21 Ago 2024 End-To-End MLOps in Cloudera
This blog post is a continuation of our series on end-to-end Machine Learning Operations (MLOps), where we explore different ways of implementing this methodology. In previous articles, we have shown how to design and build robust and efficient ML pipelines in Databricks and Microsoft Azure. In these articles, as well as introducing the MLOps methodology, we have also covered key concepts such as using Continuous Integration/Continuous Delivery (CI/CD) to automate model training, testing and deployment, presented important technologies like MLflow, Azure DevOps or GitHub Actions, looked at data shift monitoring components, and explored Databricks Feature Stores, amongst other things.
We’ll now go a step further by introducing a refined MLOps approach that incorporates code quality checks, rollback, and also separates CI from CD to improve the workflow. And all of this in Cloudera, a multi-cloud, hybrid data platform offering its own ML services. Keep reading to learn how to implement a complete, end-to-end MLOps pipeline in this platform!
Why Cloudera?
With so many tech options available nowadays for the implementation of MLOps, let’s see what makes Cloudera a competitive platform.
![]()
Cloudera is an ideal platform for operationalising ML projects, offering a comprehensive environment that integrates essential components. It unifies data engineering, data warehousing and analytics capabilities, all supported by scalable, high-performance computing and robust security measures.
To fully harness the potential of all this technology, Cloudera simplifies the process by offering its own ML platform, Cloudera Machine Learning (CML). This Kubernetes-based service is part of Cloudera Data Platform (CDP) and provides a unified space to collaboratively develop data science solutions using the ML-relevant, native tools that Cloudera provides. Note that both CDP and CML are available on both private and public cloud, so Cloudera has you covered whether you want to run your workloads on-premises, on cloud, or even in hybrid scenarios.
In this article we will be focusing on the following tools and capabilities to develop our MLOps architecture:
- Jobs and Pipelines: This built-in scheduling system is key for the creation of automated CI and CD pipelines, which are used to streamline the building and deployment of new models.
- Model Registry: This recent feature enhances the traceability and visibility of the models created, keeping them in a centralised location, readily deployable and accessible by multiple projects inside the same workspace.
- Deployment Capabilities: Programmatically deploying an ML model with Cloudera is easy with its comprehensive and powerful Python API. With just a few lines of code, models can be registered and then deployed to REST APIs, accessible via HTTP requests.
- MLflow Compatibility: MLflow is one of the most useful and popular tools for productionalising ML, as it enables easy logging and the retrieval of ML metadata. CML is perfectly integrated with MLflow, aiding model comparison.
- Seamless Access to Git: The power of distributed version control platforms, such as GitHub or GitLab, can be fully leveraged by directly integrating them with CML.
When compared to other platforms, CML stands out in production for being straightforward to use while also being complete and versatile.
Use Case Overview
Now let’s demonstrate an end-to-end execution of the implementation by using a public dataset along with different model architectures.
Our usage scenario centres on the Individual Household Electric Power Consumption dataset, an extensive, multivariate time series use case. It consists of more than two million minute-by-minute observations of electric power measurements from a single household, spanning more than three years. Our goal is to forecast one of the nine features of the dataset, specifically the minute-averaged global active power.
We have developed two initial models: one based on Multiple Linear Regression and the other on the XGBoost architecture. These models will be refined to produce new versions which will be automatically trained, tested, and deployed, enabling us to efficiently explore new solutions in a systematic and organised way.
Solution Design Overview
The basic elements and building blocks of this architecture are CML jobs. A job automates the process of launching an engine, running a script, and tracking the results. Moreover, its execution environment can be customised, arguments can be passed, and email alerts configured.
Jobs can be linked together to form pipelines, which can be thought of as a series of automated tasks executed in a specific order. Each job runs only after the preceding one completes, ensuring tasks are executed sequentially. In other platforms, this would typically be achieved by creating YAML files.
This approach allows us to maintain a modular codebase, making both debugging and identifying improvements easier. Figure 1 shows an example of the configuration menu of a CML job. In this example, we are creating a job to automatically test the model using the test_model.py script. The Schedule option is set to Dependent, referencing the Train Model job, effectively coupling them.
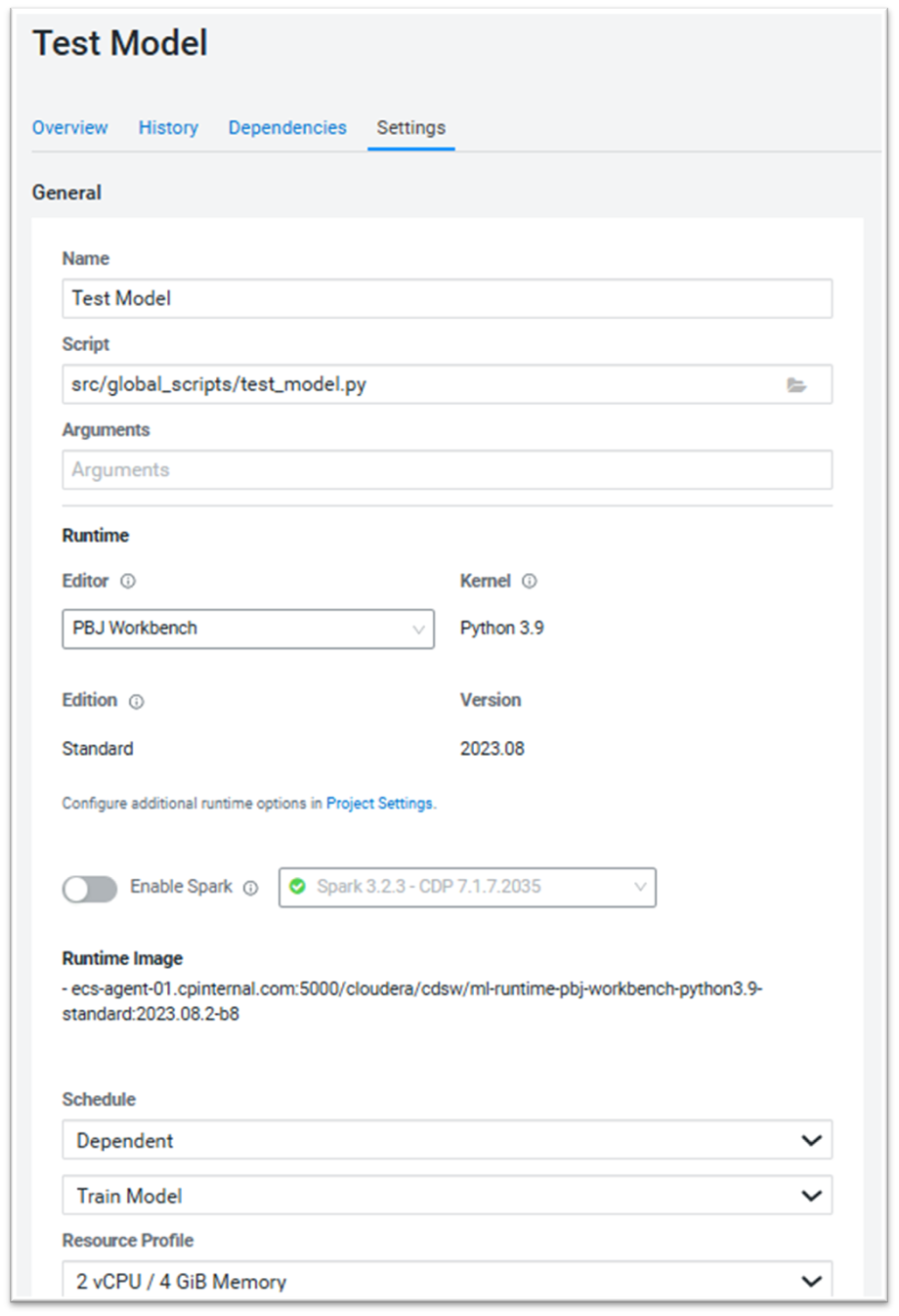
Figure 1: CML Job configuration menu
To version and centrally store all the code corresponding to the pipelines and the ML models themselves, a GitLab repository is also created. Using the personal CML SSH key, this repository can then be cloned directly within Cloudera, as one would normally work locally. For more information, see Git for Collaboration.
CML jobs and pipelines are integral to defining the backbone of any MLOps implementation, particularly automated CI/CD pipelines to streamline the process of building and deploying new models. Figure 2 illustrates this concept and also highlights other important functions, such as comparing models or registering them in a centralised repository. Keeping a comprehensive record of all generated metadata is crucial for this purpose.
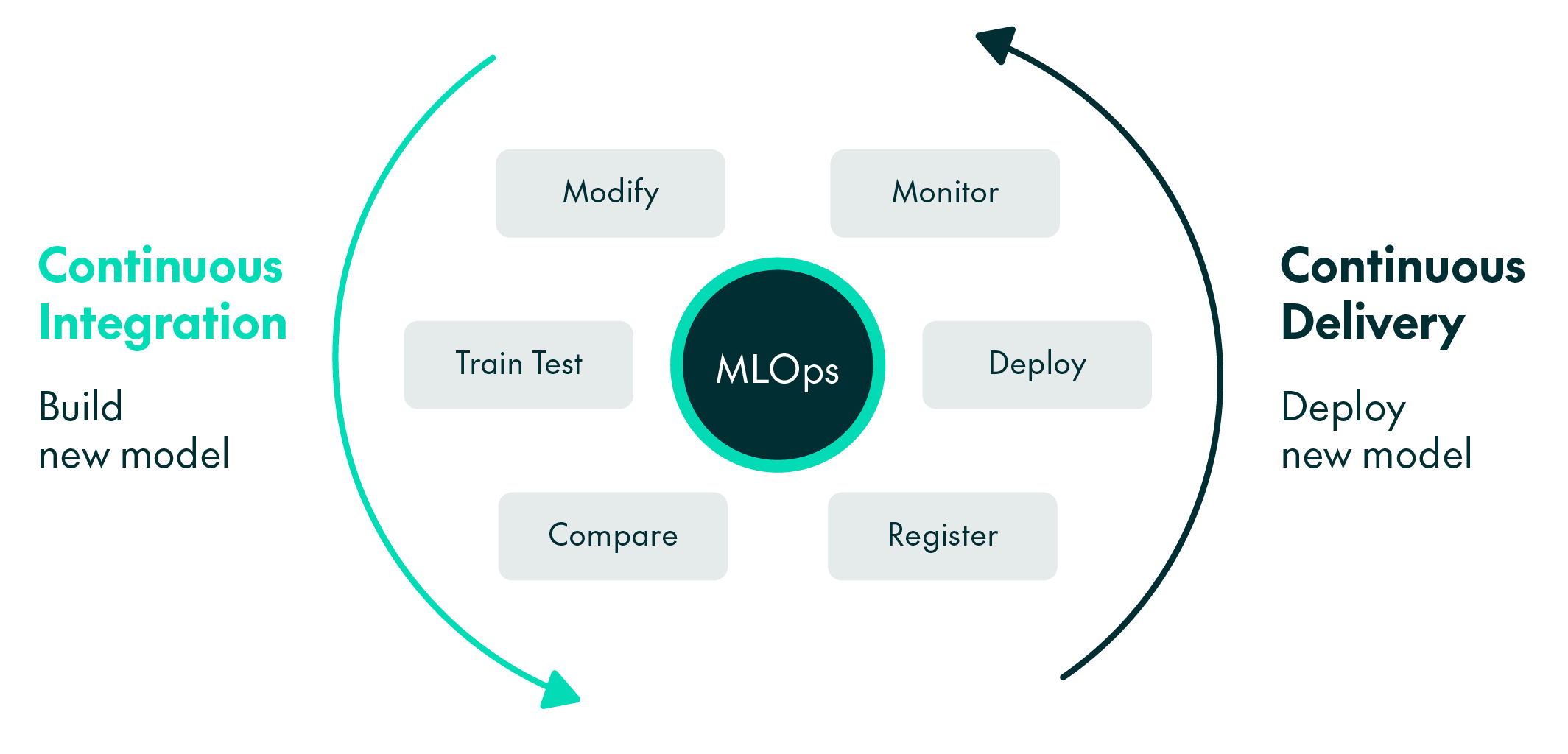
Figure 2: The backbone of MLOps, CI & CD
The implementation shown in this article will also include a third, smaller pipeline to perform a rollback of the deployed model, essentially travelling back in time, redeploying the previous model in production. This feature is particularly useful if a newly deployed model fails to meet performance expectations. Some additional steps have also been incorporated, such as automated code quality checks, enhancing reliability and maintaining standards.
A detailed diagram of the architecture design of this implementation is shown below:
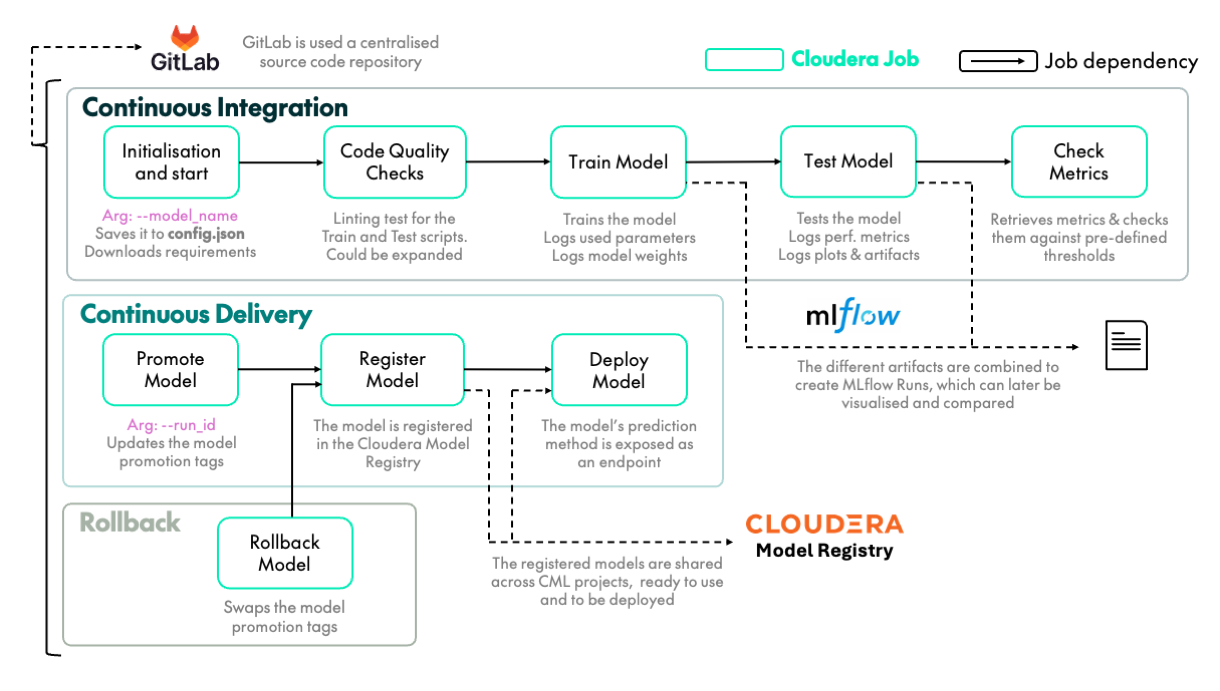
Figure 3: Detailed diagram of MLOps implementation in Cloudera
This architecture overcomes the core challenges of sustainable Machine Learning. It enables the extensive exploration of new models in an organised, methodical way and facilitates the rapid deployment of new solutions, with the option to rollback when necessary.
In the next sections, we’ll explain this design in more detail, exploring the tools used and the logic behind the different jobs. We’ll also dive into the design, explaining selected screenshots of its implementation for the use case mentioned above.
Continuous Integration Pipeline: Building A New Model
After modifying the source code to tweak the existing model or creating a new model architecture, this pipeline can be triggered to build a new, fully trained and tested model, saving all the important information along the way. Below you can find a more detailed explanation of the CML jobs involved, their purposes, and how they accomplish their tasks:
- Initialisation and Start: This job is manually started to initiate the CI pipeline. It receives an argument with the name of the type of model (e.g. Multiple Regression, XGBoost, etc.) that is going to be built, tested, and possibly deployed. Each model type has a corresponding folder in the file system containing a txt file, along with training and testing scripts. The argument is used to point to the right folder and change the behaviour of the pipeline.
- Code Quality Checks: This job performs a linting check on the training and testing scripts to make sure they are error-free and follow standard stylistic practices. If the linter returns an error, the pipeline stops here.
- Train Model: The training script is executed, generating a set of weights which are logged, along with the corresponding hyperparameters, using MLflow. To achieve this, an MLflow run is started and then associated with an MLflow experiment.
- Test Model: The previously trained model is retrieved and tested against a predefined testing set, separate from the training set. Performance metrics and plots are logged using MLflow, associating them with the MLflow run started in the Train Model job.
- Check Metrics: The performance metrics from the previous job are retrieved using MLflow and compared against adjustable predefined thresholds. This process ensures that the newly trained model meets the minimum performance requirements, and any models that fail to do so are automatically discarded.
Continuous Delivery Pipeline: Deploying A New Model
After executing (potentially many times) the CI pipeline, the CD pipeline can be triggered to automatically deploy a new model of choice. Here’s a concise explanation of the jobs involved in this pipeline:
- Promote Model: This job is manually started to initiate the CD pipeline. It requires an MLflow run ID as an argument, corresponding to a particular CI execution deemed suitable for deployment. To facilitate and streamline subsequent jobs, a system of MLflow tags associated with the runs is employed. Specifically, two tags are used: “production” and “previous”, which can be “true” or “false”, indicating whether the model is currently in production or was previously in production.
- Register Model: In this step, the model with the run ID provided in the last job is registered in the Cloudera Model Registry, ensuring that the model is stored in a centralised location, easily accessible and readily deployable. The necessary information is retrieved using MLflow and the tagging system described above, and the registration process is carried out via the CML Python API.
- Deploy Model: Finally, the model’s prediction method is exposed as an endpoint using a set of CML Python API functions. The tagging system is again used to retrieve the necessary information, and the fact that the model is registered in the Cloudera Model Registry significantly speeds up this deployment process.
Rollback Pipeline
On top of all this, a rollback job has also been created to allow redeployment of the model that was previously in production. This interesting feature adds extra flexibility to the MLOps architecture.
This job swaps the “production” and “previous” tags between the current production model and the model previously in production, effectively rolling back to the earlier state. To implement this change, the Register Model and Deploy Model jobs are executed again, without the need to define additional jobs. MLflow and the Cloudera Model Registry are crucial in simplifying and accelerating this process. MLflow manages the tagging system, while the previous model is already stored in the Model Registry.
Inside Cloudera
The jobs and pipelines discussed above are illustrated below with screenshots from the Cloudera Machine Learning User Interface (CML UI) during the execution of our demonstration use case.
Figure 4 displays the list of all the CML jobs defined in the CML UI. Note that two additional jobs, “Register Model (from Rollback)” and “Deploy Model (from Rollback)”, have been created to configure the rollback pipeline. This is necessary because, at the time of writing, a job cannot depend on more than one other job. However, these jobs are identical to the “Register Model” and “Deploy Model” jobs from the CD pipeline:
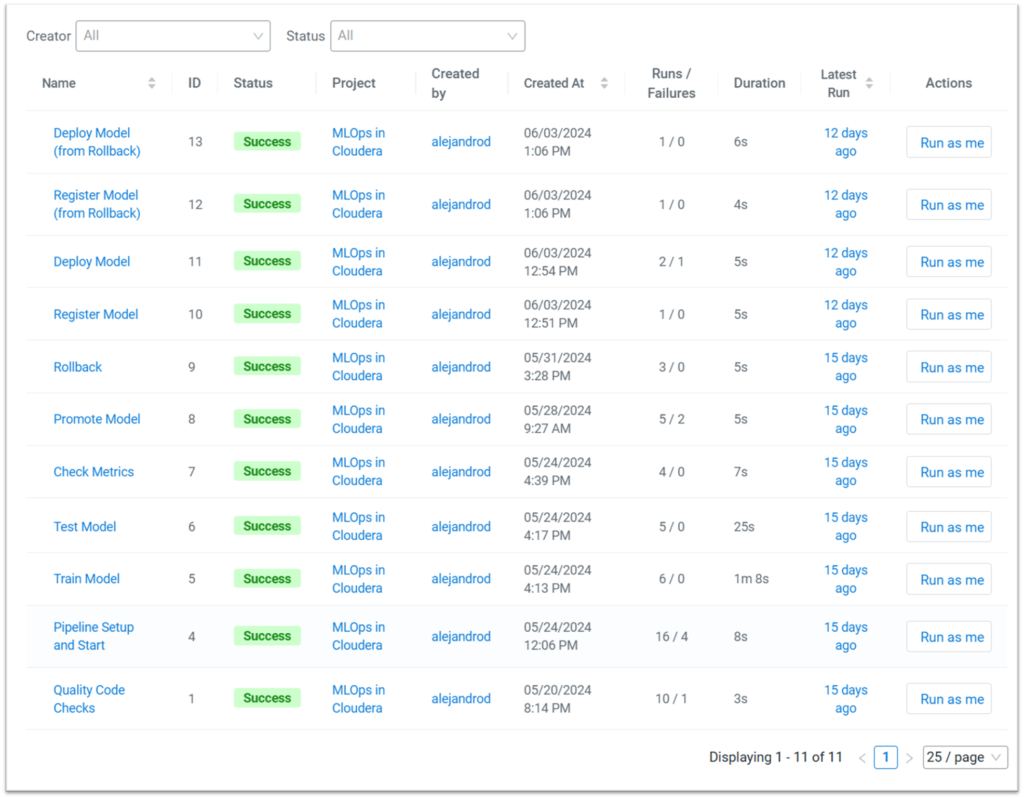
Figure 4: List of defined CML Jobs as shown in the CML UI
Figure 5 shows the three different pipelines – CI, CD, and rollback – defined within the CML UI:
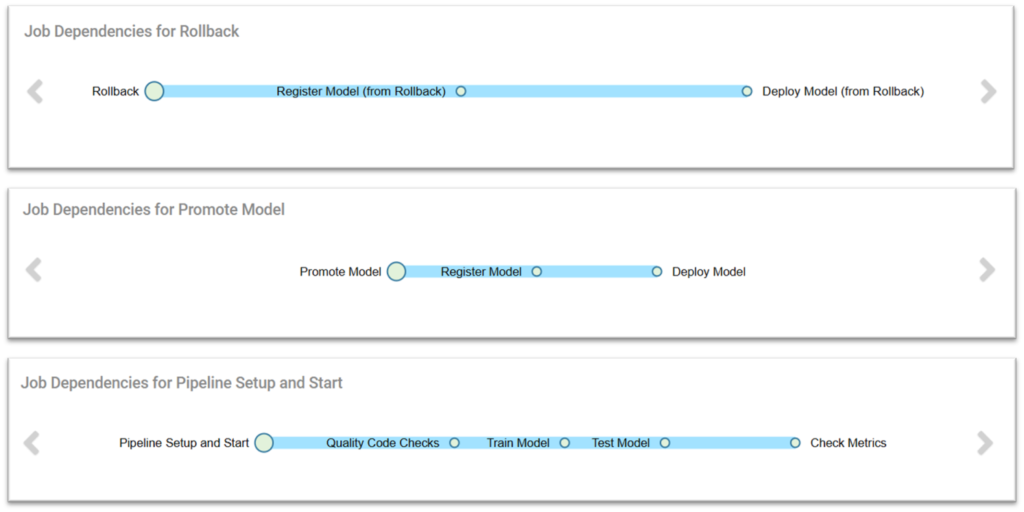
Figure 5: CI, CD, and Rollback pipelines, as shown in the CML UI
Workflow and Implementation
The solution has been implemented and thoroughly tested using the workflow outlined in Figure 6:
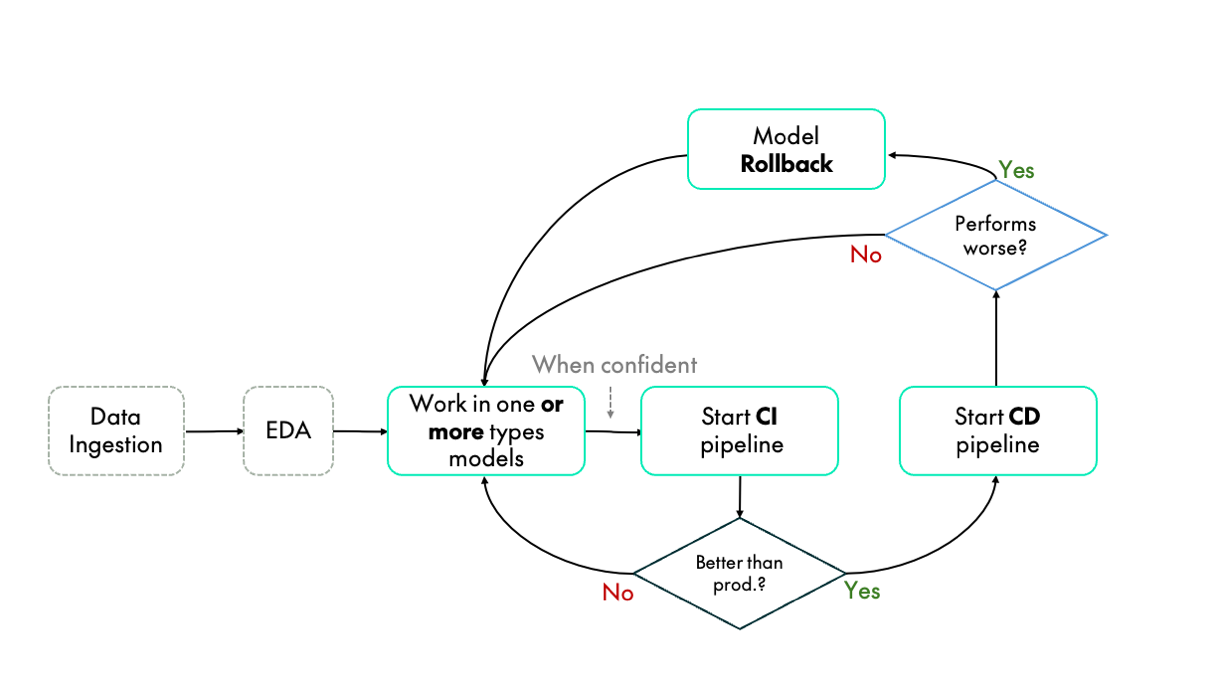
Figure 6: Suggested workflow for MLOps implementation in Cloudera
- Data Preparation and Exploratory Data Analysis (EDA): After preparing and analysing the data, one of the two initial models is modified to produce a different version.
- CI Pipeline: If the new version seems promising, the CI pipeline is started. This pipeline builds a new model, automatically saving all relevant ML information. Initially, no models will be in production. However, once a model is deployed, the newly trained model can be compared with the existing one.
- Model Comparison: After multiple CI pipeline executions, a superior model with better metrics may be identified.
- CD Pipeline: If a superior model is identified, the CD pipeline is triggered to register the model in the Cloudera Model Registry and deploy it.
- Model Rollback: If the newly deployed model underperforms, the rollback pipeline can be initiated. If not, work can continue on developing better models.
Over multiple iterations of this workflow, the CML UI accumulates a wealth of ML metadata, registered models, and other information. Figure 7 illustrates all CI executions encapsulated in MLflow runs, which are automatically displayed in a table format. This table clearly presents the parameters used, the resulting metrics, and other information, facilitating the comparison of different models and the rapid identification of any issues:
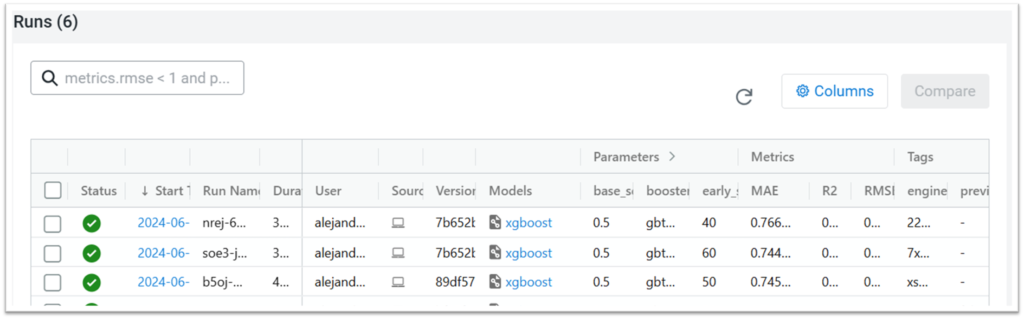
Figure 7: Logged MLflow Runs displayed in a table format, facilitating model comparison
Executing the CD pipeline not only deploys the model but also registers it. All deployed models are registered, meaning the almost instant redeployment of any previously created model if necessary. Cloudera Machine Learning offers a dedicated tab for the registered models. Figure 8 shows this tab after several CD pipeline iterations, displaying the different registered versions of the two model architectures tested:
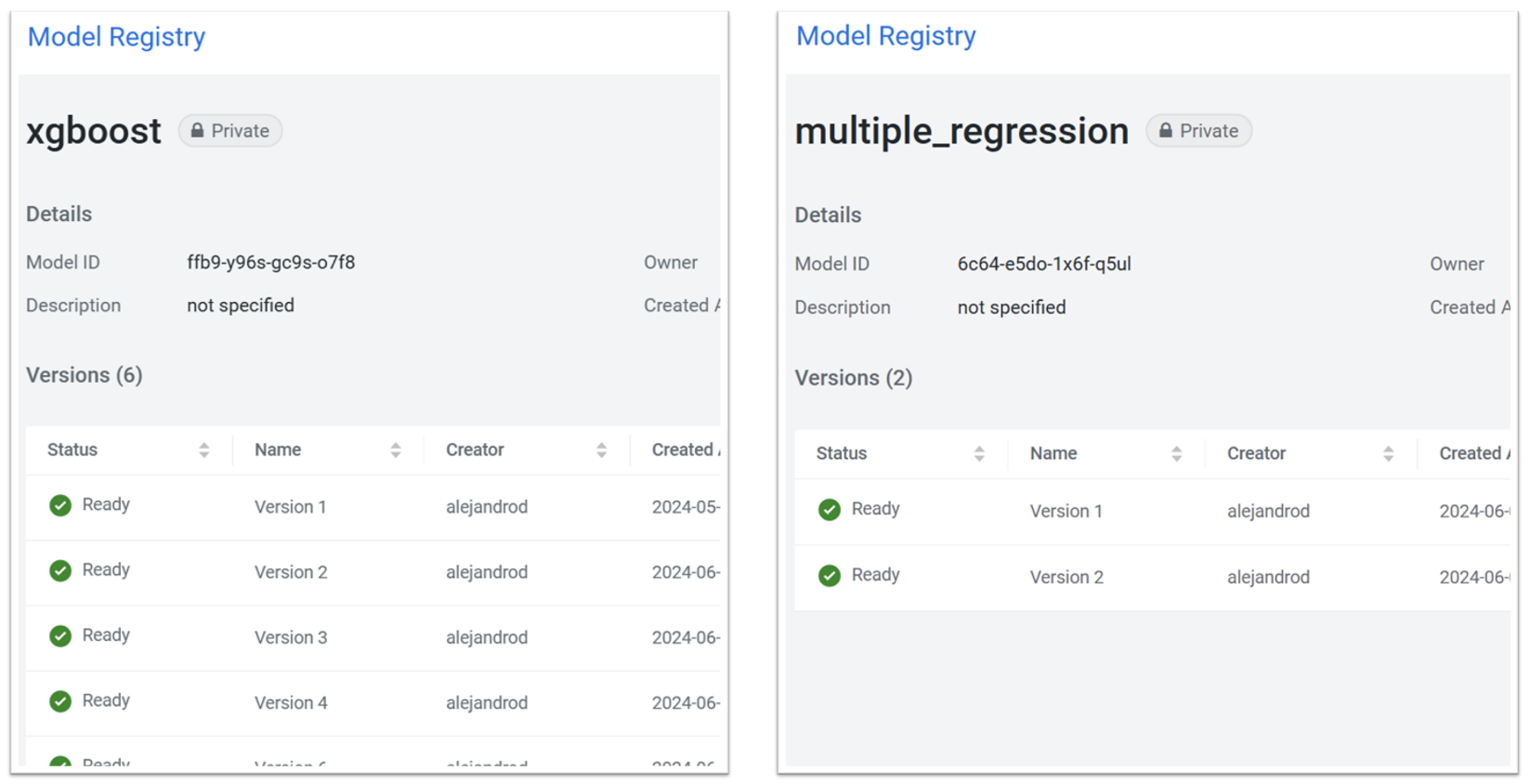
Figure 8: Different model versions registered in Cloudera Model Registry, as shown in the CML UI
A separate tab provides more detailed information for the deployed model. Figure 9 illustrates this tab within the CML UI, including an example of how to access the model using Python:
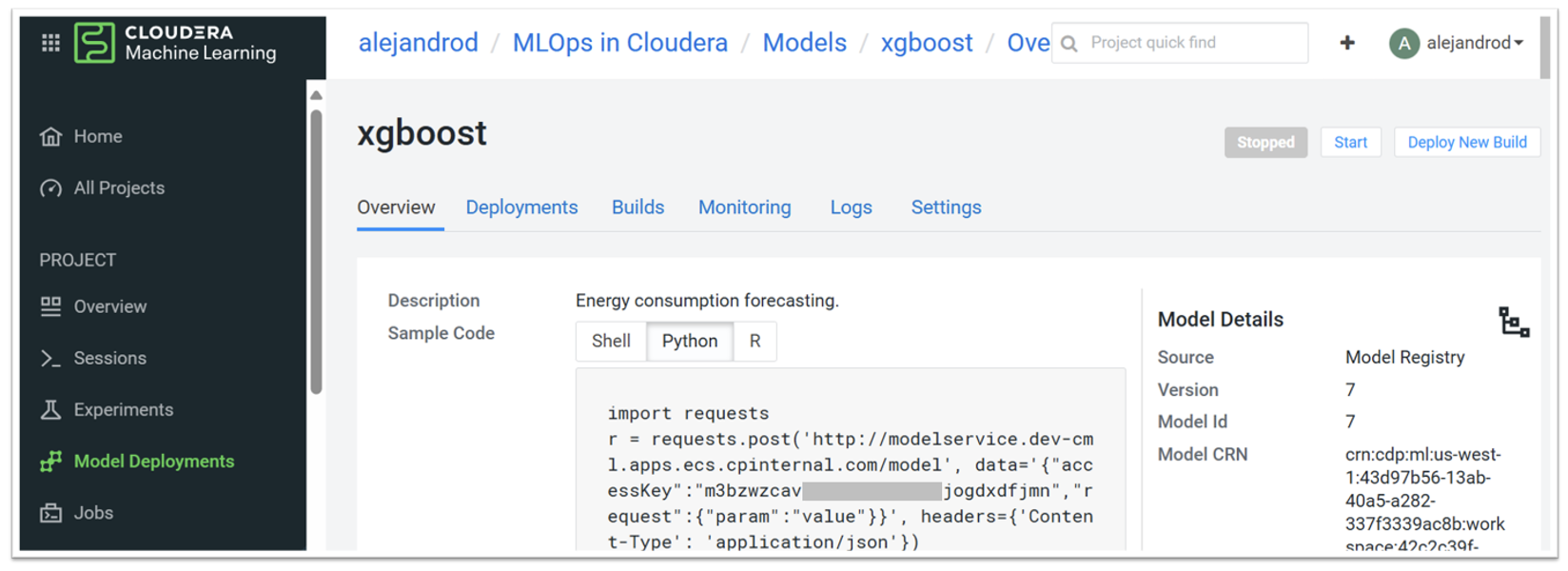
Figure 9: CML Model Deployments tab, showing a deployed model after executing the CD pipeline
Conclusion
As we’ve seen, Cloudera offers a comprehensive suite of tools to build a robust and competitive MLOps architecture. Through the design and use case we’ve explored in this article, we’ve demonstrated the powerful functionalities and capabilities of CML in implementing MLOps workflows.
The design presented here leverages CML jobs as the building blocks to create the crucial CI and CD pipelines, automating the development and deployment of new models. This implementation embodies the essence of MLOps methodology, and it can be tailored and scaled to meet your specific needs, ensuring seamless integration and operational efficiency.
For further insights into MLOps, take a look at our other blog posts: End-to-End MLOps in Azure, and End-to-End MLOps in Databricks.
If you’re considering Cloudera for your Data Science initiatives or looking to deploy an MLOps pipeline that drives real value, contact us for expert guidance. Our team is ready to help you unlock the full potential of your data and achieve your strategic objectives.
