
17 Ene 2024 Oracle Data Lakehouse Implementation
What is a Data Lakehouse?
A data lakehouse is a hybrid data architecture that combines some of the best features of both data lakes and data warehouses, providing a unified platform for both structured and unstructured data, allowing organisations to perform analytics and machine learning on diverse datasets. Enhancing the combined strengths of both, this approach merges a data lake’s scalability and flexibility with the performance and governance of a warehouse into a single, efficient platform.
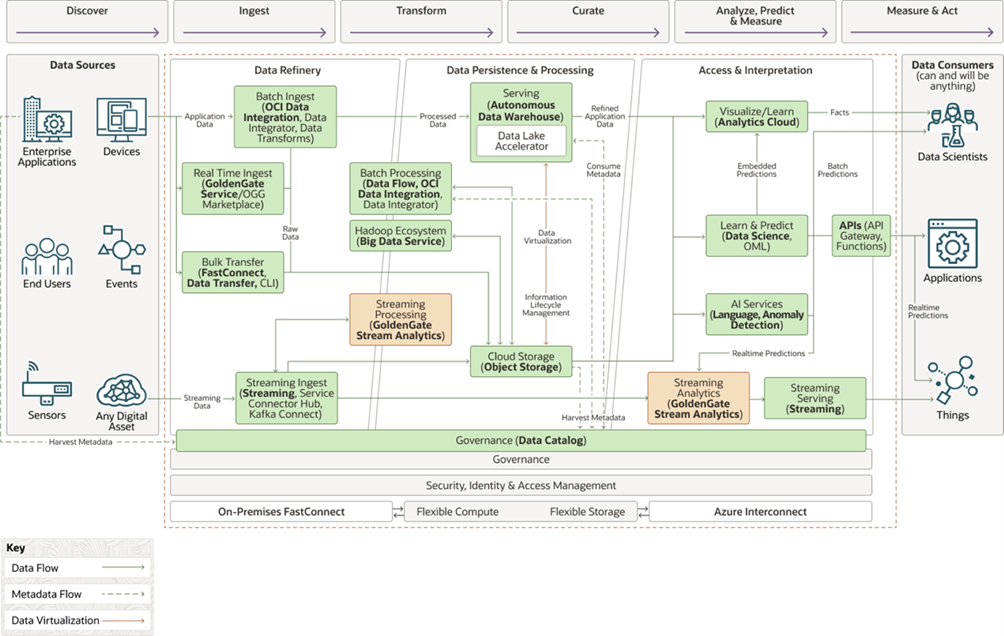
Main Services for Building an Oracle Data Lakehouse
Data Lakehouse: This provides a unified platform for storing, processing, and analysing both structured and unstructured data.
Oracle Autonomous Data Warehouse (ADW): A fully managed cloud-based data warehouse service provided by Oracle, designed for high-performance querying and analytics, where many of the traditional database management tasks are automated, like provisioning, configuration, patching, backups, and scaling.
Oracle Data Integrator (ODI): A versatile data integration tool from Oracle that streamlines ETL processes, effortlessly moving and transforming data from various sources into a target data warehouse. It supports both batch and real-time data integration, as well as being compatible with a wide range of Oracle products and third-party systems.
Object Storage: A scalable cloud storage service that enables organisations to store and manage large amounts of unstructured data, such as images, videos, documents, and backups, providing a secure and flexible way to store data that may not be stored directly within the data warehouse.
Oracle Analytics Cloud (OAC): A cloud-based platform from Oracle for data analysis and visualisation. It empowers users to create interactive dashboards, reports and data visualisations, facilitating insights from their data. OAC provides features for data exploration, advanced analytics, and for sharing insights across the organisation.
Data Catalog: A data governance tool that serves as a central repository for metadata about an organisation’s data assets. It helps users to discover, understand, and manage their data by providing metadata enhancements like tags, custom properties, glossaries, and data lineage information.
Data Science: Data Science in Oracle Cloud Infrastructure (OCI) is based on utilising OCI’s capabilities to analyse data, identify trends, and make predictions. Data scientists work with data to build predictive models that offer insightful analysis that can help organisations to enhance their goods, services, and decision-making procedures. With OCI, they can collaborate to refine models and share their findings, making data-driven insights more accessible and readily actionable.
Sample Database
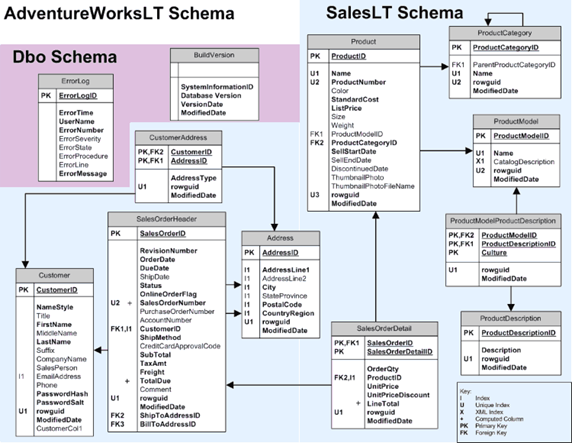
Our idea for this project is based on the Microsoft sample database AdventureWorks, which presents a multifaceted relational structure, capturing different business concepts such as products, customers, sales, and more. Its architecture is comprehensive, and it faithfully mirrors the typical operations of a medium-to-large-sized business.
https://docs.oracle.com/es/solutions/data-platform-lakehouse/img/lakehouse-functional.png
Implementation
Use Case
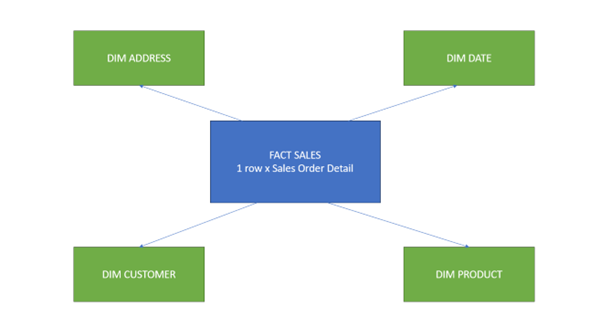
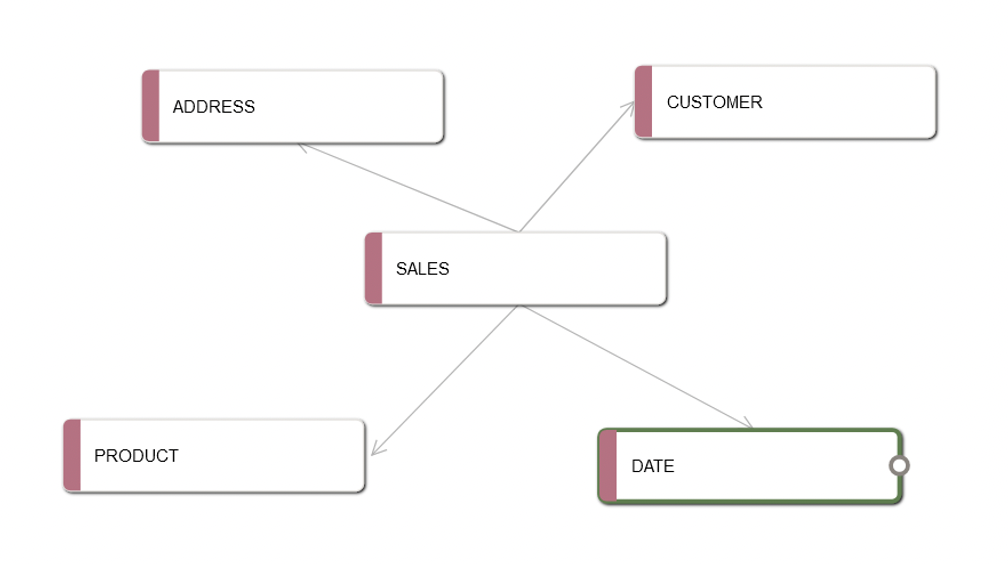
We want to streamline the relational AdventureWorks data for analytical purposes and introduce another architecture: the star schema. This schema, a cornerstone of dimensional modelling, is designed to enhance query performance and simplify the data structure. At its core are the fact tables, surrounded by dimension tables, each representing a point of our star. This structure simplifies querying and reporting by aggregating core metrics at the centre and connecting descriptive dimensions radially.
https://media.cheggcdn.com/media/3be/3be16b7f-64ac-4f3a-8a4f-843a26f7f2fb/php58tpaW
The Autonomous Data Warehouse (ADW) offers us a platform that’s optimised for high-performance queries, perfect for housing our transformed star schema.
The transition from the current structure to the star schema is no small feat, so we’ll need to leverage OCI‘s data integration tools. These tools, adept at handling complex Extract-Transform-Load (ETL) processes, will ensure a seamless data flow from its original structure to our preferred schema, maintaining integrity and optimising for performance.
Once the data has been transformed and housed in the ADW, Oracle Analytics Cloud (OAC) provides us with the tools to create interactive dashboards, drill down into into metrics, and essentially, to extract value from our data. To ensure that this wealth of data remains organised, searchable, and well-documented, we’ll implement the Data Catalog. Acting as a metadata repository, it will enrich our data assets, making it easier for users to discover and understand the data they are working with.
Effectively, our project aims to transform the AdventureWorks data from its intricate relational design to a simplified, efficient, and analytics-ready star schema.
Autonomous Data Warehouse
The ADW in OCI is a fully managed, performance-optimised data warehouse that supports all standard SQL and BI tools. The autonomy of this service means that many traditional database management tasks are automated, including provisioning, configuration, patching, backups, and scaling, thus simplifying operations and reducing human error.
In our case, we wanted to create five tables in a target user of our autonomous data warehouse using SQL Developer and then, with the help of Oracle Data Integrator (ODI), populate them with the appropriate data. In ODI, we start with a source that is another autonomous data warehouse, containing all the initial AdventureWorks tables.
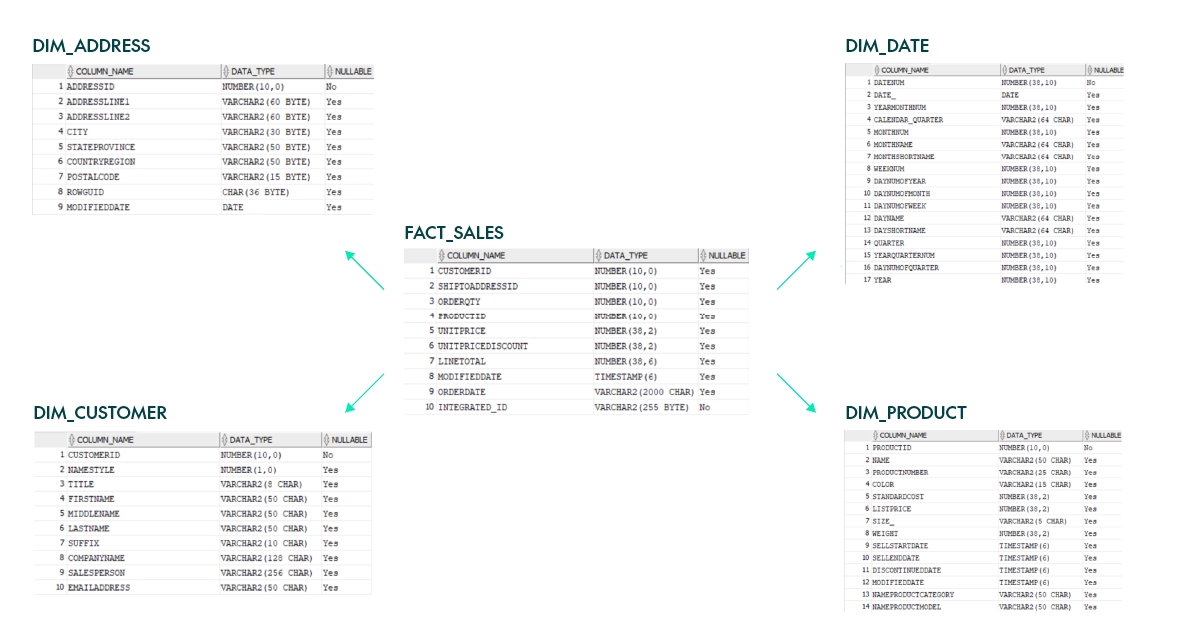
These are the final tables, with the star design:
Data Integrator
ODI is a handy data integration tool that facilitates ETL processes, streamlining data from diverse sources into the Data Warehouse (DWH). ODI’s modular architecture allows for efficient data transformation, ensuring data is analytics-ready upon arrival in the DWH. With features like Change Data Capture and error handling, it supports both batch and real-time integration, as well as being compatible with various Oracle products and third-party systems.
To achieve the desired architecture, we need to follow these steps:
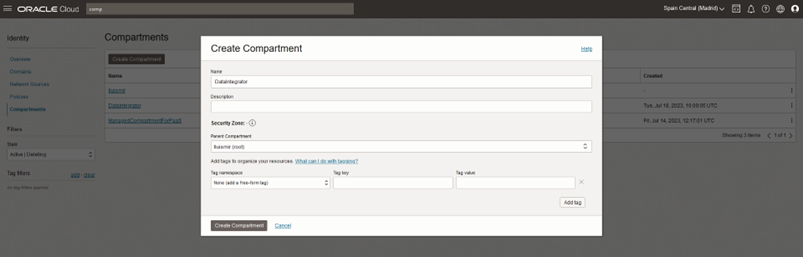
Create a Compartment
Start by establishing a compartment, as the root compartment of the system cannot be utilised for this purpose. In the Compartments section, create a new compartment originating from the root:
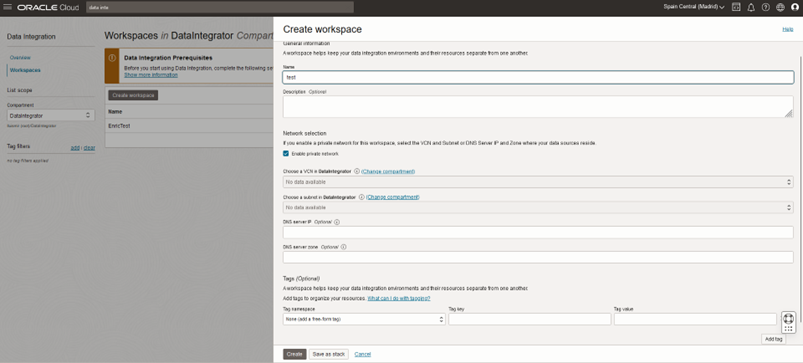
Data Integration Workspace Setup
Navigate to the Data Integration section:

Now create a new workspace, then note down its OCID (Oracle Cloud Identifier):
Setting Permissions
Assign the appropriate permissions for your new compartment and workspace to the policy section. Policies are managed under Identity & Security. Use the provided policy line, making sure to add the correct @CIDO:
-ROOT COMPARTMENT
allow group Dataintegrator to manage dis-workspaces in compartment Dataintegrator
allow group Datalntegrator to use object-family in compartment Dataintegrator
allow any-user to use buckets in compartment Dataintegrator where ALL (request.principal type = 'disworkspace', request principal.id = '@CIDO')
allow any-user to manage objects in compartment Dataintegrator where ALL {request principal type = 'disworkspace', request principal.id = '@CIDO')
-NEW COMPARTMENT
allow any-user {PAR_MANAGE} in compartment DataIntegrator where ALL {request.principal.type = 'disworkspace', request.principal.id = '@CIDO'}
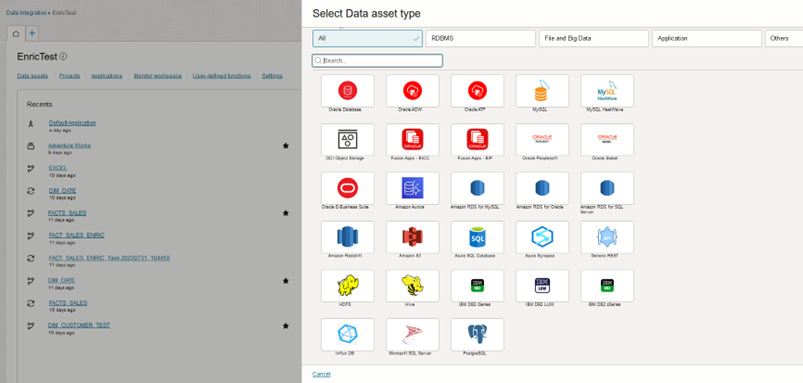
Data Asset Creation
This involves creating an autonomous data warehouse in OCI under the Database section. Use the credentials and wallet to connect via SQL Developer for the necessary table additions or modifications:
Establish Connections
Once your data assets are in place, set up a connection with each one.
Data Flow Creation
Before creating a data flow, ensure a project is set up. Each project will store the necessary data flows.
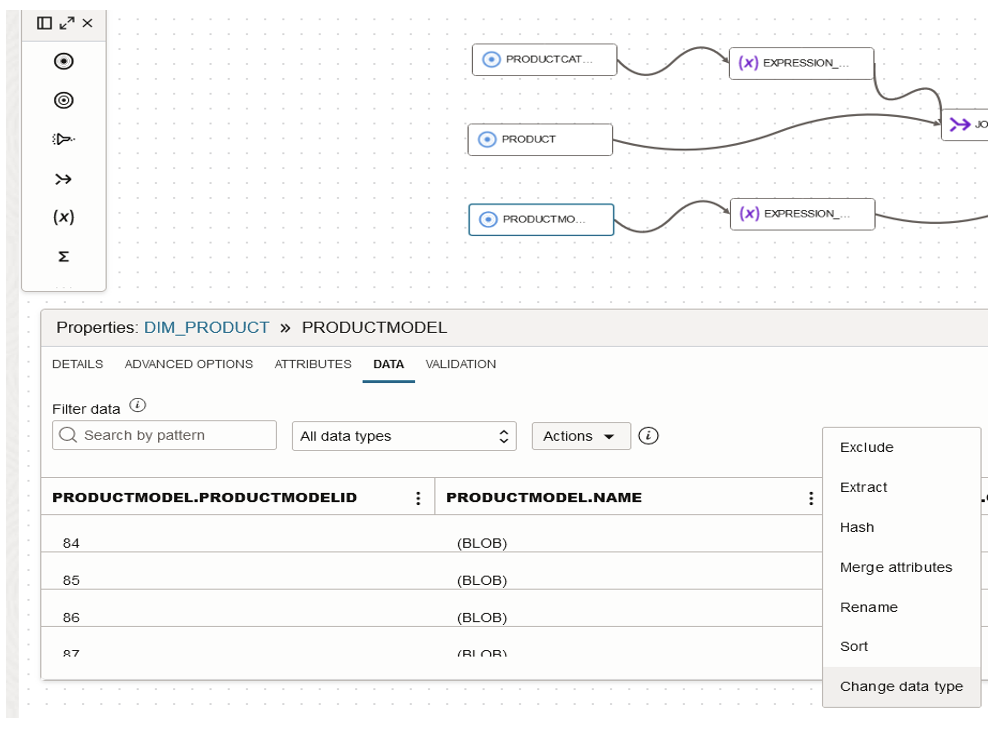
When creating a data flow, check that it has a source and a target. The adjustments will depend on the origin of the data.
Look out for data type mismatches, such as the appearance of the term «BLOB» (Binary Large Object), used in databases to store large amounts of binary data like images or files. Address any mismatches by modifying the data type to ensure it aligns with the nature of the data you’re working with:
Finalising the Data Flow
Upon completing the data flow, integrate all the changes into a target. You can either create a new data entity, or merge rows into an existing database table; then validate the data flow to ensure no errors persist:

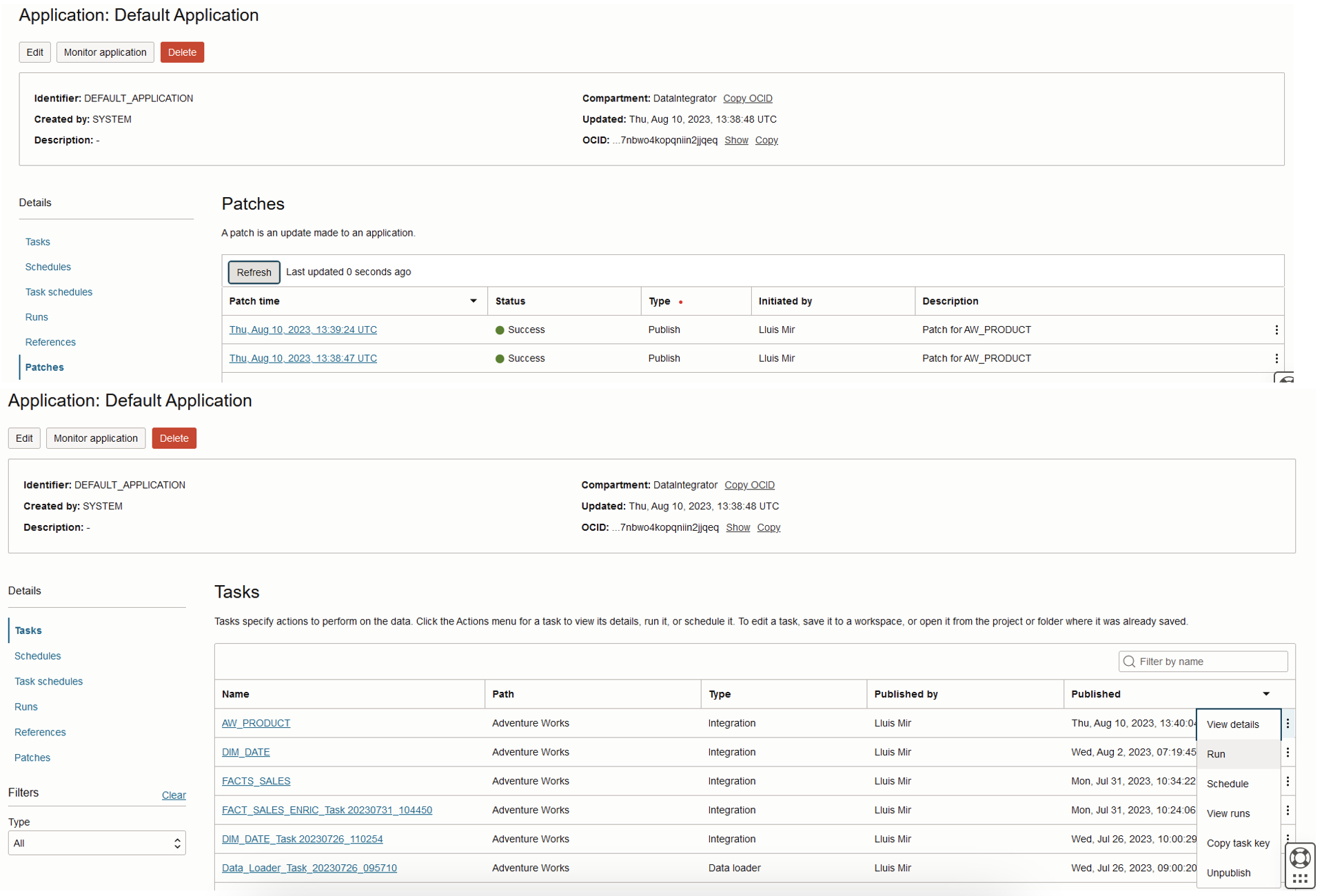
Task Creation and Execution
In your project, navigate to Tasks and initiate a new integration task to house your validated data flow. Once validated, save, exit, and publish to the application, then click on View application and the Patches list:

After the patch execution successfully completes, move to the Tasks screen and run the task. If it is successful, all the rows will integrate into the table; if not, address any issues:
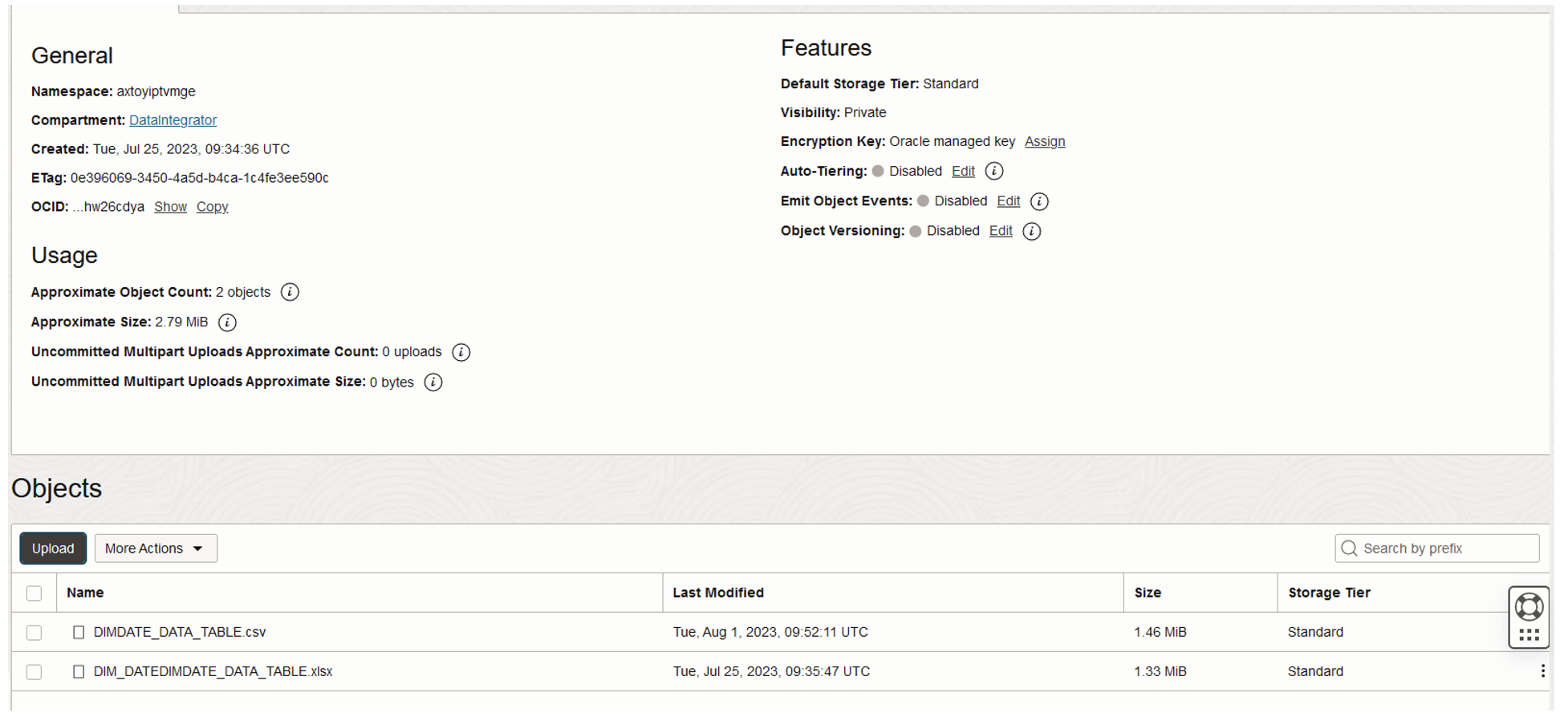
Object Storage
Object Storage is ideal for storing large amounts of unstructured data. It is a cloud storage solution that is scalable, secure, and can be used to store data that will not be stored directly in the DWH but is needed for subsequent analysis processes.
To load data from Object Storage, use object storage as a separate component. Within this component, search for the term “buckets” and create one. Inside the bucket, you can add items. The most efficient format is a .CSV file:
Oracle Analytics Cloud
Introduction
After successfully processing the tables via the data flow and subsequently loading them into the data warehouse database, the next critical step is to set up Oracle Analytics to analyse the data from various dimensions. Now we’ll guide you through setting up Oracle Analytics Cloud and designing the semantic model.
Setting Up Oracle Analytics Cloud
- Navigate to Oracle Analytics Cloud.
- Click on Create a new instance of analytics.
- After creation, open the provided Access Link.
Designing the Semantic Model
A semantic model forms the core of data representation and is broadly categorised into three layers:
Physical Layer
Purpose: To establish direct connections to data sources.
Key Activities:
- Import tables, views, and other data elements directly from the source.
- Preserve the original structure of the data source.
- Establish relationships between datasets.
- Optimise performance by using techniques like indexing.
- Create aliases for each table.
- Join tables with the fact table (keep the fact table on the left), to get a star design for the data lake.
Logical Layer
Purpose: To transform and model data as per business requirements.
Key Activities:
- Create derived measures.
- Establish hierarchies and define segmentations.
- Translate technical structures into business-oriented representations.
- Join tables without using aliases (contrary to the physical layer).
- Introduce new variables and establish different types of aggregations in the fact table for detailed graph analysis later.
Presentation Layer
Purpose: To interact directly with end-users and present data in an intuitive manner.
Key Activities:
- Organise and rename information for easy comprehension.
- Group fields into thematic folders.
- Set specific formats for intuitive data presentation.
- Design how users will view and access data in reports and dashboards.
Post-Configuration Steps
Model Testing
After configuring the three layers, it’s vital to:
- Review the semantic model.
- Execute detailed tests.
- Deploy the model in various scenarios.
- Ensure that the model aligns with business expectations and requirements.
Creating Reports
Now that the semantic model is ready, users can design reports, charts and dashboards in Oracle Analytics Cloud, efficiently leveraging the robust structure provided by the model.
Workbook Creation
Finally, create a workbook in Oracle Analytics. This will enable the creation and analysis of charts derived from data values within your data lakehouse:
Data Catalog
Introduction
The Data Catalog in Oracle Cloud is a pivotal data governance tool, acting as a gateway to your data assets. It simplifies access to data sources and strengthens data governance by improving the discoverability of data using various metadata enhancement tools.
Loading Data Assets
Before you can use the Data Catalog fully, you must load your data assets, including databases, object storage, and more.
For each asset, make sure that you incorporate all relevant data entities. However, unnecessary entities can be excluded from the Catalog for clarity.
Enhancing Metadata
Once the data has been loaded, you can refine its description and categorisation using three main tools, which you can then add to each element of the data asset.
Tags
Tags in OCI’s Data Catalog are like sticky notes for your data! They help you to identify and organise your data quickly by adding keywords or short descriptions, making it easy to spot and categorise information.
Features:
- Assign multiple keywords to any Catalog element.
- Frequency-based representation on a tag map where commonly used tags appear larger.

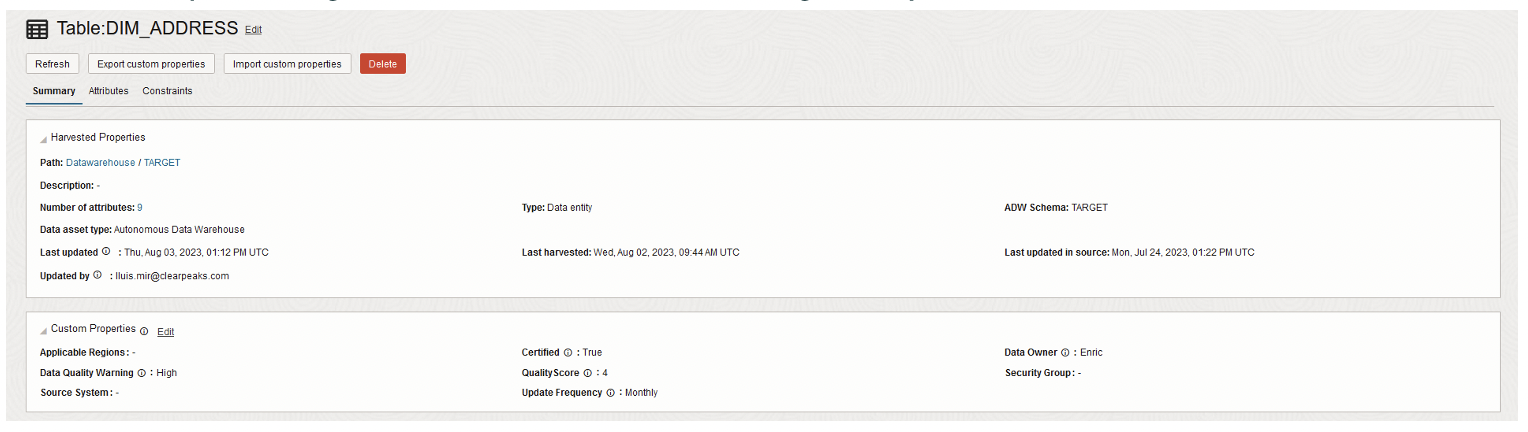
Custom Properties
Custom properties in OCI’s Data Catalog are personalised labels that you can add to your data, allowing you to give extra descriptions or categories to your data beyond the basic details. Think of them as special tags to better understand and organise your data:
Glossary
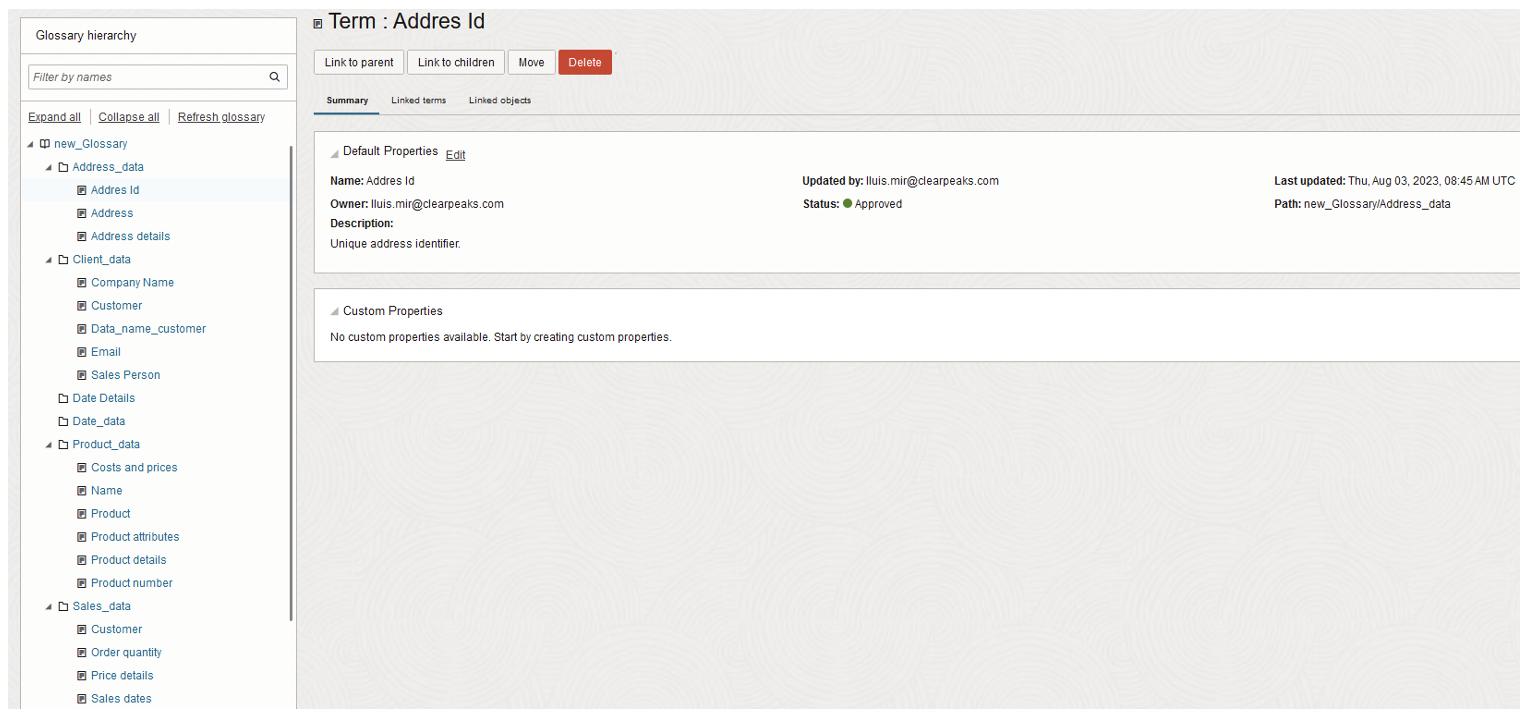
A glossary in the OCI Data Catalog is like a dictionary for your data terms, defining and organising important data-related words, ensuring that everyone speaks the same ‘data language’ within your organisation:
Features:
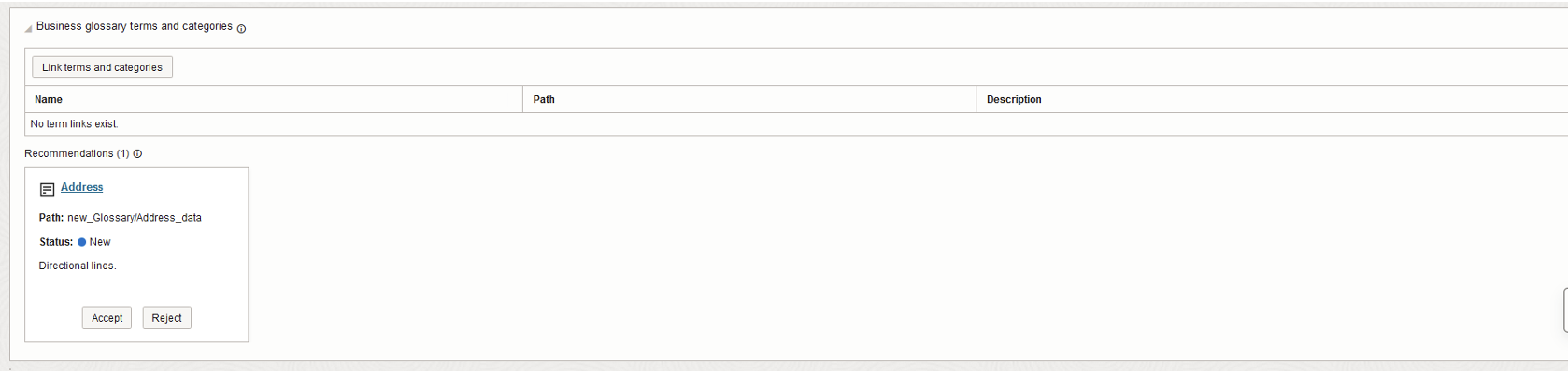
- Define and store specific terminologies.
- Associate glossary terms with Catalog objects for better context.
Data Discovery
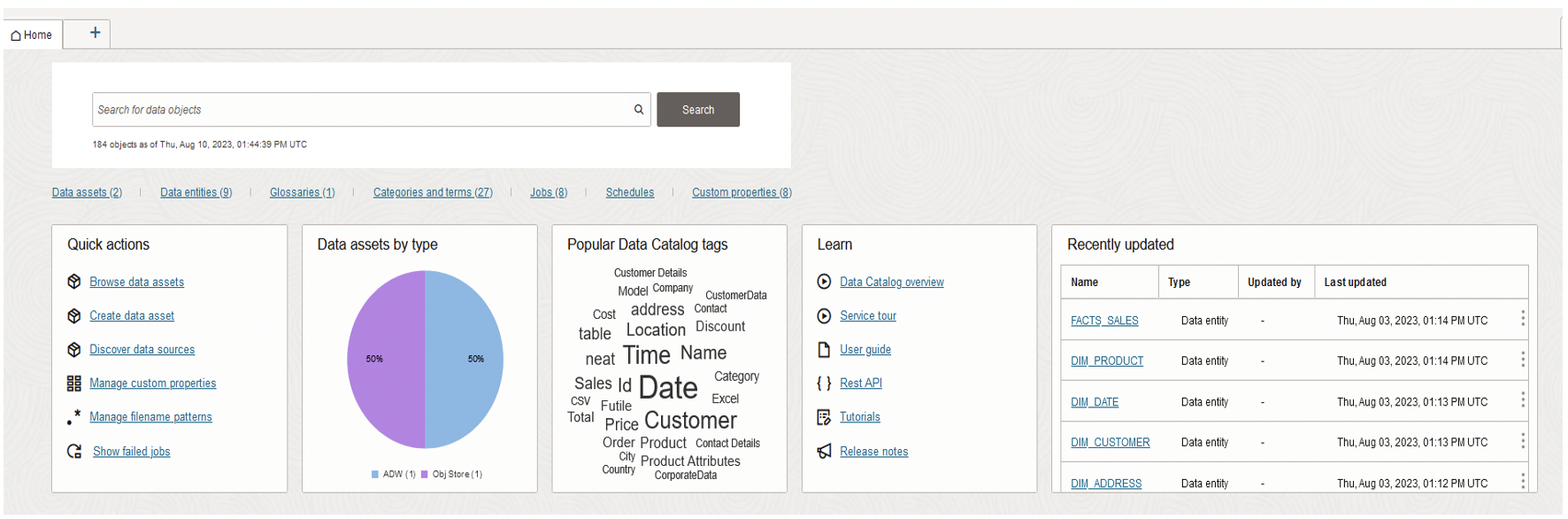
With enhanced metadata, the Data Catalog becomes a powerful method to search accurately for data. Users can leverage the above-mentioned tools to narrow down their search criteria, ensuring that they locate the most relevant data in the most efficient way:
Data Science
Introduction
Data Science in OCI harnesses cutting-edge tools and services to extract valuable insights from data. By combining advanced analytics, machine learning and collaborative environments, OCI empowers data scientists to explore, model, and predict outcomes with efficiency. From creating user groups to deploying models, OCI offers a comprehensive platform that streamlines data-driven decision-making, promotes collaboration and ensures security, making it an ideal environment for modern data science tasks.
Creating a Data Scientists User Group
- Create a user group called «data-scientists» under Identity & Security > Groups.
- Now simply add users to this group.
Creating a Compartment for Your Work
- Create a compartment named «data-science-work» under Identity & Security > Compartments.
- This compartment will organise data science resources.
Creating Policies:
- Set up Data Science policies under Identity & Security > Policies.
- Create policies to allow Data Science users the access they need to various resources in the «data-science-work» compartment:
allow service datascience to use virtual-network-family in compartment data-science-work allow group data-scientists to manage data-science-family in compartment data-science-work allow group data-scientists to use virtual-network-family in compartment data-science-work allow group data-scientists to manage buckets in compartment data-science-work allow group data-scientists to manage buckets in compartment data-science-work
Creating a Dynamic Group with Policies
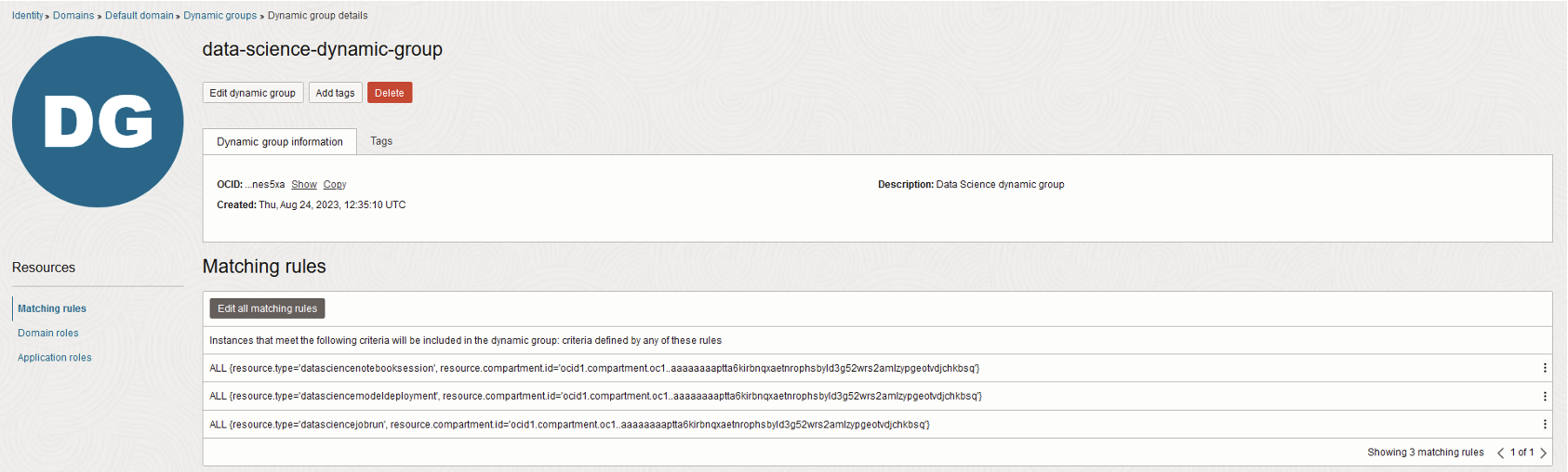
- Establish a dynamic group called «data-science-dynamic-group» under Identity & Security > Dynamic Groups:
- Define matching rules for including resources like notebook sessions, model deployments, and job runs within this dynamic group. Replace <compartment-ocid> with the data-science-work compartment OCID:
ALL {resource.type='datasciencenotebooksession',
resource.compartment.id='<compartment-ocid>'}
ALL {resource.type='datasciencemodeldeployment',
resource.compartment.id='<compartment-ocid>'}
ALL {resource.type='datasciencejobrun',
resource.compartment.id='<compartment-ocid>'}
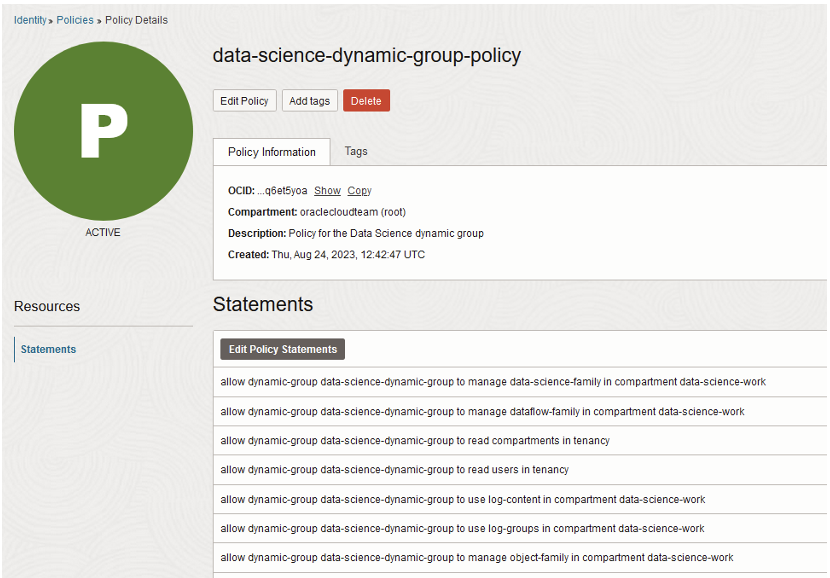
After setting up the dynamic group, the next step is to establish policies that grant the dynamic group access to other OCI services:
1. Open the navigation menu and click on Identity.
2. Select Policies.
3. Click on Create Policy.
4. Enter the following details:
– Name: data-science-dynamic-group-policy
– Description: Policy for the Data Science dynamic group
5. Instead of specifying the «data-science-work» compartment, choose the highest-level compartment which corresponds to your tenancy (root). This will allow broader access to resources within your OCI environment:
allow dynamic-group data-science-dynamic-group to manage data-science-family in compartment data-science-work allow dynamic-group data-science-dynamic-group to manage dataflow-family in compartment data-science-work allow dynamic-group data-science-dynamic-group to read compartments in tenancy allow dynamic-group data-science-dynamic-group to read users in tenancy allow dynamic-group data-science-dynamic-group to use log-content in compartment data-science-work allow dynamic-group data-science-dynamic-group to use log-groups in compartment data-science-work allow dynamic-group data-science-dynamic-group to manage object-family in compartment data-science-work
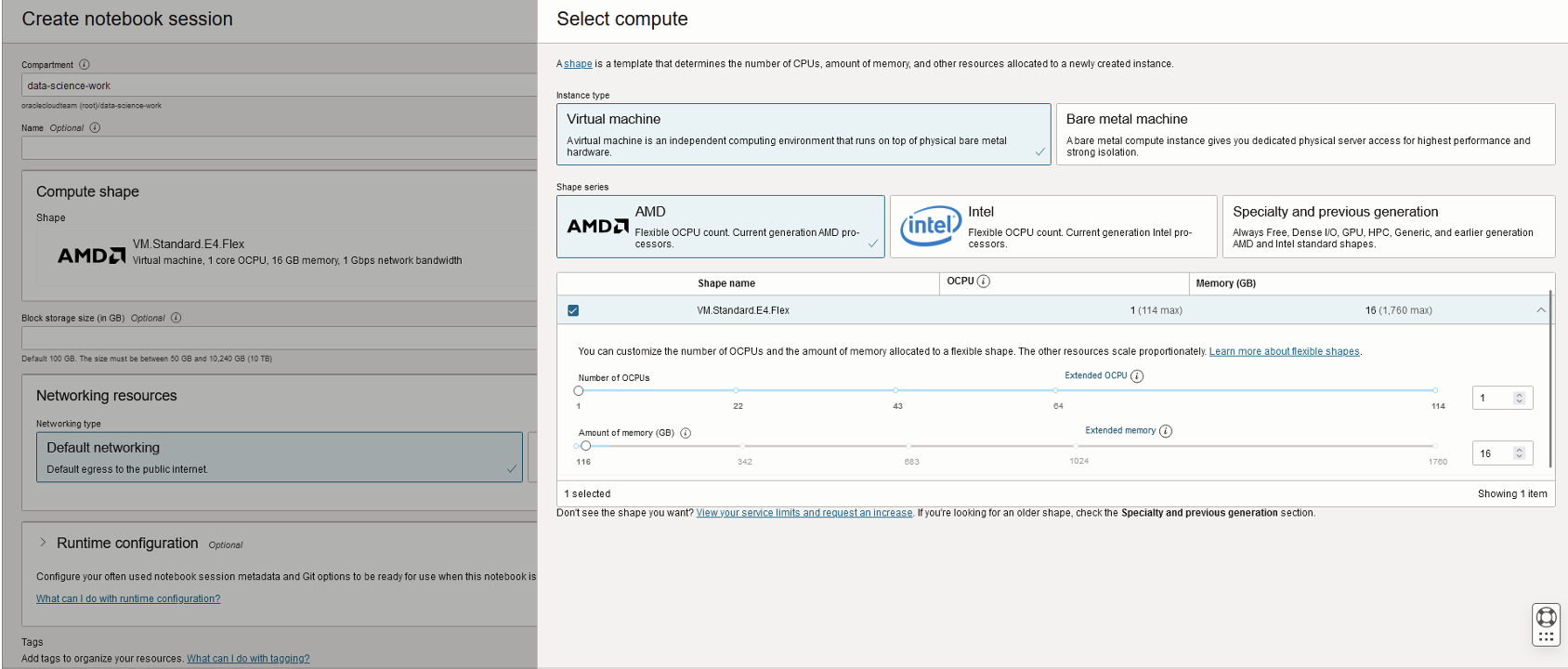
Creating a Notebook Session
- Open Analytics & AI > Data Science to create a project in the «data-science-work» compartment.
- Launch a notebook session within the project, using these options:
1. Instance Type: Virtual machine
2. Shape Series: Intel
3. Shape Name: VM.Standard3.Flex
For VM.Standard3.Flex, keep the default allocations:
- Number of OCPUs: 1
- Amount of memory (GB): 16
Accessing Object Storage and Executing Python Scripts
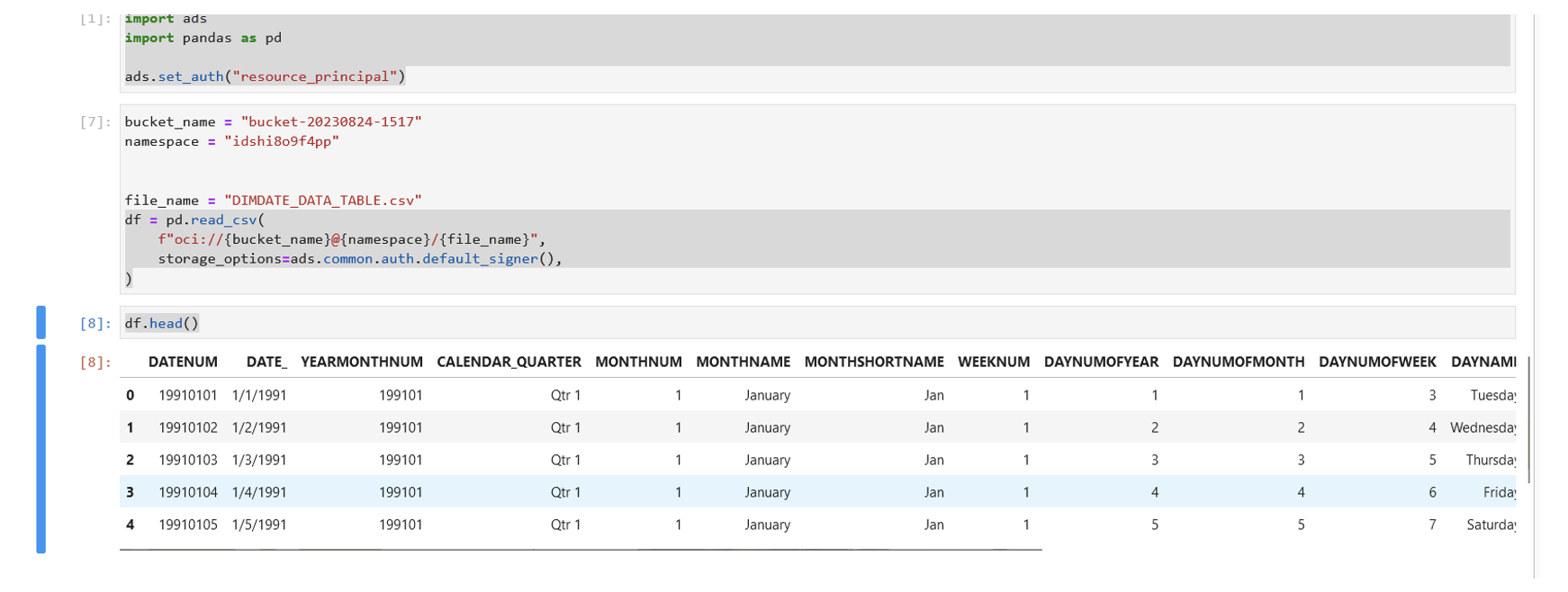
In order to access an object storage, we must provide the necessary information such as the name of the bucket, namespace, and the name of the document. After that, we have to execute the code correctly together with the necessary libraries to be able to visualise the bucket’s content:
Conclusions
Our Data Lakehouse Project aimed to merge the strengths of data lakes and data warehouses by transforming the complex AdventureWorks database into a streamlined star schema using the Oracle platform. By leveraging tools like the OCI Autonomous Data Warehouse for data storage, Oracle Data Integrator for ETL processes, and Oracle Analytics Cloud for data analysis and reporting, we were able to establish a simplified querying and reporting structure. Oracle Cloud Object Storage supported the storage of voluminous unstructured data, whilst the Data Catalog was fundamental for data governance, enhancing metadata with features such as tags, custom properties, and glossaries. The resulting architecture provides a comprehensive, efficient, and user-friendly approach to data analytics in the Oracle platform.
Do you have questions about how our Oracle Data Lakehouse Project can benefit your organisation? Are you interested in exploring how the synergy of data lakes and warehouses can revolutionise your own data management and analysis? Our team of experts is ready to help, so do get in touch with us here at ClearPeaks to discuss how we can tailor our approach to meet your specific needs.
