06 Nov 2024 The Semantic Router: AI’s Pathway To Understanding User Input
Here at the ClearPeaks Observation Deck team we are continually innovating and enhancing our chatbot to provide our customers with the best possible experience. One of the key challenges we face is to accurately understand and interpret user requests to ensure that our responses are both relevant and helpful.
To tackle this, we are excited to introduce a new feature: the semantic router. This advanced software module enables our chatbot to identify exactly what you, the user, are trying to achieve. By leveraging modern similarity search algorithms, the semantic router analyses your queries, comprehends their context and intent, and directs your request to the appropriate function, thus guaranteeing the most accurate and efficient service possible, making your interactions with the chatbot smoother and more intuitive.
In addition to enhancing accuracy and relevance, the primary goal of the semantic router is to replace the need for a prompt or an AI agent to manually select which downstream task to perform. Initially, we approached this problem using prompts, but there were issues with latency and rising costs.
The semantic router effectively overcomes these problems by automating the task selection process, delivering faster responses at lower operational costs. This enhancement not only optimises performance but also streamlines the experience, making interactions more efficient as well as more cost-effective.
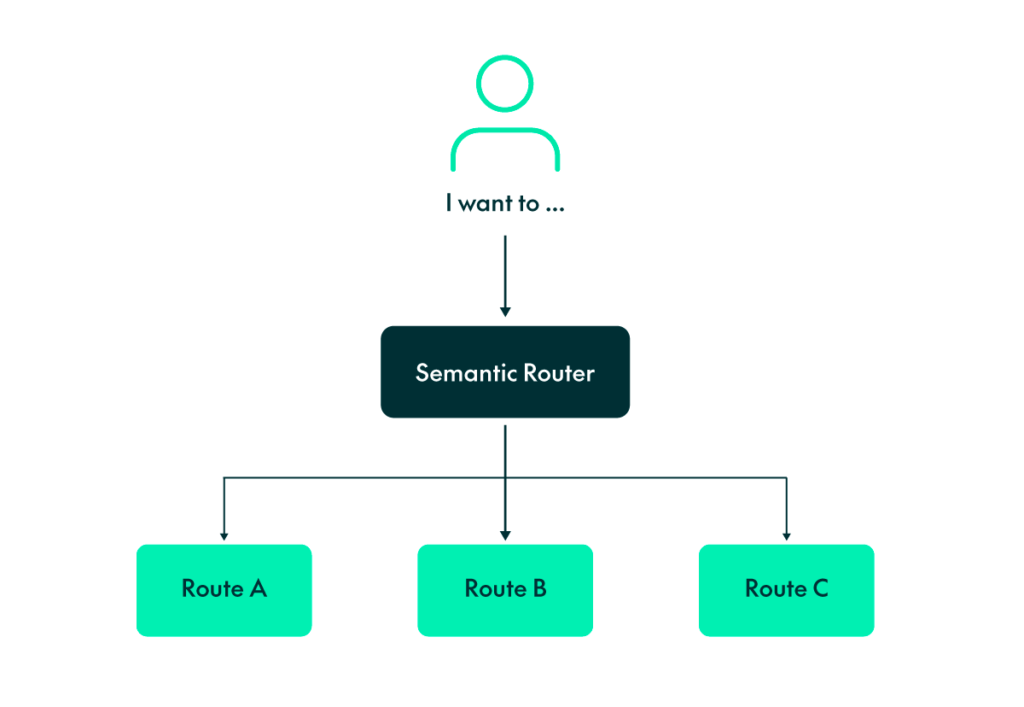
Figure 1: The Power of AI Embeddings
Classifying user input accurately within its specific context is far from simple. Traditional routing methods typically rely on conditional branching to choose a predefined path, which can be limiting in scope.
While this approach works well when the route is known in advance and can be explicitly programmed, the dynamic and complex landscape of today’s AI demands more sophisticated techniques to process vast and varied real-world data.
Modern AI systems utilise sophisticated methods to transform this data into mathematical expressions, which can be analysed to identify key patterns and features. These mathematical representations, known as embeddings, convert textual and other data types into dense, multidimensional vectors. This allows for a richer and more nuanced understanding of the data, enhancing further processing and analysis. Through embeddings, AI systems gain the ability to interpret and classify inputs more accurately, paving the way for the development of more responsive and intelligent applications.
As we mentioned previously, our semantic router relies heavily on generating embeddings for the text that needs to be classified. To generate these embeddings, we use specialised models designed to process large volumes of text data. These models learn and encode the semantic relationships between words and phrases into numerical vectors, allowing the semantic router to categorise and route text effectively based on its underlying meaning.
Embedding models are trained through a sophisticated process involving several key steps. Initially, a large corpus of text is tokenised into manageable units, like words or monemes. The next step is learning from the context in which these tokens appear. Two common methods are the Continuous Bag of Words (CBOW) and the Skip-Gram models. CBOW predicts a target word based on surrounding context words, whereas Skip-Gram works in reverse, predicting the context words from a target word.
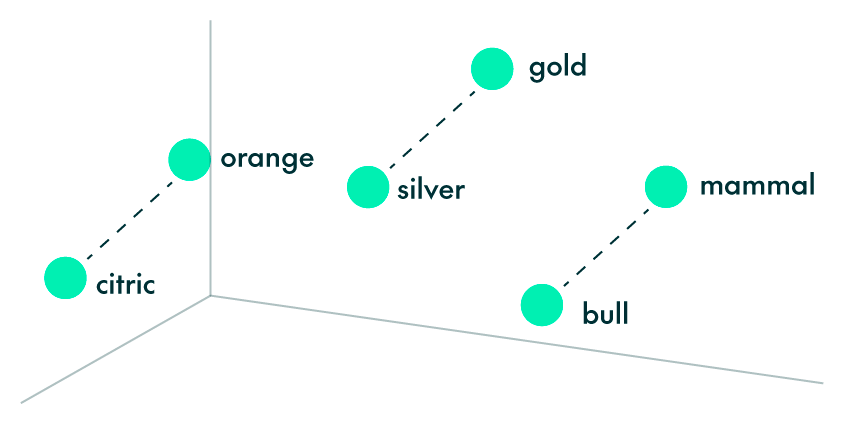
Initially, each word is assigned a random vector, which the model refines iteratively by optimising a loss function that measures prediction accuracy. Negative sampling is often employed during this process, helping the model distinguish between actual context words and randomly selected ones. As the model trains, it captures semantic relationships by mapping words into a high-dimensional space, where words with similar meanings are represented by vectors that are close to each other. For example: vec(“Spain”) + vec(“capital”) is close to vec(“Madrid”), just as vec(“blue”) + vec(“planet”) is close to vec(“Earth”). Below we can see another example, where similar concepts, like “silver” and “gold”, or “bull” and “mammal,” are positioned close to each other:
Some of the most prominent embedding models include Word2Vec and BERT (Bidirectional Encoder Representations from Transformers), both developed by Google, and GloVe (Global Vectors for Word Representation) from Stanford. Each of these models has a unique approach to capturing and representing semantic information.
Fortunately, we don’t have to handle the complexities of training and maintaining these embedding models ourselves. Instead, we can harness services like Microsoft Azure OpenAI, which provide access to state-of-the-art pre-trained models. By using Azure OpenAI, we can query these advanced embeddings models directly with the text we want to convert.
This approach not only saves us the computational overhead and resources required for training large models, but also ensures that we benefit from the latest advancements in AI technology. These pre-trained models allow us to focus on applying the embeddings to enhance our semantic router’s capabilities, making it easier to classify and process text with greater accuracy and efficiency.
The Router Index
Now that we have the embeddings for our target text, the next step is to compare these embeddings against a reference set, known as an index, which represents the potential categories or topics for classification.
An index is essentially a collection of pre-computed embeddings that correspond to a predefined set of topics or categories. To build this index, we first generate embeddings for a comprehensive set of texts that cover the full range of topics for classification. These embeddings are then organised into a structured format, typically a large matrix. Each row of this matrix represents the embedding vector of one reference text, making the matrix’s dimensions equal to the number of reference vectors by the dimension of each vector. Since all embeddings are generated by the same model, they share the same vector dimensions, ensuring consistency in the comparison process.
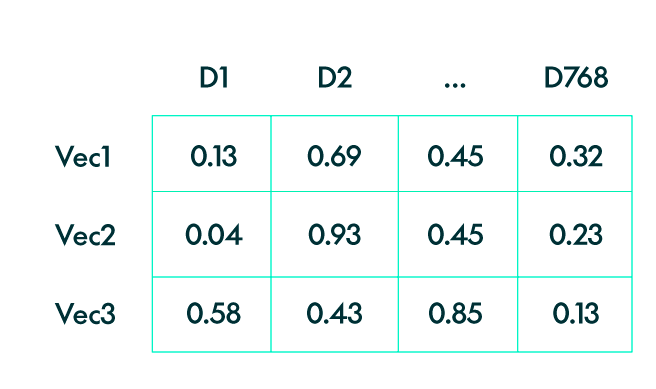
The process of creating this index involves aggregating embeddings from various texts into the matrix, allowing us to efficiently compare new embeddings against it. However, to ensure accurate and meaningful matching, any new embedding vector used for comparison must be generated using the same embedding model or a compatible one. This consistency is crucial as embeddings from different models or versions may not align properly in the vector space, leading to unreliable results.
Once the index has been built, we can proceed with the matching process: comparing the embedding of the user’s input text with the embeddings stored in the index. By identifying the nearest embeddings in the index to the user input embedding, we can determine the most relevant category or topic for the input text.
Similarity Search: Unlocking the Power of Data Matching
Now that both our index and the user input embeddings are ready, the next step is to build a similarity matrix – a mathematical tool used to quantify how similar different vectors are to one another. In our case, the vectors represent embeddings, which are numerical representations of texts. The similarity matrix will measure how closely the user input embedding matches each of the embeddings in our index.
One of the most common methods used to calculate this is cosine similarity, which measures the cosine of the angle between two vectors in a multi-dimensional space. The formula for cosine similarity between two vectors, A and B, is the dot product of A and B, divided by the product of their magnitudes. This results in a value between -1 and 1, where 1 indicates the vectors are identical in direction, 0 means they are orthogonal (unrelated), and -1 means they are diametrically opposed.
To build the similarity matrix, we perform the following steps:
- Compute the norms (magnitudes) of the user input embedding and each embedding in the index.
- Calculate the dot product between the user input embedding and each embedding in the index.
- Divide each dot product by the product of the corresponding norms to get the cosine similarity scores.
Since we are comparing the user input embedding with each embedding in the index, our similarity matrix is actually a vector. This vector contains similarity scores, each representing how similar the user input is to a particular topic in the index.
With our similarity matrix in place, we can sort these scores in descending order, identifying the topics with the highest similarity to the user input. The higher the score, the more relevant the topic is to the user input.
And that’s it! With this fully functional semantic router, user inputs are now effectively routed to specific task-handling mechanisms, enabling the chatbot to better understand and respond to user requests and also to provide relevant and precise responses, improving its ability to assist users effectively.

To further illustrate how the semantic router works, look at the picture above. We manually create specific utterances for each of the routes it manages. These utterances represent the different types of user requests we anticipate, and they are stored together in the index. This allows the semantic router to quickly compare incoming queries with pre-defined utterances, ensuring that it can accurately match user intent with the correct function. By efficiently organising these utterances in the index, we significantly improve both the speed and precision of the chatbot’s responses.
Enhancing Routing with Similarity Techniques
Now that we have a fully functional semantic router guiding actions based on user input, there are several key factors to bear in mind to ensure excellent service delivery.
Firstly, user input isn’t always clear or precise. People often express their intentions using vague, incomplete, or colloquial language, which can make it difficult for the semantic router to accurately interpret their intent. For instance, abbreviations or slang may confuse the system, leading to inaccurate routing. To address this, it is essential to incorporate a robust fallback mechanism, capable of handling cases where the user’s intention is unclear and either guiding them to clarify their input or defaulting to a general action that can accommodate the ambiguity.
Secondly, semantic routing relies heavily on interpreting the meanings of words and phrases to determine the appropriate action, but different actions may share similar semantics, especially in specialised or focused applications. For example, in a customer service setting, the distinction between a request for a “refund” and a “return” can be subtle and context-specific. This semantic similarity can pose a challenge for the router, as it may not always be able to distinguish between such closely related actions. So, while designing the semantic router, it is crucial to implement mechanisms that can handle such nuances, possibly by incorporating additional contextual information or by designing the system to prompt users for further clarification when similar semantic routes are detected.
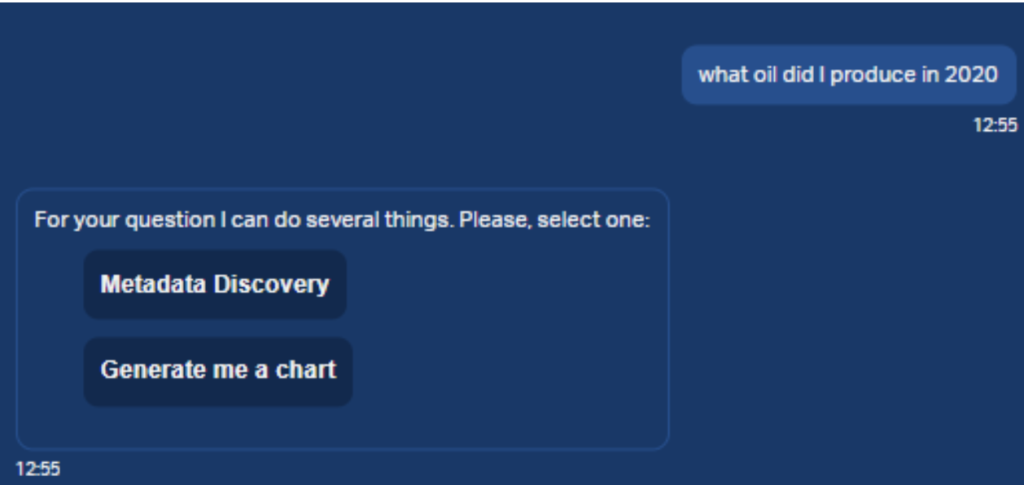
As shown in the image above, for ambiguous questions (where the user may be asking “What type of oil did I produce in 2020?” or “What was the total volume of oil produced in 2020?”), the chatbot offers a choice, prompting the user to clarify which action (or route) to take.
This happens because the scores for the two routes, obtained after the similarity search, were too close. As a result, the semantic router is unable to determine what the user wants to do. To calculate the scores in the Observation Deck chatbot, we perform the following steps:
- We use a similarity search function to find the closest matches between the user’s input and the pre-defined utterances in the index.
- For each potential route, we sum the similarity scores for the relevant matches and count how many matches align with that route.
- We then normalise the score by factoring in both the total similarity score and the number of matches for each route.
- Finally, we sort the routes in descending order based on their normalised scores, enabling the semantic router to identify the most relevant action.
This process ensures that our chatbot identifies the most appropriate response based on semantic similarity, balancing both the quality and quantity of matching utterances.
In conclusion, while a semantic router is a powerful tool for guiding actions based on user input, there are certain considerations that must be addressed to ensure its optimal effectiveness: implementing robust fallback mechanisms, handling the challenges of semantic similarity, refining the semantic models continually, and training users in effective interaction.
The semantic router offers significant advantages in terms of speed and cost-effectiveness, but it does have limitations when it comes to scalability, particularly if vector stores are dynamic and require the generation of new utterances each time the store is created. By addressing these issues, we can enhance the reliability and accuracy of the semantic router, providing a faster, more efficient, and user-friendly service.
If you’re looking to implement or optimise a semantic routing solution for your business, ClearPeaks can help. Our team of experts specialises in delivering advanced AI-driven systems tailored to your organisation’s needs, so get in touch with us today to explore how we can help you.
