
03 Ene 2024 Natural Language Processing (NLP) in Dataiku – Part 2: Document-based Q&A Using LangChain
This is the second part of our “NLP in Dataiku” series, where we are exploring how the Dataiku AI platform can help your organisation to tackle end-to-end NLP use cases. In the first blog post of this series, we saw how easy it is to create a Dataiku application for keyword extraction and text summarisation from provided texts. Today we will focus on a more intricate use case increasingly adopted by organisations – Question-Answering over Documents (QAD), something we are already working on with some of our clients.
Question-Answering Over Documents (QAD)
QAD is a cutting-edge task that aims to bridge the gap between human understanding and machine comprehension. It involves developing algorithms and models capable of reading and comprehending textual documents, and then accurately answering questions posed in natural language based on the information contained within those documents.
There are various applications across numerous areas, like information retrieval, search engines, virtual assistants, customer support systems, and educational platforms. By enabling machines to understand and respond to human queries in context, QAD is revolutionising the way we interact with information in the digital age.
QAD uses two main approaches:
- Abstractive Q&A: This involves generating a new answer in natural language, not necessarily present in the original documents. Instead of copying text verbatim, the system interprets the documents, understands the context, and then generates a succinct, coherent answer to the question posed.
- Extractive Q&A: The system identifies specific segments of text that contain the answer to the question. In other words, it selects the relevant part of the document that answers the question without generating any new text, and returns it as the answer.
In today’s use case, we aim to harness the extractive approach’s potential using LangChain, a framework designed for developing applications powered by Large Language Models (LLMs). It provides a standard interface for interacting not only with LLM providers, but also with many open-source models that can be run locally. This is important as there are organisations that do not want to send potentially sensitive information to a third party, but prefer to run LLMs on premise, so that the data never leaves the site, thereby reducing potential risks.
Dataiku Application
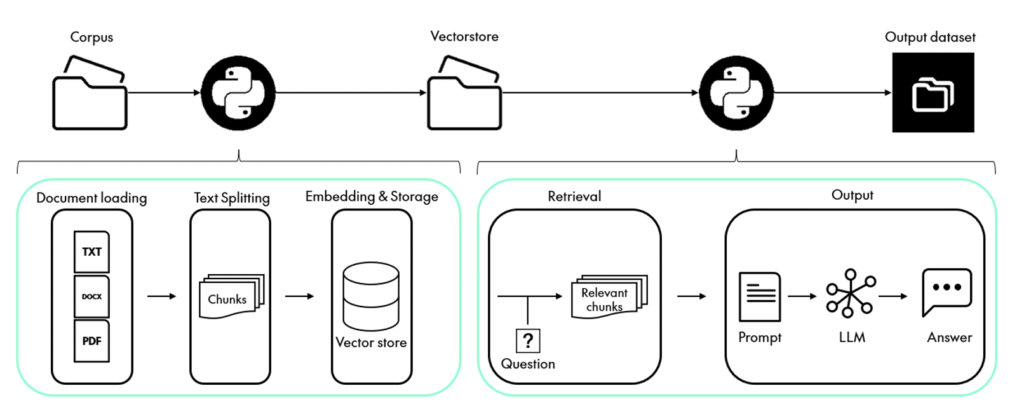
As in our previous blog post, we have created a Dataiku project for this QAD use case and, from it, a Dataiku application so that the developed functionality can be accessed via a simple user interface (UI). This application has two scenarios (in Dataiku, a scenario means a sequence of interconnected steps). In our case, each scenario has a single step to execute a Python recipe, but as we will see later, each step executes several tasks.
Below you can see the simple UI for users to interact with the application (via, as mentioned in the first blog post, an application instance, and assuming that the user has the proper permissions):
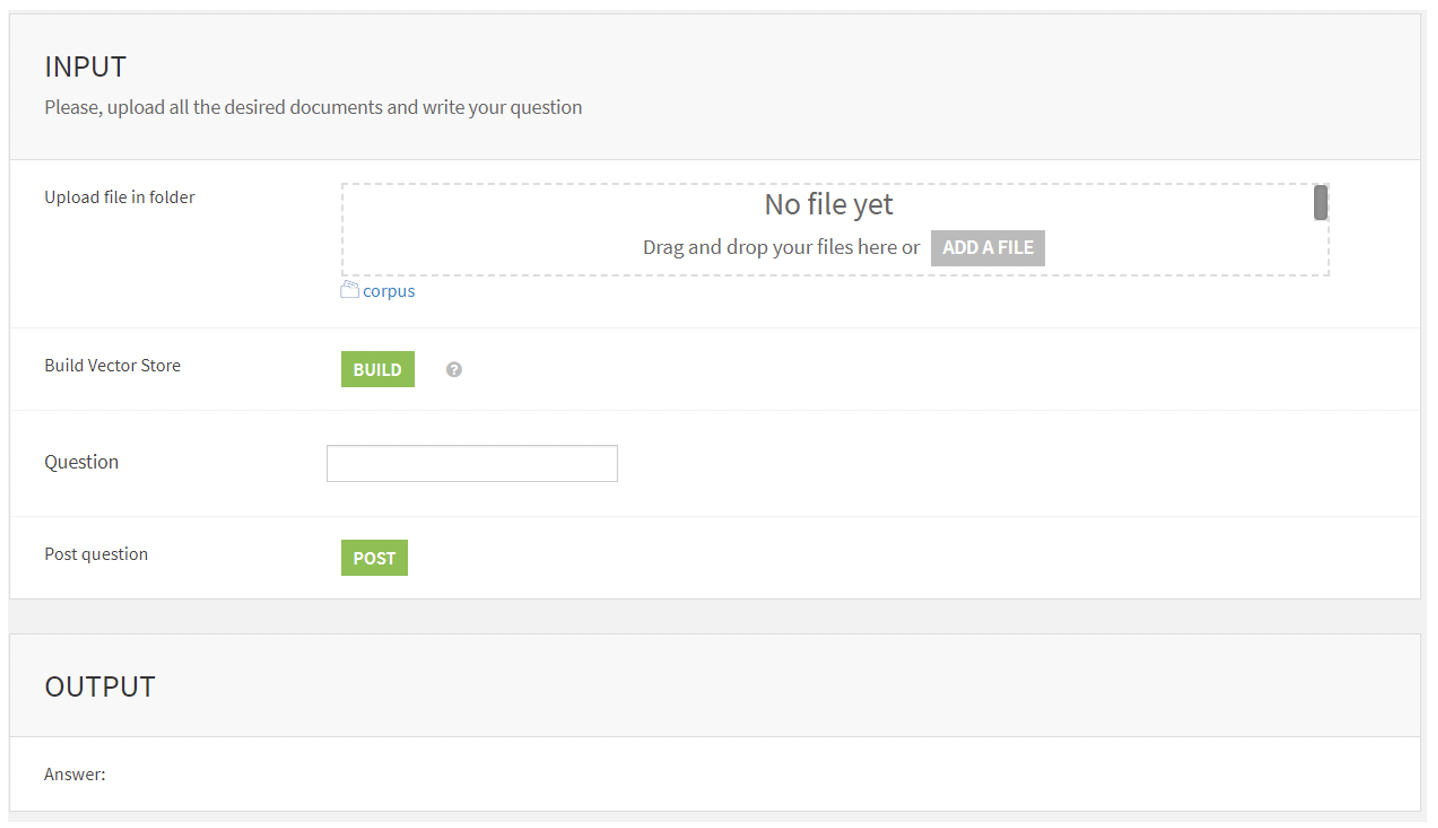
The app consists of tiles used to build the UI displayed to the users:
- Upload file in folder: Users browse and select files to use as the context for the LLM; these files are stored in the corpus
- Build Vector Store: This runs the first Dataiku Data Science Studio (DSS) scenario that loads the documents and creates then saves the vector store. You only need to create the vector store when a document is uploaded or removed from the corpus.
- Question: This saves the prompted question as a project variable, to be used as input for the model.
- Post: This runs the second DSS scenario to retrieve the answer.
- Answer: The answer is displayed.
Below there’s an example of how the application can be used. The corpus consists of different documents containing information about AI topics extracted from Wikipedia:
Now let’s delve into the tasks that are carried out in both scenarios.
First Scenario: Load the Documents and Create the Vector Store
Load
First, we need to load the data. The LangChain Document Loader module retrieves the unstructured data from the files (.docx, .pdf, .txt, etc.) in the corpus directory and creates the Documents. A Document is a piece of text (the page content) and the associated metadata.
Split
Now the Document is split into chunks for embedding and vector storage; the size of the chunks and the overlap is set in the Python recipe.
Store
In order to access our chunks later, we need to store them in a retrievable location. The typical approach involves embedding the contents of each document and then storing both the embedding and the document in a vector store. Embeddings are numerical representations of words, sentences, or documents in a continuous vector space. They are fundamental in converting textual data into a format that machine learning models can understand and process. For our use case, we used the open-source GPT4AllEmbeddings.
Vector stores are data structures or storage systems that hold precomputed document embeddings, designed to efficiently retrieve vector representations of words, sentences, or documents based on their input queries. The vector store used in this example is , which can be saved locally in the vectorstore directory.
Second Scenario: Answering the Posted Question
RetrivalQAChain
The RetrievalQAChain is a chain that combines a Retriever (the vector store in our case) and a QA chain. It is used to retrieve documents from the Retriever and to then employ a QA chain to answer a question based on the retrieved documents.
The different steps in a QA chain are:
- Question processing: The user’s question is tokenised, pre-processed, and encoded into a format suitable for feeding into the LLM.
- Document Retrieval and Ranking: The vector store is queried using the encoded question to retrieve a set of relevant documents. The documents are ranked based on their similarity to the query vector, with the most relevant documents appearing at the top of the ranking.
- Answer Extraction: The top-ranked documents are passed as context to the LLM, which then generates a response in natural language, effectively the answer to the question.
Once the answer has been retrieved, it is saved as a project variable for later visualisation in the UI, and the output dataset is updated with the new question-answer pair.
LLM Used
This article proposes two different approaches to explore the capabilities of LLMs in QAD tasks: firstly, utilising remote models through APIs (the approach used in the demo video), and secondly, employing local LLMs. While the first option offers faster results, it may also raise concerns about privacy issues as mentioned before. The remote model we used is provided by Cohere, whilst the local model was the open-source Vicuna 13b.
Prompt
The prompt is crucial when using LLMs because it serves as the input or initial context that guides the model’s generation. It provides context and instructions to the model, shaping the output it produces.
In our application, we used the following prompt:
“Use the following pieces of context to answer the question at the end. If you don’t know the answer, just say that you don’t know, don’t try to make up an answer. Keep the answer as concise as possible.
Context: {context}
Question: {question}
Answer:”
Conclusions
This blog post is the second in our series exploring NLP within Dataiku. Dataiku’s emphasis on user-friendly interfaces, pre-built components, and integration with machine learning frameworks, makes it an intuitive platform for developing visual applications that can empower users to derive meaningful insights and make data-driven decisions effectively. What’s more, it can take NLP applications to the next level!
LangChain provides an intuitive interface to harness the full potential of LLMs, so the combination of LangChain with Dataiku is a recipe for success when tackling NLP use cases like the QAD application we have seen today.
All in all, the future for QAD applications looks promising, as ongoing improvements to language models and advances in data processing will further enhance their capabilities and solidify their position as a key tool in the field of natural language understanding.
If you want to see how advanced analytics and LLMs can help your organisation to become more productive and leverage the full value of your data, do not hesitate to contact us and our team of experts will be happy to help you!
