22 Apr 2021 First step towards DataOps – CI/CD on Azure Data Factory
DataOps has become a popular topic in recent years, inheriting best practices from DevOps methodologies and trying to apply them to the data world. Our vision on this topic is aligned with the DataOps Manifesto and the #TrueDataOps Community.
As a Microsoft Gold Partner for Analytics and Cloud Platform, ClearPeaks has a lot of experience with designing and building data platforms for our customers. In this article, we will introduce how to apply Continuous Integration and Continuous Deployment (CI/CD) practices to the development life cycle of data pipelines on a real data platform. In this case, the data platform is built on Microsoft Azure cloud.
1. Reference Big Data Platform
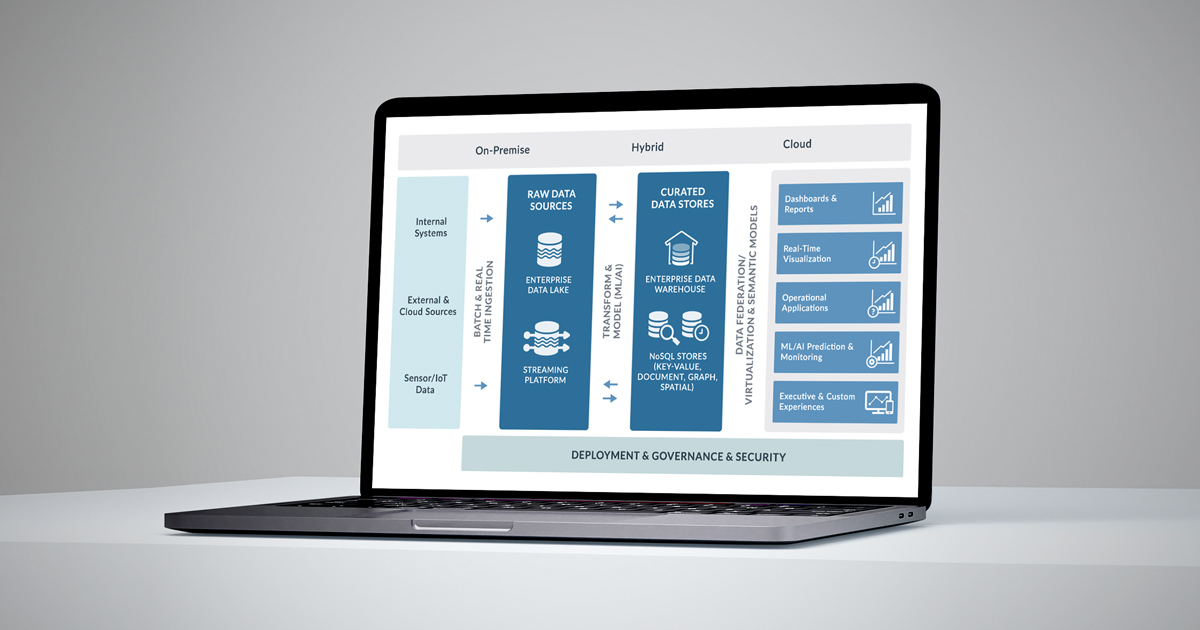
The following diagram depicts ClearPeaks’ reference Big Data Platform. As this article references an Azure data platform, these components are implemented by Azure services.
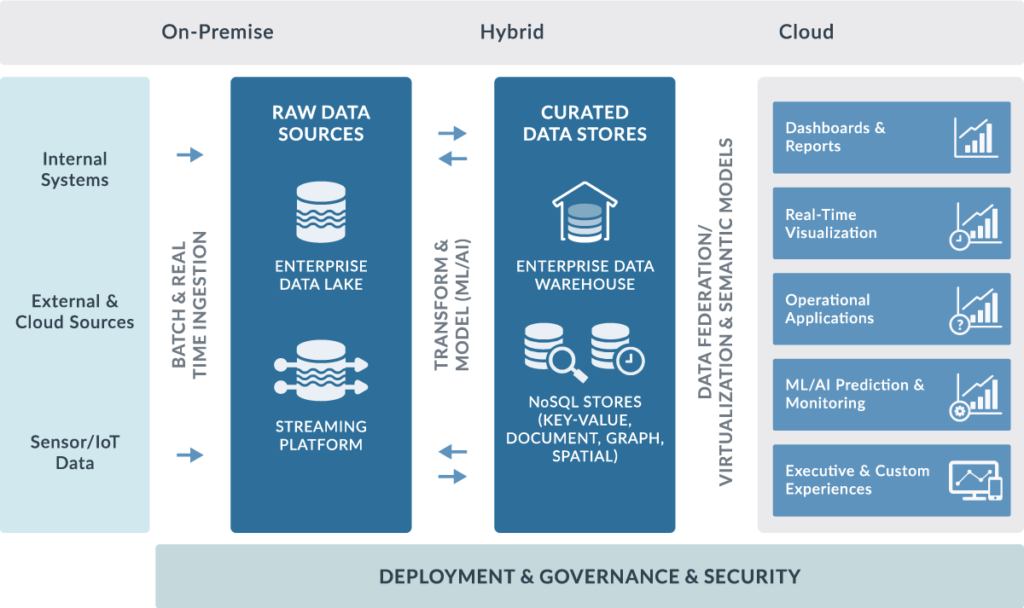
Figure 1: Big Data Platform
In this article, we are going to focus on the Azure Data Factory (ADF). ADF service is the main component of this platform, as it can implement several of the layers described above. ADF can implement the Batch Ingestion layer and the Governance layer. In addition, it can also implement the Transformation layer thanks to the recently released “ADF Data Flows” capability.

Figure 2: Azure Data Factory service description
If you would like to read more about Azure Data Factory capabilities, you can take a look at the following ClearPeaks articles:
- Mapping Data Flows in Azure Data Factory
- Is Azure Data Factory ready to take over SQL SSIS
- SSIS in Azure Lift and Shift
2. Environment – Overview
For the comprehension of this article, it is assumed that three environments of the data platform are available: development, test, and production environment. The deployment of these environments is not part of the CI/CD process explained in this article. Therefore, it can be considered that these environments are either manually created, or built following a CI/CD process using an Infrastructure as Code (IaC) approach.
It is assumed that each environment has an independent instance of each system of the data platform. For instance, in the scenario introduced earlier in this article, three independent instances of the ADF service are deployed.
As depicted in the following diagram, a specific team is assigned to work on each environment:

Figure 3: The three data platform environments
3. Code Control and Continuous Integration on Azure Data Factory
If your company has been preparing data pipelines in ADF for a while, you probably have noticed that as the complexity grows it is not easy to have control on changes. Data Factory has not been designed for collaboration and version control. Therefore, to improve its capabilities and provide a better development experience, it is recommended to integrate ADF with a version control system such as Azure Repos or GitHub. In our example, it has been integrated with GitHub Enterprise.

Figure 4: ADF integrated with GitHub
In the above image, we can see how ADF looks after it has been integrated with a code version tool. As it depicted in the following diagram, only the development environment has to be connected to the version control system.
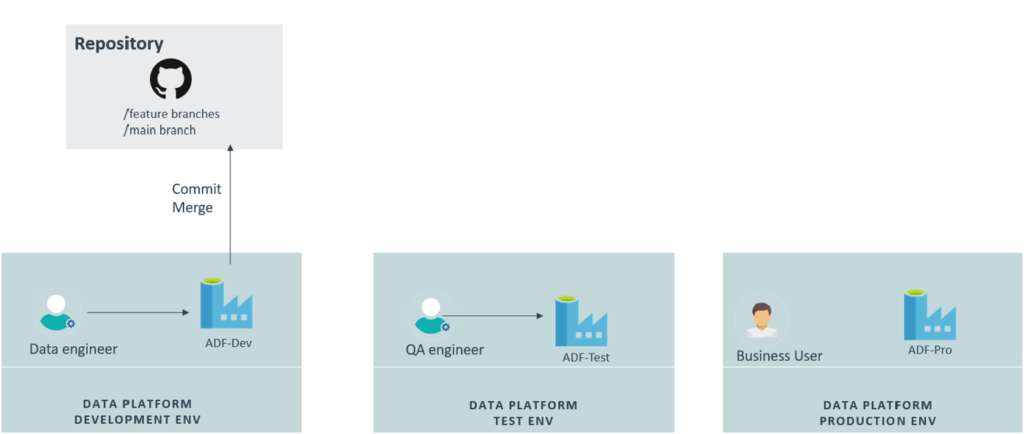
Figure 5: ADF integrated with GitHub
Once ADF has been integrated with a version control system, the actions available on the user interface change as follows:
- New Branch: Creates a new branch on the repo.
- Save: Triggers a commit on the working branch.
- Create Pull Request: Triggers a pull request between the working branch and the collaboration branch. Once a feature has been developed and unitary test executed, the Pull-Request option can be triggered. This option opens a window on GitHub from which the pull request can be accepted. It can also be triggered from GitHub. By default, the branch will be merged to main.
- Publish: Once a branch has been merged to the collaboration branch, the “Publish” option on Data Factory can be executed. This option triggers the build which generates a new branch, called “adf_publish”, where the Azure Resource Manager (ARM) code is generated by the Data Factory. This branch, considered the artifact, can be later used by the CD process. After the Publish, the automatic deployment of code to the rest of environments should start.
In this section, we have seen how to control changes on ADF, i.e., the CI phase. In the next section, we will introduce how the code is deployed to the rest of the environments, i.e., the CD phase.
4. Continuous deployment on Azure Data Factory
In this scenario, since the data platform is built on Azure, the Azure DevOps suite is our preferred tool to manage the continuous deployment of the code to test and production environments. The Azure DevOps suite is made of several services. For this use-case, only the Azure Pipelines service is required. Azure Pipelines is a DevOps service that automates the builds and deployments of applications. The following diagram depicts the final setup:
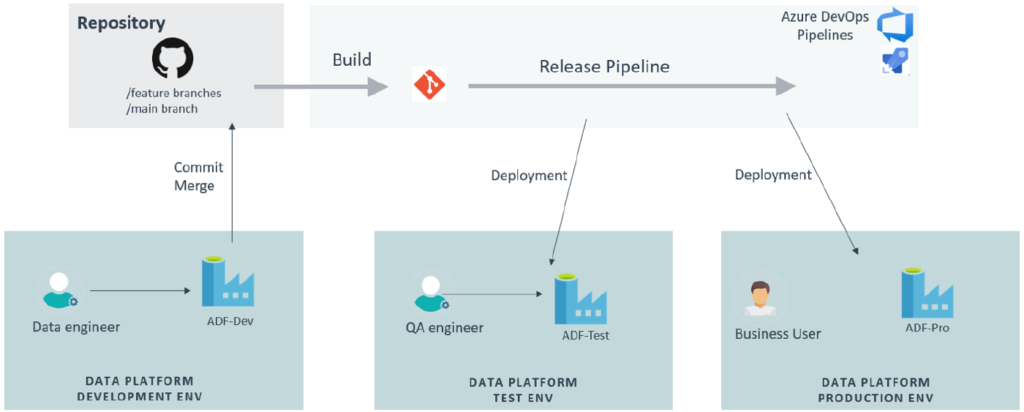
Figure 6: ADF integrated with GitHub
ADF documentation proposes the use of the “ARM Template Deployment” task on Azure Pipelines for the continuous deployment phase. However, based on our experience, this approach lacks the capability to delete ADF pipelines. Therefore, due to this limitation, we discarded this approach.
Third party independent software vendors (ISVs) have developed extensions on Azure DevOps Pipelines to deploy ADF code that fulfils all required capabilities.
Nowadays, our preferred option is the “Publish Azure Data Factory” task authored by SQLPlayer. This task publishes ADF code directly from JSON files instead of using the ARM Templates generated by the Publish option on the “adf_publish” branch.
The “Publish Azure Data Factory” task by SQLPlayer task has multiple configuration options in the form of parameters and properties, so that we can have a tight control over which elements of the ADF have to be included in the CI/CD process.
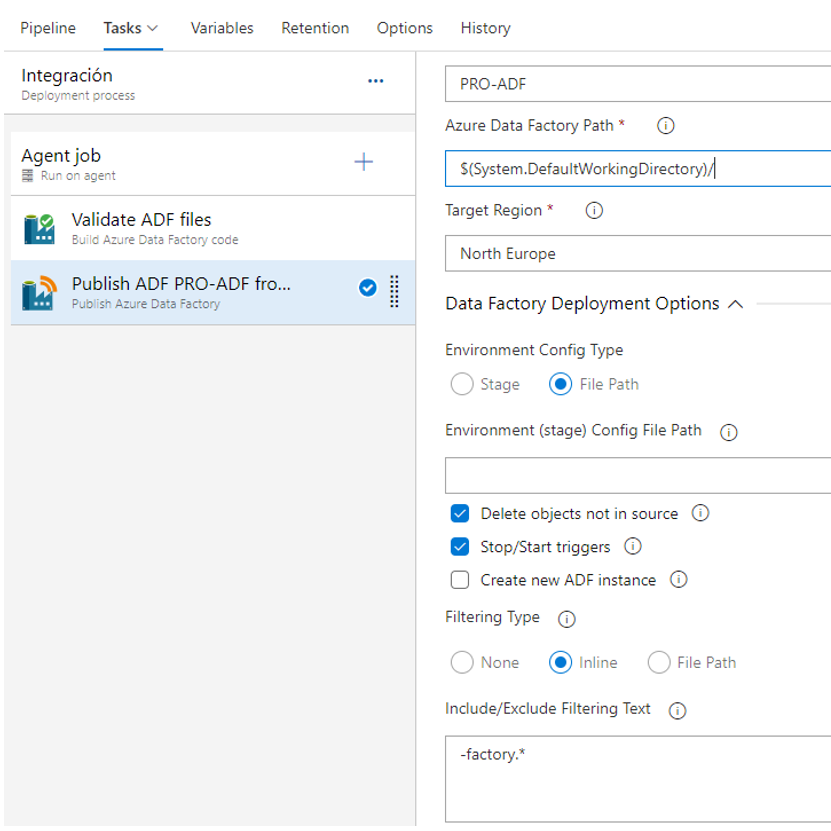
Figure 7: SQLPlayer task on Azure DevOps Pipelines setup
Following the CI/CD methodology, each environment must have the exact same code except for some properties that must be specific to each environment. In our scenario, we have the following shortlist of these properties:
- Global Parameters
- Data Factory name
- Linked Services endpoints (including Azure Key Vaults)
Let us introduce an example of a property which is specific per environment, and a way to implement its deployment across all the environments:
- Suppose the last ADF activity of the data pipeline sends an email to notify the final status of the execution. We want this email to be sent to a different person depending on the environment we are working on:
- Dev environment email to the data engineer
- Test environment email to the QA engineer
- Production environment email to the business user
- In ADF, the email property can be defined by a global parameter value. Let us see a couple of implementation options to make this property specific per environment:
- Manual option: Manually define the global parameter value in each environment. From a theoretical CI/CD perspective, it would not be a correct approach as the process would not be 100% automated. Nevertheless, in cases where data engineers cannot modify the Azure DevOps Pipelines, it might be a workaround.
- SQLPlayer task: This task proposes the use of the “config-env.csv” file per environment, where values of properties can be replaced.
It is obvious that the CD phase requires a fine tuning of how to control all these properties across the three environments.
In addition to the task introduced above, other tasks can also be included on the CD phase. Generic examples of these tasks would be:
- Task to validate the code
- Task to execute tests
- Task to deploy libraries
- Task to stop and start the data pipelines before the deployment (as it is the case for ADF Triggers)
Conclusion
In this article, we have seen how to include Azure Data Factory into a CI/CD process managed by Azure DevOps. This is only one step of the path to apply CI/CD practices to the development life cycle of data pipelines. The rest of the steps to complete the path would be:
- Include the rest of elements of the data platform into the CI/CD process. These elements can include Azure DataBricks, Azure Data Lake Analytics, Azure Logic Apps, Azure Functions, or SQL DDLs and DMLs.
- Define a code branching strategy that adapts to your organisation.
- Implement an automatic testing phase.
Want to find out how our team of certified experts can help you? Simply contact us and we will schedule a hands-on demo so that you can see our capabilities for yourself!
