02 Nov 2023 A New Approach to Ingesting Data Using AWS Serverless Services
In this blog post, we are going to present a new approach to ingesting data using AWS serverless services. This setup could be useful in scenarios that require specific libraries, or when applications need to be run on specific OSes that are not available on mainstream processing services, like Glue ETL or EMR. It’s also pretty handy for those used to developing in containers.
AWS provides two services that rely on containers and that fit nicely into a Big Data architecture deployed on AWS: AWS ECS (Elastic Container Service) and AWS Lambda.
AWS ECS
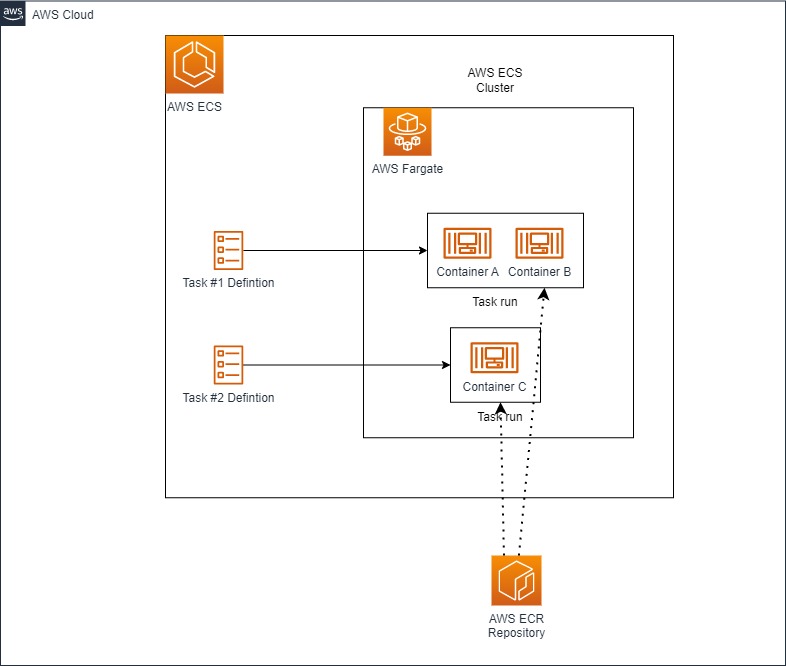
The proposed architecture relies on AWS ECS, a fully managed container orchestration service. In addition to deploying long-running applications as services, mostly used on microservices architectures, it also runs batch jobs as tasks.
The following steps describe how to set up the solution:
- Define the ECS cluster where you can specify if you prefer to execute the containers on AWS Fargate, our recommended approach, or to use EC2 instances. We should also consider which engine hosts the container: there are two main options available, EC2 or Fargate; and we suggest using the latter as it eliminates the need to manage any underlying infrastructure. To reduce the cost, EC2 Spot Instances are also available but you need to consider the implications of using them.
- Specify the network setup: the cluster´s VPC and subnets.
- Prepare the ECS task definition where you specify the containers that are going to make up your task; a task can be made of several containers. In addition to specifying the container details and the URL from which the image will be pulled, the following settings also have to be configured:
- The task infrastructure requirements: operating system architecture, the amount of CPU and memory reserved for the task and for each container.
- A task IAM role should be assigned to the containers, granting them sufficient permissions to interact with other AWS services. Here, you define permissions such as accessing S3 to store results, retrieving keys from Secret Manager, and so on.
- A task execution IAM role, used by the container agent; AWS can create a default one. This role has permissions to access the AWS ECR registry and AWS CloudWatch.
Once both the ECS cluster and the tasks have been defined, you can run the tasks from the cluster page.
The following diagram depicts the main elements of the AWS ECS service:
AWS Lambda with Container Image Support
Here we’ll look at another way to run a docker container, relying on AWS Lambda. Not long ago, AWS released a new feature to support the execution of container images as Lambda functions.
Running AWS Lambda functions packaged as docker containers, isn’t so different from the usual ZIP archived package mode, offering the same operational scalability and integration.
Let’s list the similarities between deploying containers using AWS Lambda and the AWS ECS service:
- Both services can deploy images uploaded into the AWS ECR registry.
- AWS Lambda also supports the ARM64 and x86_64 architectures.
- An IAM role has to be assigned to AWS Lambda, which corresponds to the task IAM role defined on the ECS service.
Now let´s check out the differences between AWS Lambda and AWS ECS:
- AWS ECS allows the definition of tasks that are made up of several containers.
- AWS ECS supports Windows x86_64 architecture.
- AWS Lambda still has a 15-minute execution limit.
- The maximum amount of memory you can allocate to an AWS Lambda function is 10GB, but on AWS ECS it’s 120GB.
After seeing these differences between the services, it should be easy enough to decide which one fits your application deployment the best. If you’re still hesitant, we suggest you start with AWS Lambda, as it the most adequate service for single container applications and it also requires fewer processing resources.
Integrating the Ingestion Process in the Big Data Architecture
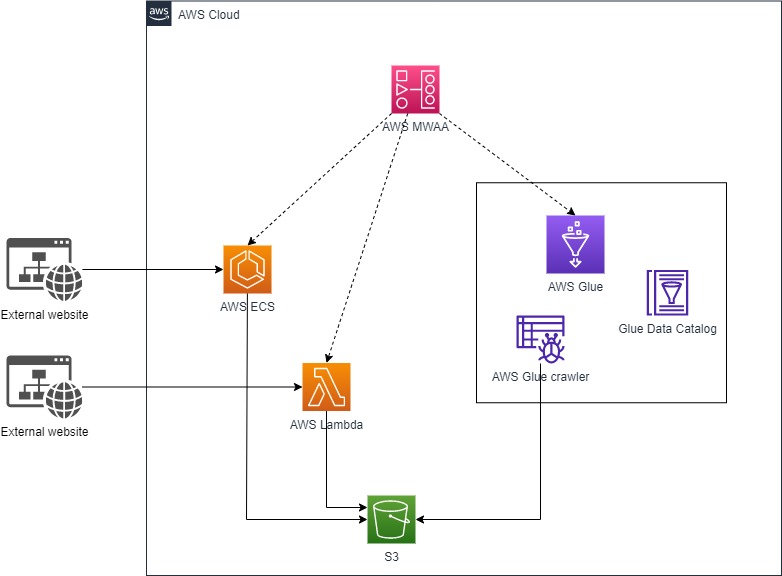
Let’s now see how the proposed ingestion layer, using containers, fits into a Big Data architecture deployed on AWS. The ingestion layer has two main integrations with the rest of the platform, the orchestration and the data lake layers.
For the orchestration layer, we propose a Big Data platform orchestrated by Airflow, provided by the AWS MWAA service. Airflow workflows can easily interact with both ECS tasks and Lambda functions thanks to the ECS operator and the Lambda operator.
As for the data lake layer integration, we propose the docker containers store the extracted data in raw format in S3. In the next stage a Glue crawler can read the raw data and catalogue it in the Glue Data Catalog.
Once the data is ready to be queried via the Data Catalog it can be consumed in several ways: via the transformation layer, to calculate business KPIs, via a data exploration tool such as Athena, or via direct visualisation with AWS QuickSight.
The following diagram summarises how the ingestion process integrates with the rest of the AWS services:
Conclusions
As container technology is becoming more popular on data platforms, and as more data engineers are comfortable working with it, we have presented two AWS services that can deploy your applications packaged as docker containers.
We hope this blog post will help you to identify and to understand these new services to expand your data platform so that it can ingest almost any type of data.
Here at ClearPeaks, our consultants have a wide experience with AWS and cloud technologies, so don’t hesitate to contact us if you’d like to know more about what we can do for you and your business.
