
17 Jul 2024 Best Practices for Building A Databricks Lakehouse Data Platform
Lakehouse architecture has become a solid option when it comes to designing your enterprise data platform. This data management framework seamlessly integrates the cost-efficiency and limitless scalability of data lakes with the advanced capabilities of data warehousing, including ACID transactions, data governance, and a powerful querying engine. This combination makes Lakehouse data platforms one of the best solutions for handling your BI and ML use cases.
When talking about Lakehouse platforms, the first provider that comes to mind is Databricks, as they introduced the concept in their 2020 paper Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics.
In this blog post, we are going to explain all the factors you should consider and the best practices to follow when building a Databricks Lakehouse data platform.
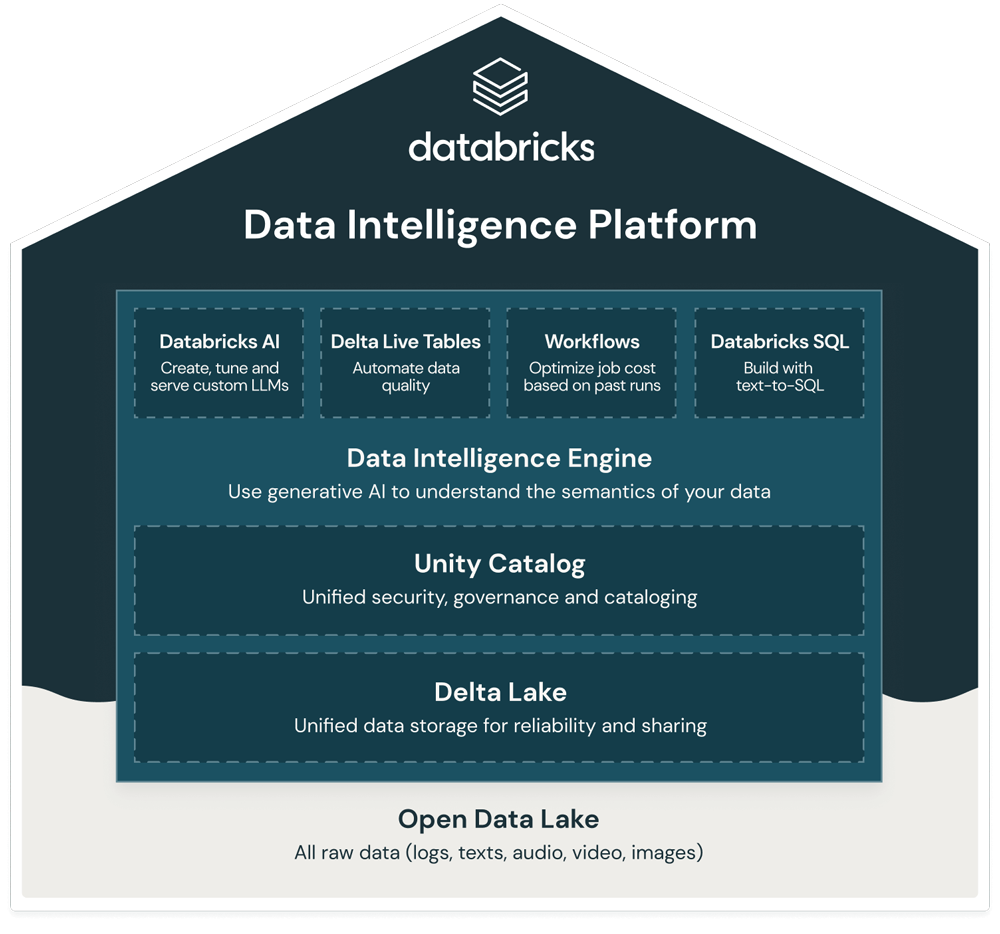
Figure 1: Databricks Data Intelligence Platform
Considerations When Architecting a Data Platform
In our previous two-part post about how to choose your data platform, we explained the variables to consider when designing a data platform. In this section, we are going to delve into the various aspects required to build a Databricks-based data platform properly. However, we should first look at some key points.
The cloud provider you choose to implement your data platform is one of the first considerations. Most companies already have a preferred cloud provider to host most of their IT infrastructure. With Databricks this choice is flexible, as it is multi-cloud and can be used with any—or all—of the public cloud providers (AWS, Azure, GCP). In this blog post, we’ll be using Azure to illustrate certain aspects and to link to official documentation.
One of the first things to consider is in which regions your company operates and where you are going to store and process the data generated in each region. Usually, for legal reasons, it is obligatory to store private information generated in a specific region in a datacentre in the same region. The number of regions will impact the number of Databricks workspaces needed and how you share information between regions; see Azure geographies to find the available regions.
Another key topic regarding data platforms is the number of environments for developing and productionising your pipelines and data products. It is recommended to have more than one environment – two (dev/pro) or three (dev/pre/pro) – to isolate the productive workloads, where end-users interact, from the development carried out by the data teams. Nevertheless, it is common practice to start small with a few use cases in a single environment. Once the team has become familiar with the platform, you can add the rest of the environments. In either case, starting small or with all the environments ready, it is important to define a naming convention to specify which environment each resource belongs to.
A key concept in data management is resource segregation, which involves separating data resources across different environments. Typically, this means replicating the same resources in each environment, albeit with variations in configuration, such as reducing compute power in a development environment compared to production. However, when you have a large team of data professionals and your company is organised into business units (e.g., departments or domains in a Data Mesh), it is often beneficial to mirror this division within your data platform.
Although many factors come into play when designing your data platform, today’s post will concentrate on the fundamentals. Let’s delve into the key aspects to consider when defining a Databricks platform!
Workspaces
One of the core components in Databricks is the workspace, where Databricks assets are organised and users can access the data objects and computational resources. Designing the right workspace layout is essential for efficient resource management, access control, and troubleshooting. It is common practice to have one workspace per environment or business unit as mentioned above.
Besides the number of workspaces, the configuration and connectivity of each individual workspace is crucial for security and legal compliance. Although networking per se is a common data platform component, in Databricks there are a couple of configurations that are worth mentioning:
- Secure cluster connectivity: No open ports and no public IP addresses (no Public IP/NPIP) in the data plane.
- VNet injection: Instead of letting Databricks manage the data plane network, use your existing VNet configuration to have full control over it. When defining CIDR ranges for a Databricks workspace, the “rule of 4” should be applied: choose the maximum number of expected concurrent nodes running, multiply this number by 2 for the public and private subnets required, multiply by 2 again for the flash-over instances (those starting up and being shut down), and add 5 addresses that Azure reserves for each subnet. The resulting number will give you the required private IPs for your Databricks workspace.
Using these configurations is considered best practice as they effectively increase the security of your Databricks network by blocking public access to your data plane as well as providing full control over the network.
Furthermore, to restrict public access to your Databricks control plane, Databricks provides an IP access lists feature that lets you limit access to your account and workspaces based on specific IP addresses. In conjunction with these capabilities, Azure Network Security Groups permit the setting of additional rules to further restrict public access to your resources.
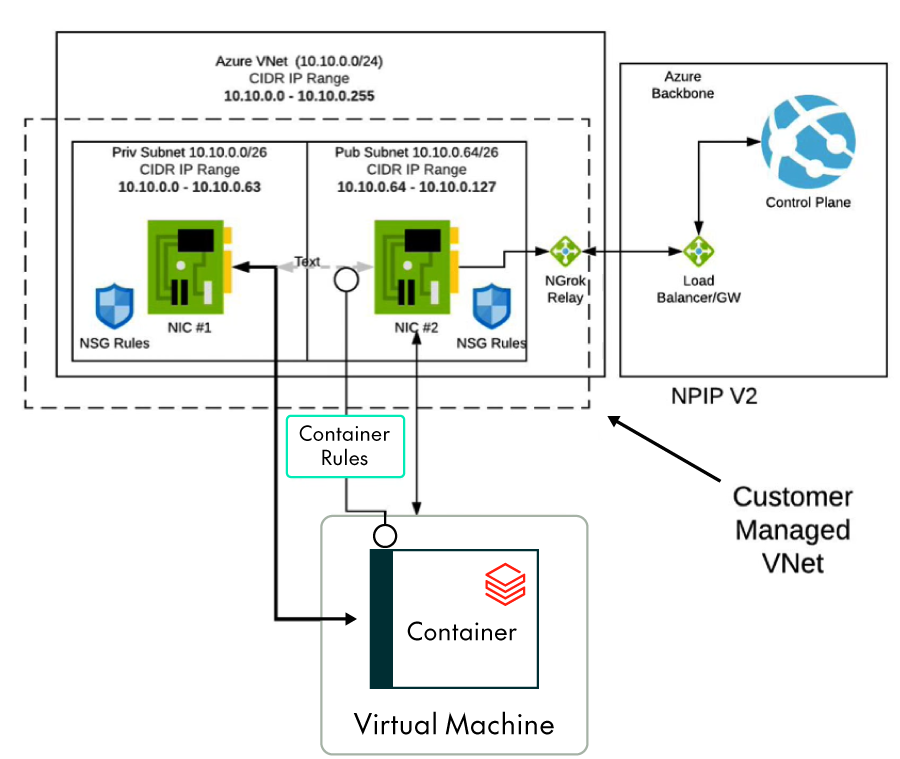
Figure 2: . Databricks NPIP + VNet injection
For companies where these security measures are not enough to meet their standards or legal obligations, it is also possible to fully restrict public access to your Databricks account by enabling private connectivity between users and Databricks. You can configure your Databricks workspace with Azure Private Link to privately connect the Databricks control plane and the data plane, as well as user access to the workspace. This configuration allows you to dispense with IP access lists and NSG rules, as all connectivity occurs within the private virtual network. However, it’s a complex setup so we won’t explore it further, but you can find more information in the official documentation or you can reach out to us directly to discuss your situation in detail.
Data Governance with the Unity Catalog
Data governance in Databricks is handled with the Unity Catalog, a unified governance solution to manage the access controls, auditing and lineage of all data assets across workspaces from a central place. Internal tables are stored in the Unity Catalog metastore, which are essentially Delta Lake tables stored in a cloud store like Azure storage accounts Gen2. There is a limitation of only one metastore per region in Databricks.
Unlike the Hive metastore, which has only two namespaces (schema and table) and lacks access control capabilities, the Unity Catalog metastore introduces an additional namespace (catalogue, schema, and table), providing greater flexibility in access control.
Typically, catalogues are used to segment data between environments and business units, like workspaces, by assigning each workspace to its corresponding catalogue. For example, the development workspace might have access to read and write in the development catalogue but be unable to access the production catalogue.
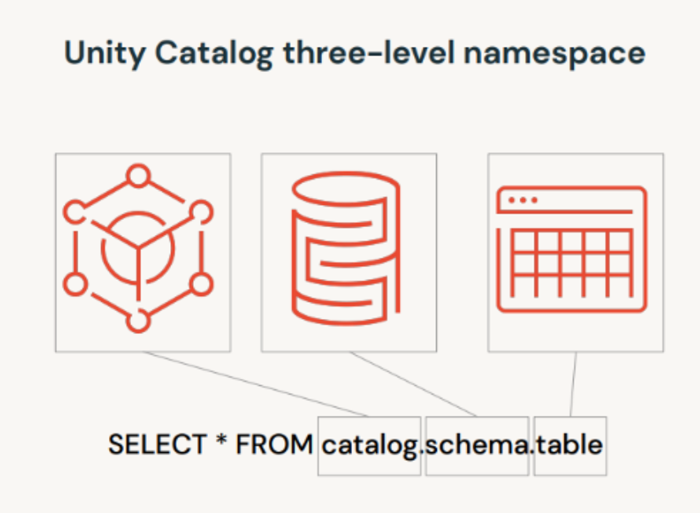
Figure 3: Unity Catalog three-level namespace
Another governance topic is data sharing. Many businesses have to share data with partners and suppliers who do not necessarily use Databricks, or to share data between isolated business units within the same company. To avoid the need to replicate your data, Databricks has released the open-source protocol Delta Sharing, where you can define which tables you want to share (shares) and who can consume them with fine-grained access control (recipients).
Delta Sharing is natively integrated with the Databricks Unity Catalog, enabling you to centrally manage and audit your shares. Delta Sharing is particularly useful for sharing specific tables between regions, as they are stored in different metastores, without duplications.
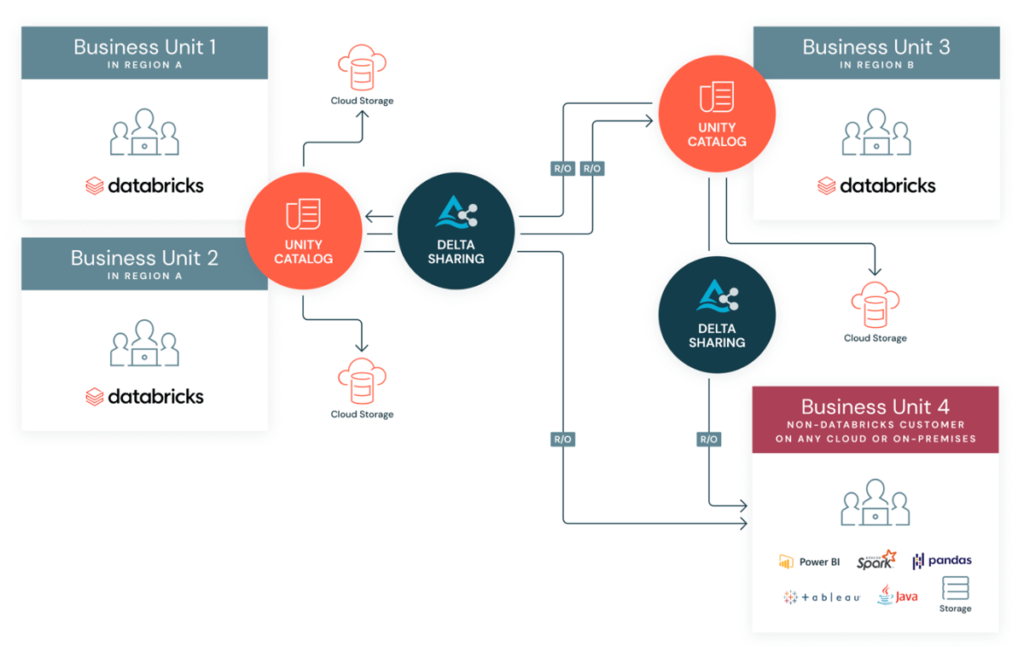
Figure 4: Delta Sharing diagram
Security
Databricks provides a wide range of security mechanisms to secure your data platform, besides the networking layout mentioned above and the fine-grained access from the Unity Catalog. Databricks supports SCIM provisioning using identity providers such as Microsoft Entra ID (formerly Azure Active Directory) for authentication. It is best practice to use SCIM provisioning for users and groups in your Databricks account and to assign them accordingly to the corresponding workspaces with identity federation enabled. By default, users can’t access any workspace unless access is granted by an account administrator or a workspace administrator. In Azure, users and groups assigned as Contributor or above to the Resource Group containing an Azure Databricks workspace will automatically become administrators.
In addition to users and groups, Databricks handles service principals to access external data sources and to run production jobs within Databricks workspaces. Although users can use their credentials to run workloads, it is always recommended to use service principals since users might leave the company or move to another department, making their credentials obsolete, inappropriate, or insecure.
Compute (Clusters and Optimisations)
Databricks is renowned for its compute component, not only due to its Spark-based architecture, arguably the best on the market, but also because of the various compute types tailored to different use cases. Databricks offers the following compute types:
- All-purpose/interactive clusters: Provisioned clusters to explore and analyse your data in notebooks. Although it is possible to attach an interactive cluster to a Databricks workload, this is not recommended for productionised workloads.
- Job compute clusters: Clusters created specifically to run automated jobs. This is the best option to run automated production workloads, as the clusters are created to execute the job in an isolated environment and and are discarded once the job is completed, thereby saving costs as clusters can’t be left running in the background.
- Instance pools: Ready-to-use compute instances, ideal for workloads that need to reduce their start and autoscaling times, ensuring quicker and more efficient performance.
- SQL warehouses: Provisioned clusters to explore and query data on Databricks. Serverless capability can be enabled to avoid start-up times. They are also used for querying the data beneath Databricks Lakeview dashboards.
Choosing the correct cluster types is key to optimising your data platform costs, and on top of this you can also enhance your resource utilisation and cut costs by right-sizing clusters, leveraging autoscaling, and employing spot instances for non-critical workloads.
What’s more, Databricks allows the setup of cluster policies to restrict cluster creation or to impose standard configuration options on created clusters, helping to prevent excessive usage, control costs, and simplify the user experience.
ML and AI
Although Databricks stands out for its ML and AI capabilities, we won’t be discussing them today as they do not require specific infrastructure configuration when architecting your Lakehouse platform. Nonetheless, you can read our blog post about MLOps in Databricks, where we explain why you should consider Databricks for your use cases and how to build an MLOps pipeline to create, test, and promote your models.
Conclusions
Databricks is one of the bests alternatives available to develop your Lakehouse data platform, unifying all your data, analytics, and ML workloads. Governance across all Databricks assets is ensured by the Unity Catalog, whilst a correct workspace setup secures connectivity to the platform. By leveraging Databricks, businesses can achieve greater efficiency, scalability, and innovation in their data strategies.
This blog post has only covered some of the aspects that must be considered when designing a Databricks Lakehouse data platform. Each organisation has its own intricacies and requirements, so contact us for expert guidance and support in building out your own platform!
