
19 Jan 2022 Implementing an AutoML Pipeline for OEE Forecasting
Every day there are more and more technologies facilitating access to Machine Learning (ML), and we can see it being applied to many different fields. Now, non-expert profiles without a Data Science background have a whole range of tools at their disposal to help implement and use ML pipelines.
In today’s blog post we are going to talk about one of these methodologies helping the democratisation of ML: Automated Machine Learning (AutoML), a set of techniques that automate the process of solving problems with ML: from pre-processing, feature engineering and hyperparameter optimization, to the selection of the best-performing model.
In recent years a lot of different packages have been developed to provide AutoML, such as Auto-PyTorch, which optimises the hyperparameters and neural architecture; AutoWEKA, which selects the best ML algorithm and its hyperparameters, or Auto-sklearn, an extension of AutoWEKA using sklearn.
In the next sections we will go through how we implemented an AutoML pipeline for the specific case of predicting the Overall Equipment Effectiveness (OEE) of manufacturing processes. For more information on this topic, visit our recent blog post about ML in manufacturing.
Implementation
A typical ML pipeline usually follows this structure:

Figure 1: Typical ML pipeline.
Once you have a clear understanding of the problem that you need to solve and the target that you want to predict, you need to collect the necessary data. After exploring your data, you may need to clean it and prepare it for modelling; this may include null value or outlier treatment, for example.
Once you have a clear knowledge of the data available, you can use your business understanding to create new features that could benefit the predictive models. After that, you can run some analyses to try to figure out the importance of your features.
Finally, when the data is ready for modelling, you may want to optimise the model hyperparameters in order to obtain the best configuration possible. Once this process is complete, you can evaluate the results obtained from modelling and decide whether the current solution is good enough for deployment or if you need to go through another iteration.
This whole process of trying different features, hyperparameters and even baseline models can be a repetitive and time-consuming task; moreover, it requires the knowledge of a data scientist, to make decisions on how the models should be trained.
To obtain automated training and prediction without constant expert supervision for our specific use case, we put together a pipeline that automatically performs feature selection and hyperparameter optimisation for a series of baseline models, and then chooses the model with the lowest error to put into production.
The pipeline that we followed can be summarised in Figure 2:
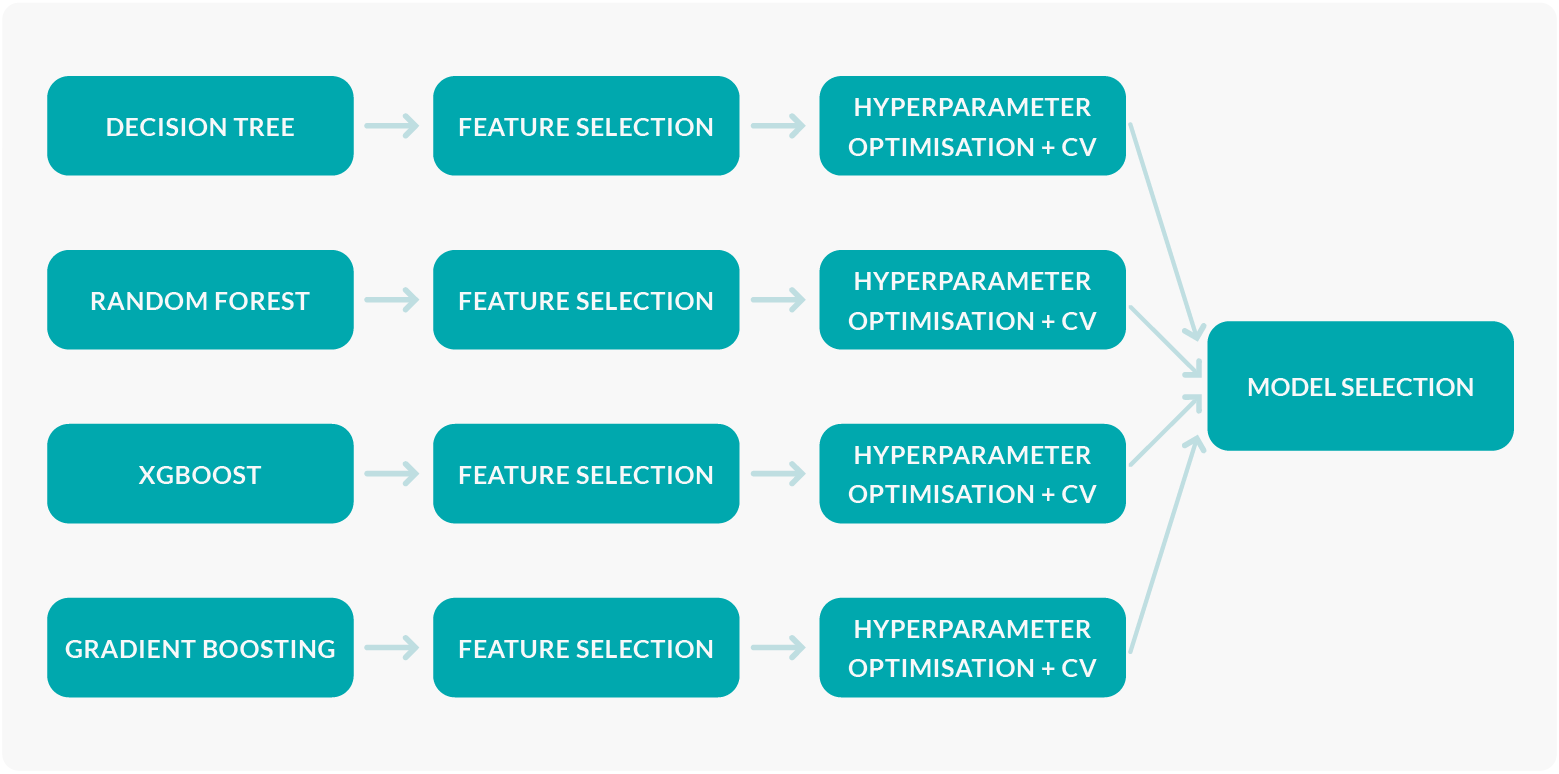
Figure 2: Automated model training and selection.
At the beginning of the modelling stage of this project, different models were tested to see their overall performance in predicting the target metrics for our specific use case. After a few iterations, the best performing models were selected: Decision Trees, Random Forest, XGBoost, and Gradient Boosting. These models will be used as the baselines and will be compared with one another in order to obtain the best performing one for production.
The pipeline then uses Forward Feature Selection to obtain the most relevant variables for each of the four baseline models. This technique iteratively adds the best new feature to the set of selected features by selecting the one which maximises a cross-validated score when the model is trained on that single feature; the process is repeated until the maximum number of features to be selected is reached.
Afterwards, once each model has its own set of input variables, a grid search is performed for each of them to obtain the best configuration of hyperparameters. This is an exhaustive search that tries all the combinations from a grid of manually defined hyperparameters, finally selecting the configuration that minimises the mean squared error (MSE) of the model obtained after a process of cross validation (CV).
The last step, after all the baseline models have been trained and optimised, is to choose the one with the lowest error. This model will then be trained with the whole training dataset and then used to obtain the predictions from the test dataset.
To keep track of this process and to allow for reproducibility of the results obtained from the models, every time a model is trained a JSON file is generated which stores the final results obtained by each of the four baseline models after optimisation: the train and validation errors, the hyperparameters and variables chosen for each of them, and the predictions made in the validation sets.
What More can be Done?
Using this pipeline, we were able to automate some of the tasks performed in a typical ML pipeline: feature selection, hyperparameter optimisation, and model selection. Nonetheless, so many more tasks could be automated in an AutoML approach:
- Retraining the models when error is high
Once the models are deployed and ready to be used to make predictions in a production environment, we
should think about when to retrain them – and this task can once again be left to AutoML.An important feature of the ML lifecycle is model drift: the relationship between the variables and the
target could change with time, because the statistical properties of either the target variable or of the
predictors change. To avoid the models becoming useless due to this drift, retraining can be automated once
the prediction errors pass a certain threshold.
- Pipeline selection under time or memory constraints
Especially when working with complex Deep Learning models, smart use of the available resources is key. In
cases like this, being able to automate the process of selecting the model that will give the best results
given time or memory constraints can save you a lot of time.
Benefits of AutoML
In this blog article we have showed you how we implemented an AutoML-like pipeline for one of our use cases.
Automating processes such as feature selection or hyperparameter optimisation can bring many benefits:
- It can be more efficient, since it simplifies the process.
- It makes it easier to collaborate: since most of these pipelines feed off configuration files, code
tends to be much cleaner and easier to interpret, thus avoiding hard-coded pieces which only the developer
may understand. - It is cost-efficient: companies do not need to have a data scientist solely allocated to time-
consuming tasks like hyperparameter optimisation.
Conclusion
Having said all this, one may wonder if AutoML will replace data scientists, and the answer is probably not. Even though AutoML offers a host of benefits, there are some limitations for which a data scientist will be needed. For example, the tasks of interpreting the model or feature engineering based on domain knowledge may be better left to an expert. In conclusion, we could say that the purpose of AutoML is not to replace data scientists, but to free them from repetitive, lengthy tasks so that they can focus on more challenging issues.
If you are interested in learning more about our specific use case or how we implemented our custom AutoML pipeline, do not hesitate to contact us!
