to our Snowflake tables
Conclusion
In this blog article we have explained AWS and the different resources available to build a batch data pipeline. It provides a broad set of tools to build a data platform, which will fulfil almost all possible requirements when it comes to your data platform.
As we have seen, the batch platform might differ from other data integrators, tools and orchestrators like Microsoft Azure Data Factory v2 , Talend, and Informatica, where you already have a lot of pre-defined connectors, operations and graphic interfaces which speed up the process. Here are some tips based on our experience using the platform:
- As most of the services follow a pay-as-you-go model, and as a developer you will not receive cost notification, it is important to bear the following in mind:
- Do not leave services active if not required. Delete and recreate.
- Do not over-size the services.
- Check the frequency of executions.
- Configure a suspend or termination time whenever possible.
- AWS services integrate very well with each other, but lack external connections to 3rd party tools and other software services. For example, in Azure Data Factory (orchestration service) you can find many connectors to 3rd party tools.
- AWS has a very granular Identity, Authorization and Management service (IAM). It requires a lot of tuning that might become rather overwhelming. Nevertheless, AWS has put a lot of effort into developing wizards and templates to automatically set up permissions and roles when it comes to the integration of services.
- AWS releases new features and services at a rapid pace, so it is important to keep up to date. At the time of editing this blog article for example, AWS launched AWS AppFlow, a fully managed integration service that enables you to securely transfer data between popular Cloud SaaS offerings (Salesforce, Infor Nexus, Marketo, ServiceNow, Slack, etc.) and AWS services, making it easier to ingest data from these applications into AWS.
AWS provides a wealth of services that can be used to build a batch data platform, like ‘Lego’ pieces that you can use to build anything you can imagine. Depending on the requirements of the project and data needs, you might find yourself choosing similar services that have slightly different features that adjust better to the requirements. Nonetheless, we hope you now have a better understanding of the different services and their use cases.
For more information on how to deal with and get the most from Snowflake, and thus obtain deeper insights into your business, don’t hesitate to contact us! We will be happy to discuss your situation and orient you towards the best approach for your specific needs.
