23 Ene 2025 Data Quality Essentials
This article is part of our Data Governance (DG) mini-series: in the first post, we presented DG as the driver to achieving data excellence, and saw how the key to a successful implementation is to focus on tangible, outcome-driven initiatives. DG shouldn’t just be a theoretical exercise involving data, roles, and ownership, but must cover essential technical domains like the Data Catalog, Data Quality (DQ), Master Data Management (MDM), and DevOps. In this article, we’ll explore Data Quality in depth, examining how it strengthens DG by defining reliable standards, improving data accuracy, and maintaining consistency and completeness throughout the organisation.
In today’s world of data-driven decision-making, DQ has become more important than ever. With an increasing volume and variety of data being generated and consumed ever more quickly by organisations, it’s all about having accurate and reliable data.
Poor DQ can lead to inaccurate insights, ill-informed decision-making, and even financial losses, whilst high DQ can build trust among users and stakeholders, drive innovation, and improve efficiency.
So first let’s have a look at what DQ really means.
Data Quality
Data Quality refers to the degree to which data aligns with and fulfils the expectations and needs of an organisation. It’s a generic term that covers all types of data within any data system, and it involves assessing business rules to pinpoint the root causes of quality issues, thus enabling the implementation of effective solutions.
In other words, any factor that leads to inconsistent, incorrect, unreliable, or untrustworthy data in business processes indicates poor DQ. Common causes include incorrect data entry at the source, inaccurate metric definitions, or flawed calculations. Each issue should be examined individually, as it may require a tailored solution. However, with a robust DQ methodology in place, these errors can be promptly identified, isolated, and addressed—whether through automated actions or by preventing them at the source.
The various ways in which poor DQ can present itself are collectively referred to as DQ Dimensions. The number of DQ Dimensions often varies depending on the source, as different data flows may encounter unique types of errors. However, the most widely recognised DQ Dimensions are:
- Accuracy: The extent to which data correctly reflects the real-world attributes it is meant to represent.
- Completeness: The degree to which all required data is available.
- Consistency: The uniformity of data across different datasets, systems, and processes.
- Integrity: The assurance that data remains intact, secure, and uncorrupted throughout its lifecycle.
- Reasonability: The extent to which data appears to be valid based on common sense or reason.
- Timeliness: The relevance of the data at the time of its use.
- Uniqueness: The guarantee that every data record is distinct and free of duplicates within the dataset.
- Validity: The degree to which data adheres to predefined business rules, standards, or constraints, ensuring it aligns with organisational expectations.
By leveraging these DQ Dimensions, organisations can categorise the issues present in a dataset, assign them priorities, and gain a high-level understanding of the predominant issues within their systems. This approach helps to identify the source of discrepancies, enabling corrective actions and, ideally, preventing future occurrences.
Benefits of Having Good Data Quality
In the end, the purpose of focusing on DQ is to identify and resolve the root causes of data issues, creating a foundation for ongoing improvement. Maintaining high DQ brings numerous benefits to an organisation, including:
- Trust: High-quality data fosters trust among users and stakeholders. Accurate, consistent, and reliable data instils confidence in its use for decision-making, business processes, and strategic initiatives.
- Compliance: Many industries operate under strict regulations requiring precise and secure data management. High DQ ensures compliance with these standards, helping organisations to avoid penalties and to maintain their good standing.
- Efficiency: Clean, reliable data minimises the need for rework, corrections, and manual interventions, by streamlining processes. This leads to lower operational costs, improved productivity, and greater efficiency.
- Organisation-Wide Impact: Quality data supports better decision-making, enhances collaboration, and drives performance improvements across all systems and business units. It serves as a foundation for innovation, growth, and gaining a competitive edge.
- Sustainable Solutions: By defining clear data expectations and assigning responsibilities to the appropriate stakeholders, organisations can respond effectively to any detected issues. Predefined workflows trigger corrective actions, promoting a proactive approach to issue resolution and reducing the likelihood of future incidents.
How to Achieve High Data Quality
Understanding the importance of DQ and having seen the benefits it brings to an organisation, you might ask: What can we do to achieve high DQ?
As mentioned earlier, DQ encompasses not only the accuracy and reliability of the data itself but also the implementation of proactive measures to detect, address, and prevent issues. Achieving optimum DQ is not a one-off task but an ongoing undertaking, requiring the alignment of people, processes, and technologies.
This continuous effort is formalised in the Data Quality Continuous Improvement Lifecycle, which involves several key steps:
- Identify Issues: The process begins with identifying problems within the data. This is achieved through data profiling, which involves analysing datasets to understand their structure, content, and quality. The analysis highlights which DQ Dimensions—such as accuracy, completeness, or consistency—are most impacted.
- Define Rules and Responsibilities: After identifying the issues, we need to identify what makes us think that the data is incorrect. This involves defining business rules that the data must adhere to. Alongside rule creation, roles and responsibilities for Data Quality management should be clearly assigned, determining who is accountable for resolving issues and outlining the steps to follow when an issue is detected.
- Deploy Rules in a DQ Tool: The next step is to deploy the defined rules within a DQ tool. This tool applies the rules to assess datasets and provides automated DQ monitoring by generating reports; in turn, these reports enable the tracking of DQ scores against organisational standards.
- Monitor and Resolve: With the rules deployed and processes established, any recurring issues can be quickly identified and addressed through predefined workflows. Furthermore, the DQ reports provide ongoing visibility into data health, allowing organisations to monitor scores, evaluate progress, and detect emerging issues, ensuring that new problems are identified and managed effectively.
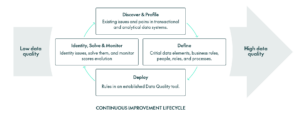
As we can see, this is a cyclical process, where the main goal is to identify the source of the issue, correct it, and then to prevent future incidents. However, in the context of continuous improvement, where new types and formats of data are constantly being introduced, this process is never-ending and requires initiative to be successful and to evolve into a higher level of DQ.
As a final consideration, while the number of DQ technologies and solutions available in the market continues to grow, it is crucial to recognise that the core of the DQ continuous improvement lifecycle lies not in the technology itself, but in the people and processes driving it. What’s more, your DQ goals can often be achieved using existing analytics tools, so when evaluating the implementation of a DQ solution, it is also important to understand the limitations of your current tools and to assess the additional benefits that a new solution might bring.
In particular, implementing a DQ solution with your existing analytics stack offers several advantages: it allows you to easily integrate DQ rules into your current data workflows, providing a consistent and unified experience for users. Further, it enables you to efficiently monitor data quality issues and track DQ scores through comprehensive reports and dashboards, empowering teams to identify and solve issues quickly.
On the other hand, opting for a complete DQ solution provides access to an extensive range of features designed to help you achieve a higher level of DQ. Beyond incorporating the capabilities available within your existing analytics stack, these solutions offer advanced functionalities that enable more effective DQ management, such as a friendly user interface for managing rules, an AI assistant for automatic rule identification and generation, reusable and scalable rules management, workflows for resolving data issues tailored to both business and IT users, and integration with other DG tools.
Some widely used DQ tools are:
- Ataccama: A unified platform that leverages AI to deliver end-to-end data quality, governance, and master data management, making it ideal for organisations seeking automation and scalability in their data processes.
- Informatica: Known for its robust data integration capabilities, Informatica offers a comprehensive suite of tools for data cleansing, standardisation, and enrichment, catering to enterprises that require highly customisable and reliable data quality solutions.
- Collibra: Focused on data governance, Collibra provides advanced data quality features alongside tools for cataloguing, lineage tracking and compliance, making it a go-to solution for teams prioritising collaboration and regulatory compliance.
Conclusions
DQ is a fundamental aspect of any data system, critical to ensuring that data remains accurate, consistent, and reliable. By prioritising DQ, organisations can build trust among users and stakeholders, ensure compliance with regulations, enhance efficiency, foster innovation, and gain a competitive edge. Achieving and maintaining high DQ requires a proactive approach that integrates people, processes, and technologies within a continuous improvement lifecycle. This lifecycle encompasses discovering, defining, deploying, identifying, solving, and monitoring DQ issues, and by adhering to this structured process, organisations can elevate their data quality standards and unlock the full potential of clean, reliable data.
If you are considering implementing DQ practices in your organisation, our experts at ClearPeaks are here to help! With years of experience in delivering data-driven solutions and a deep understanding of DQ processes, our team can assess your current strategy, integrate a new solution into your existing analytics stack, or implement a comprehensive DQ platform. Reach out to us for more information and let us help you craft a tailored solution that meet specific needs, ensuring that you can maximise the value of your data while promoting trust, efficiency, and compliance.
