18 Dec 2024 Kafka Consumer with Protobuf
Apache Kafka is an open-source distributed event-streaming platform designed to handle real-time data feeds. Developed by LinkedIn and later open-sourced, it is now part of the Apache Software Foundation. Kafka is used to build real-time data pipelines and streaming applications that can collect, process, store, and analyse large amounts of data in real time.
Kafka is based on the concept of a distributed commit log, allowing it to publish and subscribe to streams of records, store them reliably in a fault-tolerant way, and process them in real time. With its high throughput, scalability, durability, and fault tolerance, Kafka has become a cornerstone of modern Big Data architectures.
In this blog post, we’ll outline the steps to consume Kafka topic messages that have been compressed and serialised using Protobuf (Protocol Buffers), based on our experience with topics generated by Netcracker’s Telecom Operations and Management Solution software.
Use Case
We’ll start with Kafka messages that have been compressed using the LZ4 algorithm and serialised with Protobuf, produced by an external Kafka producer.
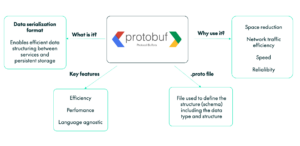
Protobuf is an efficient, language-neutral data serialisation mechanism developed by Google. It is widely used for transmitting data between systems or storing it in a compact format.
Protobuf uses a binary format, which is significantly more space-efficient than text-based formats like JSON or XML. Moreover, it is language-agnostic, offering compatibility with multiple programming languages, including Java, C++, Python, Go, and more.
Our objective is to code a Kafka consumer in Python to deserialise, in real time, a topic message that was previously produced, compressed, and serialised using Protobuf. The deserialised message content will then be converted into JSON for ease of use.
Just follow these steps:

Compile Protobuf Schema
The structure of Protobuf-serialised data is defined in “.proto“ files, which contain the schema for the data messages we want to deserialise, including their data types and structure. These “.proto“ files are generated on the producer side (in our case, they were provided by Netcracker).
Before deserialisation, these files must be compiled using the Google command-line tool “protoc”. This tool can be downloaded from the official Protobuf GitHub repository (file “protoc-xx.x-win64.zip” for Windows).
When compiling, a parameter must be specified to indicate the target programming language for the output: in our example we’ll use Python.
The compilation process will generate a Python file (“.py”) for every “.proto“ file. These Python files will later be imported into the Python consumer script to deserialise the messages.

Message Consumption
This process will always be listening for produced, compressed and serialised Kafka messages.
The Kafka consumer can be implemented with any data integration tool or a custom script. To do so, it’s important to ensure that the “LZ4” library is installed in your consumer environment.
In our example, we’ll use a custom Python script. Besides “LZ4”, the other libraries that must be installed in the Python environment before proceeding are “kafka-python”, “google” and “protobuf”.
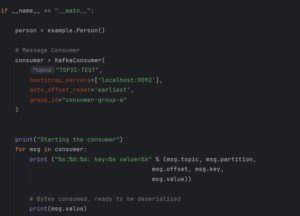
In our script, the first step is to import the necessary modules, including “KafkaConsumer” to consume the messages, the previously generated “example_pb2.py” file (produced during “.proto“ compilation), and “MessageToJson” to convert the deserialised object into JSON:

Now it’s time to initialise the consumer by defining the necessary parameters. Some typical Kafka consumer configuration parameters include:
- Topics: the name of the topic to listen to.
- Boostrap servers: the Kafka server hostname.
- Consumer group: the consumer group name.
- Auto offset reset: “earliest” will move to the oldest available message, while “latest” (the default) will move to the most recent.
- Offset management: specifies when to commit offsets, either after each record is read or after a batch is completed.
As a result of this consumer code, we will have the value of every Kafka message, still serialised in Protobuf format. Here’s an example:
![]()
Message Deserialisation
Once the Kafka message is consumed inside the loop, the key point is to deserialise it with Protobuf into a “Person” object:

Then the deserialised object can be converted into JSON, making it ready for further processing, persistence in a database table, or transformation into another structured object!

This process produces the following output for the example:

Conclusions
In this post, we have demonstrated how to build a Kafka consumer in Python to handle messages compressed using the LZ4 algorithm and serialised with Protobuf. By deserialising these messages and converting them into JSON format, we make the data easily accessible for further use, whether it involves storing it in a database, analysing it, or integrating it into other systems.
This approach highlights the power and flexibility of Kafka and Protobuf in handling real-time data pipelines, especially when dealing with high-throughput, complex data structures. Using Python allows developers to create tailored solutions that fit specific business requirements, ensuring efficient data processing.
Are you looking to implement similar real-time data solutions in your organisation? At ClearPeaks, we specialise in designing and deploying data architectures tailored to your unique needs. Whether it’s working with Kafka, Protobuf, or other modern tools, our team of experts can help you unlock the full potential of your data. Contact us today!
