20 Nov 2024 Unlock The Power of AI with Matillion’s Latest Features
In our rapidly evolving world of data integration and transformation, Matillion has taken a big step forward by introducing AI-driven features into its platform, revolutionising the way businesses manage their data pipelines. With the introduction of several cutting-edge tools, Matillion is enhancing traditional ETL/ELT processes, making them smarter, faster, and more efficient.
In this blog post we’ll explore Matillion’s new AI capabilities, their impact on modern data workflows, and how they compare to conventional data integration methods. We’ll dive deep into specific use cases of their AI Prompt component, discover the Auto Documentation feature, discuss the many benefits of RAG, and explain how their Copilot acts as an intelligent assistant to streamline operations. Finally, we’ll be testing these AI features in two real-world scenarios, showcasing their transformative potential. So let’s take a closer look at how Matillion is harnessing AI to redefine data transformation!
Matillion’s New AI Capabilities
Matillion has introduced four powerful AI-driven features designed to enhance productivity and efficiency in data engineering:
- AI Prompt Component: This new capability empowers data engineers to transform data processing and analysis across OpenAI, Azure, and AWS environments. By leveraging LLM technology, pipelines can generate insightful responses to user prompts, adding valuable context to data workflows. Later we’ll look at some different cases using these brand-new Matillion components.
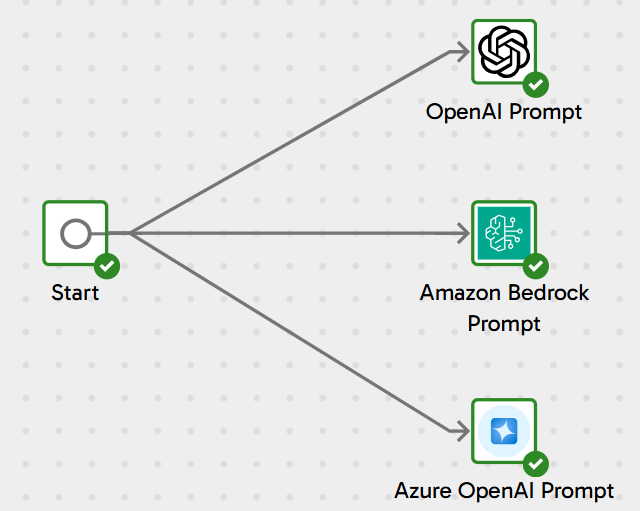
OpenAI, Amazon, and Azure new components
- Auto Documentation: Matillion’s new AI Auto Documentation feature helps to generate automatic documentation for data pipelines. By right-clicking on any component and selecting the Add note using AI option, users can produce descriptions of a pipeline’s logic. The feature enables markdown formatting, allowing users to highlight key sections in bold or with background colours. It also offers options to regenerate or modify the documentation generated, making it easier for teams to collaborate and understand pipeline processes without too much technical knowledge. This feature boosts productivity whilst also offering flexible customisation:
Note created with Auto Documentation
- Retrieval-Augmented Generation (RAG) components: Typically, an LLM operates like a student taking an exam without access to external resources, offering educated guesses or, at times, failing to provide answers altogether. However, with RAG, the LLM gets an «open book», allowing users to supply it with specific, relevant information to enhance both the accuracy and precision of its responses. An LLM may struggle to provide the most up-to-date or detailed insights, especially when it comes to recent events or very specific topics—like the intricacies of your company’s proprietary product line—even if there is plenty of publicly available data. This is where RAG plays a critical role: by integrating external, often private, data into the LLM’s response process, users can significantly improve the model’s performance. Matillion’s new RAG components enable users to load data into popular vector stores, such as Pinecone or PostgreSQL (which is open-source), allowing the system to leverage private, unstructured data, enriching the context for more accurate and relevant responses. Whether it’s product specifications, internal documents, or other proprietary knowledge, RAG ensures that the LLM can tap into the right data sources to generate tailored, insightful answers. What’s more, this capability helps to close the knowledge gap, letting users generate responses that are not only more reliable but are also specific to their business needs.
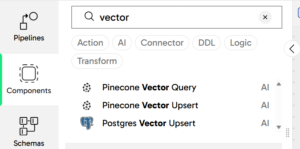
New components to leverage RAG
- Copilot: This powerful feature revolutionises how data engineers build pipelines. Copilot allows users to create complex data workflows using natural language inputs, reducing the need for manual coding. Not only does it accelerate pipeline development, but it also offers real-time support, helping users to optimise their data transformations and integrations. By simplifying the process, Copilot lowers entry barriers, making data engineering more accessible. It empowers a wider range of team members—from data engineers to analysts—to actively contribute to data initiatives, fostering greater collaboration and innovation across the organisation. Currently, Copilot is only available for transformation pipelines, but Matillion’s offering is continually evolving. Future updates are expected to expand its functionality, making it an even more robust and versatile feature. As Copilot improves, it promises to play a key role in democratising data engineering, transforming the way teams approach data management.
Building a pipeline with Copilot
These cutting-edge features are going to significantly enhance productivity and drive innovation in data engineering. We considered a few features to be of particular interest, so we decided to explore them hands-on to see if we could identify any practical applications. Take a look at what we discovered!
AI Prompt Component
The new AI Prompt components in Matillion are an exciting addition enabling you to use advanced language models, such as ChatGPT, within your data integration workflows, and we used our own ChatGPT account to check how the tool behaves in certain scenarios. First, let’s list some common applications in which we can test this brand-new feature:
- Sentiment analysis: Use the AI Prompt component to analyse comments or reviews, such as product feedback or social media posts. This can help the marketing team to monitor brand sentiment in real time, providing insights into customer perceptions and facilitating reputation management.
- Automatic summarisation: Transform extensive reports, news articles, or documents into concise summaries. By speeding up the analysis of long texts, you get quicker decision-making and better productivity.
- Classification of unstructured text: Categorise large volumes of unstructured text, such as emails or support tickets, into predefined categories, optimising customer service workflows and improving content management and classification.
- Translation of multilingual content: When dealing with global customers, use this component to automatically translate content into different languages. This facilitates the internationalisation of products and services, improving the customer experience across different regions.
- Key data extraction: Extract key information, such as names, locations, and dates, from long or complex texts, improving data accessibility and usability.
- Data correction and normalisation: Address data issues such as grammatical errors or inconsistencies in units of measurement. This component improves data quality by automating the correction and normalisation processes, reducing the need for manual data cleaning.
- Content generation from structured data: Utilise structured data, such as sales statistics, to automatically generate insightful content—like conclusions or recommendations—for reports and dashboards. This enhances data interpretation and decision-making.
Now we’ll test the OpenAI Prompt component by exploring the summarisation and classification options, evaluating performance and effectiveness in real-world scenarios.
Use Case 1: Classification Of Unstructured Text
In this use case we loaded a list of blog post titles with the aim of automatically categorising them based solely on the information provided by the title. To achieve this, we used an OpenAI prompt as one of three distinct components in the process. This prompt was configured to classify the titles according to a predefined list of eleven categories. Additionally, we gave the model the option to assign a «New Category» if it determined that a post title did not fit any of the existing categories. This setup enabled us to evaluate how effectively the model could both refine its categorisations and adhere to our specific categorisation guidelines:
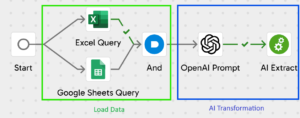
Pipeline loading and analysing data with an Open AI prompt
With Matillion’s handy feature, the Sample data button, you can retrieve a sample of the data passing through each component. In the following image the data sample in a specific component is depicted, allowing us to review and debug the data easily:
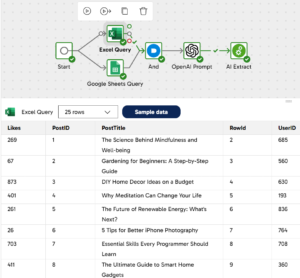
Sampling our data to see what loaded data looks like
After setting up the Matillion connection with Open AI through the API key, the component options allow you to choose the AI model and configure its parameters, as shown in the following image:
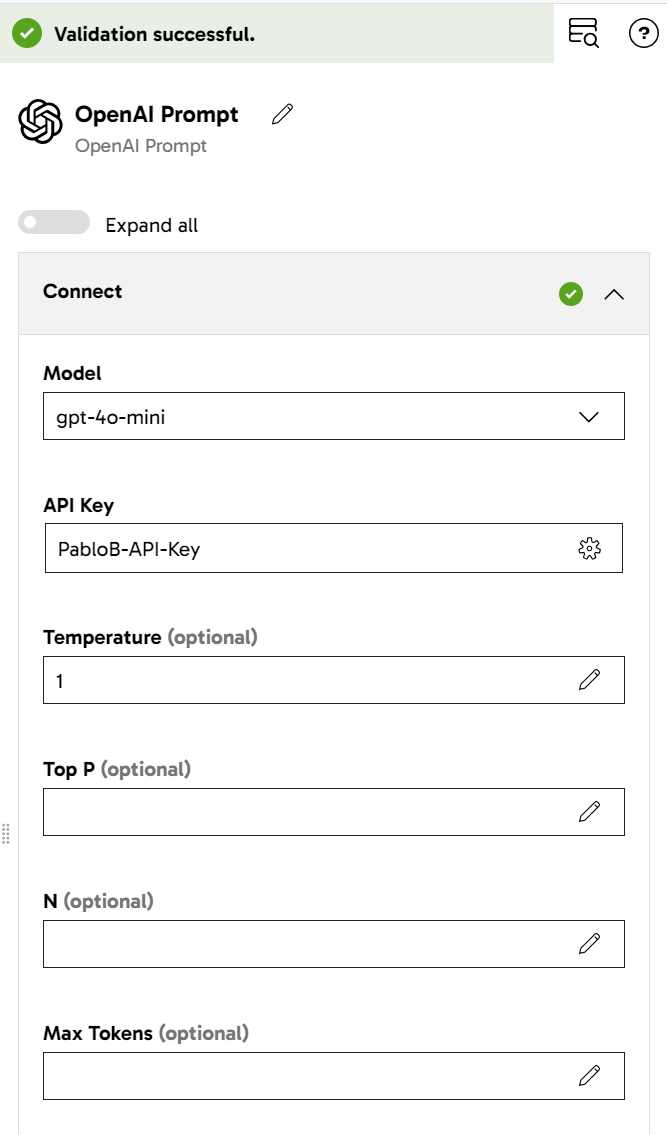
Open AI prompt component settings
Once configuration has been completed, the prompt will need to be defined. In this case, the prompt we used (with models gpt-3.5-turbo and gpt-4o-mini) to generate the CATEGORY column was:
According to the Post Title («PostTitle» column), give a category. You can only select one from this list:
[Science & Environment, Home & Garden, Health & Wellness, Technology & Innovation, Food & Cooking, Travel & Exploration, Fitness & Personal Growth, Finance & Investment, Books & Literature, Pets & Animal Care, Arts & Crafts, Photography & Visual Arts].
Just in case you think there is no way to include the Post Title in the category list, write «New Category».

Here you can add as many columns/outputs as needed
Our choice of this particular prompt allowed us to observe various limitations and potential optimisations. Initially, we tasked the AI with categorising post titles without a predefined list and requested that it avoid duplicating categories with similar wording (e.g., not creating “Gardening” as a new category if “Home and Gardening” already existed). However, this approach revealed a significant limitation. The prompt operates independently for each title, without any memory of previous classifications, and this lack of continuity means inconsistent categorisation, as the model cannot remember which categories it has already used.
We included the option to generate a «New Category» to evaluate the AI’s reasoning capabilities, granting it the flexibility to deviate from standard patterns. However, this slightly increases the risk of AI hallucinations, a well-known challenge in the field.
Below we can see some results, comparing the gpt-3.5-turbo and the gpt-4o-mini models:
A. Gpt-3.5-turbo results:
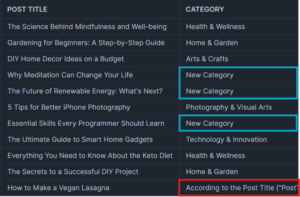
Categorisation results using gpt-3.5-turbo model
As you can see, 3.5-turbo failed at categorising posts. In just these eleven post titles, there are two issues: in red, the prompt given to OpenAI is written as the category, whilst in blue, an incorrect categorisation is highlighted, showing instances where “New Category” was selected despite correct options already being available in the predefined list.
A) Gpt-4o-mini results:
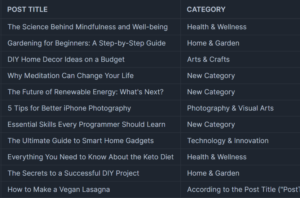
Categorisation results using gpt-4o-mini model
As shown above, the categories match the post titles perfectly. Furthermore, as displayed in the Snowflake statistics, the categories were effectively distributed across the dataset of 1,000 posts. Interestingly, the «Arts and Crafts» category was not used, likely absorbed by other closely related categories; there was no need to create any «New Category».
Compared with the gpt-3.5-turbo model, the quality of this result is even more evident.
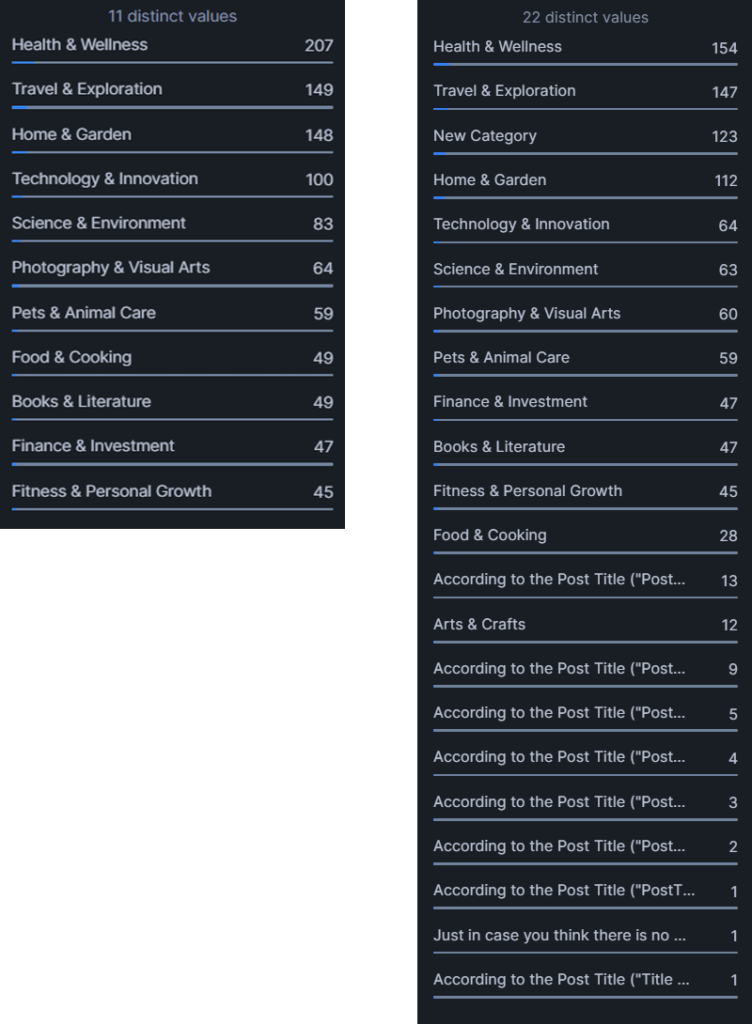
Category distribution (4.o-mini) left and (3.5-turbo) right
Use Case 2: Automatic Summarisation
In this use case we loaded a list of CNN and Daily Mail articles, and we wanted the OpenAI Prompt component to summarise them into a few lines, as well as extracting three hashtags and finding the country in which the events took place, if possible.
Pipeline loading and analysing data with Open AI prompt
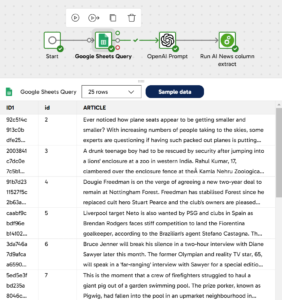
Sample data loaded for review
We asked the AI to fill three new columns using the following prompts (only using gpt-4o-mini):
- Summary: Outline the highlights of each article in 4 sentences maximum.
- Hashtags: Extract 3 hashtags from the article.
- Country: State the country where it happens; if that can’t be located, write “undefined”.
We must remember that each new column means more API calls, so costs increase as you request new outputs. One option to optimise costs would be to create a prompt that encompasses all three and returns a JSON file to be parsed. However, this option would have to be tested first to make sure the model understands the three requests separately and returns an ordered output:

Here you can add as many columns/outputs as needed
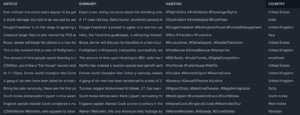
Results obtained with the specified outputs
These AI results align with what we were expecting: the summaries and hashtags are correctly related to the article, although some values were “undefined” in the Location column.
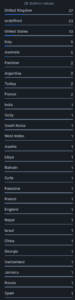
Countries distribution
The top two rows show 27 news stories from the UK (which makes sense as the dataset comes from CNN – Daily Mail) and 23 undefined.
All other entries in the list are actual countries, indicating no hallucinations. However, it is notable that the model used the term “West Indies”, which refers to a region rather than a country. On reviewing the article, «West Indies» is indeed the term used, but it would be advisable to clarify if exact country names are needed, as any variation in terminology could disrupt a join operation with another table.
Reviewing the 23 articles where the country was undefined shows that these results were equally well categorised, as news about movies, technology or generic information does not have locations mentioned.
Here’s an example summary extracted from an article using AI:
Summary:
Experts are raising concerns about the shrinking size of plane seats, suggesting it could jeopardize passenger health and safety. A U.S consumer advisory group criticized the lack of minimum space regulations for humans compared to animals. United Airlines, for example, has reduced its seat pitch to as little as 30 inches, causing discomfort for travelers. The Federal Aviation Administration has been conducting tests based on an outdated standard of 31 inches, prompting calls for a review of these practices.
Hashtags: #FlightSafety #AirlineSeats #PassengerRights
Country: United States
Through the AI Prompt component, we have seen how using language models can simplify complex tasks like text classification or summarisation. These real-world examples have proved its potential to automate traditionally time-consuming tasks, unlocking a wealth of possibilities.
In the first use case, we utilised the OpenAI Prompt component to categorise various post titles. We ran the component using two different models—gpt-3.5-turbo and gpt-4o-mini—and compared the results from each model to assess their performance and accuracy.
In the second case, we used the same component to perform three tasks on an article’s dataset: to generate summaries, to extract three relevant hashtags, and to identify the country where the event took place.
Pros | Cons | |
|---|---|---|
|
|
With reference to the AI models themselves, users must remember that each request has a price. As we observed in the first real use case, the effectiveness of the gpt-4o-mini model is much greater than that of the gpt-3.5-turbo, and it’s also significantly cheaper on a per-token basis, whilst offering a much larger context capacity (128K tokens vs. 4K) and additional vision capabilities, making it ideal for complex tasks involving large datasets or multimedia. Although gpt-3.5-turbo is faster for simple text-based tasks, it comes at a higher cost per token, making gpt-4o-mini a more cost-effective and versatile option for most use cases.
However, it’s important to note that using AI on large datasets should be carefully managed for specific events, as the computational costs can become significant when applied to extensive datasets on a daily basis.
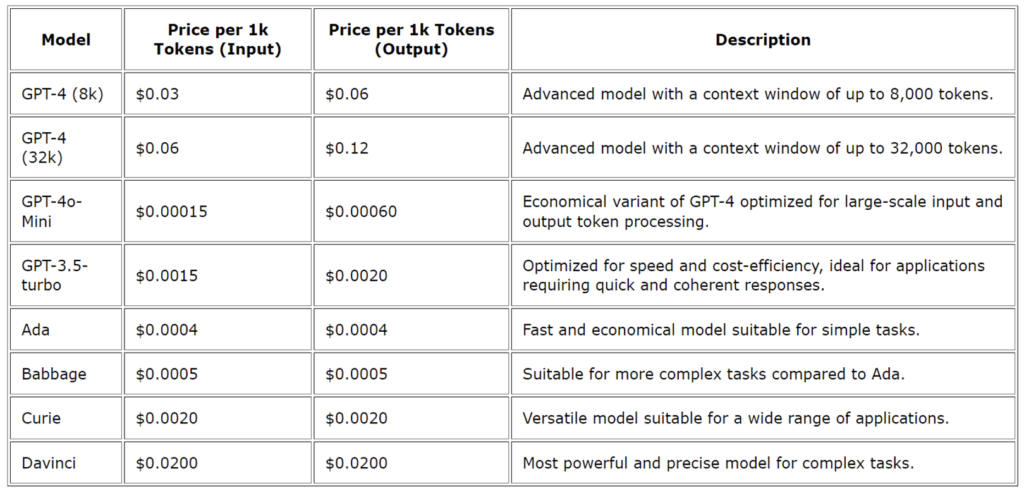
Cost table per model
Auto Documentation
Now that the OpenAI component has been tested, let’s see how to use the Auto Documentation feature in the same pipeline as before.
All components from the previous pipeline were selected for this use case, but feel free to choose as many as you need. Once your components have been selected, simply right-click on the canvas. Below the standard Add note option, you’ll see Add note using AI, so click on that to let the AI generate helpful documentation for your pipeline.
How Auto Documentation works
Initially, the AI provides a comprehensive explanation of the process. However, by using the Refine button located in the bottom-left corner, we can condense the content to better suit our needs. You also have the option to further elaborate or regenerate the documentation as necessary.
After adding the note with the button in the bottom-right corner, you can customise its appearance by changing its colour or editing the text manually. The notes support all standard markdown syntax, offering a high level of customisation to tailor the documentation to your preferences.
Conclusions
To sum up, Matillion’s new AI capabilities represent a big step in the right direction when it comes to data integration and transformation. The introduction of the elements mentioned in this blog post – AI Prompt Components, Auto Documentation, RAG Components, and Copilot – speaks volumes about Matillion’s commitment to bringing the latest AI capabilities to users, transforming traditional ETL/ELT dataflows into AI pipelines.
As we said, whilst traditional pipelines are designed to handle structured data, AI pipelines excel at processing unstructured data, such as text or PDFs. Nevertheless, even though AI offers immense potential, several challenges must be addressed to fully harness its benefits. For AI models to perform effectively, data must be properly prepared and cleaned, particularly when dealing with large volumes. Without a streamlined ingestion process, AI models may struggle to deliver meaningful results.
In our opinion, Matillion is clearly ahead of the competition.
- Copilot is a powerful tool, and it will be even more impressive with upcoming improvements to support orchestration pipelines and improve accuracy for complex tasks.
- Auto Documentation stands out for its ability to effortlessly generate comprehensive documentation, saving time and effort.
- The AI Prompt component unlocks new possibilities, especially for industries that deal with unstructured data, like marketing or healthcare. Whilst costs may be a factor, it is best leveraged strategically or as a fallback when pipeline execution faces challenges. For businesses with limited programming expertise, this feature simplifies complex tasks and streamlines operations, especially with tedious workflows.
- Finally, RAG components provide a powerful way to integrate external data into LLM-driven processes, significantly boosting performance. As with the AI Prompt component, it’s essential to factor in the associated costs when planning its use.
Overall, the addition of these AI-driven functionalities enhances Matillion’s intuitiveness and capabilities. When the right use cases arise, these tools offer a high degree of flexibility and efficiency.
AI pipelines are undoubtedly revolutionising the way engineers interact with data. Instead of relying on SQL, Python, or other programming languages, users can leverage natural language queries, lowering the technical barrier and making data interaction more efficient. Given the challenges of data ingestion and database management, one might wonder: will AI eventually overcome these obstacles and become reliable enough to fundamentally reshape the role of data engineers?
Here at ClearPeaks, our expert team is ready to guide you in harnessing the full potential of Matillion’s latest AI-powered features. Connect with us today to unlock the future of AI-driven pipelines—building smarter, faster, and with the latest technology at your fingertips. Let’s shape your data strategy for success!
