
01 Feb 2022 Choosing your Data Warehouse on Azure: Synapse Dedicated SQL Pool vs Synapse Serverless SQL Pool vs Azure SQL Database (Part 1)
This is the first part of a two-blog series where we will discuss Azure Synapse Analytics, a relatively recent analytics service in the Microsoft platform. We have already talked about other analytics services in Azure in our previous blog post “Cloud Analytics on Azure: Databricks vs HDInsight vs Data Lake Analytics”, but the addition of Synapse to the Azure portfolio has changed the data analytics landscape significantly. Synapse is growing in popularity, hardly surprising when you consider that Azure is positioning it as its flagship for Data Analytics.
In this series, we will introduce Synapse and, for those who have never seen it in action, we will demonstrate how to use it: first, we will query data in a data lake using external tables via a serverless SQL pool and a dedicated SQL pool; second, we will load the data into internal tables inside Synapse internal storage using a dedicated SQL pool and we will query it too; finally, we will also load the data into an Azure SQL database and we will compare its querying capabilities with the Synapse dedicated SQL pool, thus determining how Synapse compares to Azure SQL database, and in what situations each is better in terms of both cost and performance.
In this first blog post, we are going to introduce Azure Synapse Analytics and its capabilities, and show you how to configure a Synapse workspace. We are also going to take a look at the Azure SQL family and explain how to configure the Azure SQL database instance that we will use to compare with the Synapse dedicated SQL pool. In the second part of the series, we will present the results we obtained from the comparison and the conclusions of our work.
The data we will use for our demonstration is from the well-known TPC-H benchmark dataset. For the test in which we use the serverless SQL pool to query the data lake, we actually use three different versions of it: the first, CSV files, the second, Parquet files without partitioning, and the third, Parquet files with the biggest tables partitioned.
We will do a similar test with a dedicated SQL pool, but in this case, we will only use the second and third versions of the dataset, since creating external tables for CSV files is not supported in this kind of pool. Note that this TPC-H dataset is the same dataset as described in our blog “Optimising Data Lakes with Parquet”, where more specific information can be found, as well as how it was generated. Please note that we have written a blog series called Data Lake Querying in AWS, comprising of 6 blog posts where we use the same dataset with different data lake querying technologies on top of AWS.
Now, before we continue, let’s take a closer look at Azure Synapse Analytics.
Introducing Synapse
As we said before, Azure Synapse Analytics is a limitless analytics service that aims to offer an all-in-one solution for data analysis. Azure has merged all the existing necessary services (from the ingestion of data to its visualisation, through its management, processing, and predictions using machine learning) under a unified platform that simplifies their use.
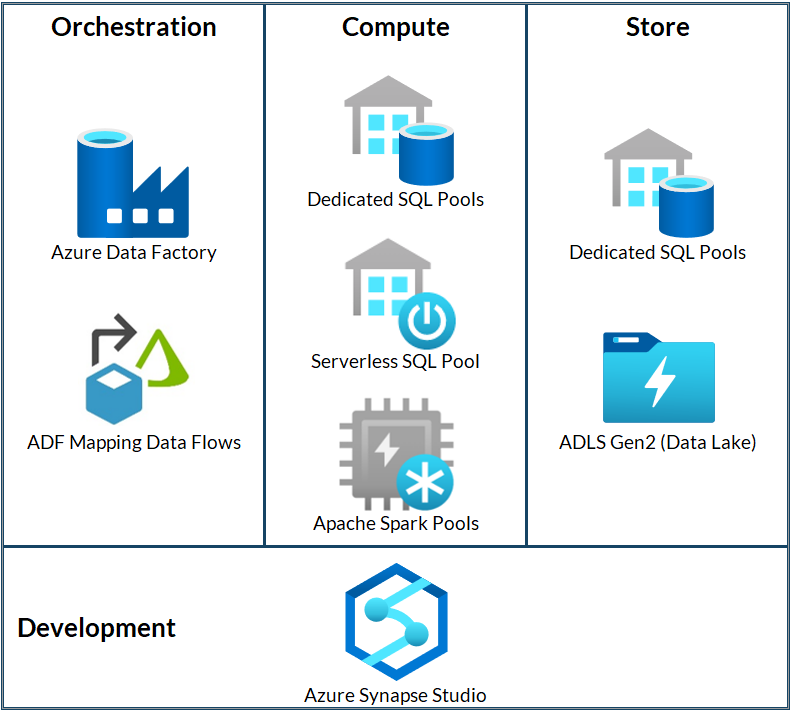
Figure 1: Map of Azure Synapse Analytics components
Azure Synapse Studio & Azure Synapse Workspace
As we can see in the previous map, all the development can be performed through Azure Synapse Studio, a user-friendly web UI that allows us to access and leverage all our resources in Synapse.
Our firsts steps with Synapse will be to create a workspace. An Azure Synapse workspace is the personal cloud platform where each user will have access to their resources, deployed in a specific region with an associated Azure Data Lake Storage Gen2 account. For the data lake, we can choose whether to use an already existing one or to create a new one just for Synapse.
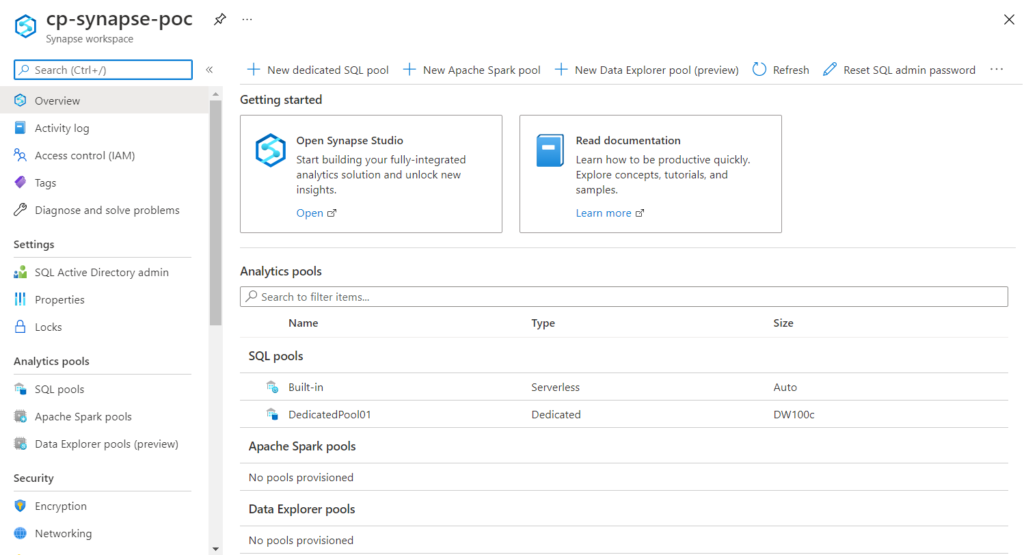
Figure 2: Azure Synapse workspace
As we can see in the image above, the workspace is classified as a resource inside Azure, and from the Azure Portal we can open the Studio, as well as see the pools linked to this workspace (more on pools later).
Inside Synapse Studio we will find different tabs for each of its functionalities, and a Home page that is very useful for beginners, as it offers documentation as well as a lot of guides and community posts to help the user get to grips with common operations.
Accessing Data
The first logical step for someone starting out with Azure Synapse Analytics would be to access the data they want to query. If it is already in the Azure Data Lake Storage Gen2 that was used to create the Synapse workspace, we will find it inside the Data tab in Azure Synapse Studio, as we can see in the next image:
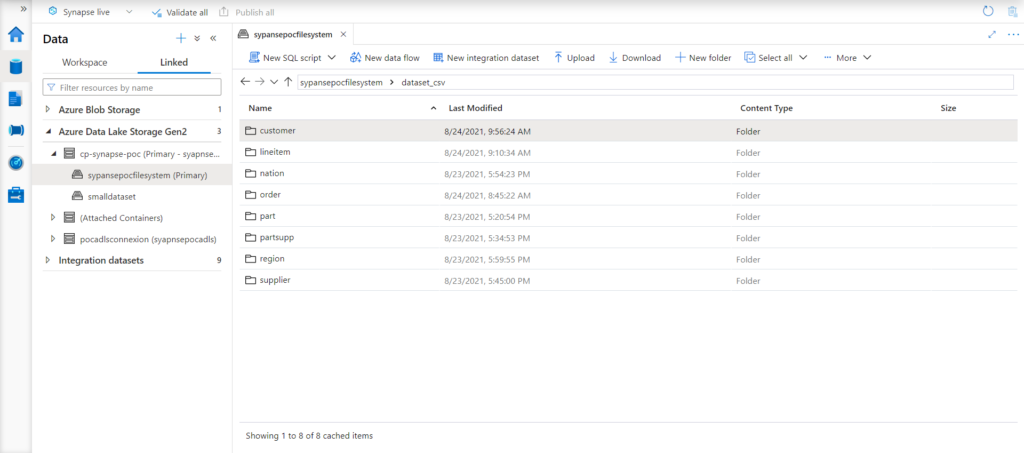
Figure 3: Azure Synapse Studio: Data tab
If the data is located inside a different Azure Data Lake Storage Gen2 or an Azure Blob, we can connect it to Synapse and access it through the same Linked tab in Synapse Studio. In the previous image we can also see a section for workspace data. This is where we will access the data stored inside Synapse, like the data loaded into the dedicated SQL pool, or the external tables for the serverless SQL pool, which we will get back to later.
To sum up, this Data tab will perform the role of the Synapse data warehouse, so we do not need to open the data lake service in Azure Portal in order to access the data; it is built into the same workspace where development takes place.
Integrating and Transforming Data
If our data is not located in Azure, we will need to copy it to one of the Synapse linked services in order to analyse it. We will use pipelines, which can be built and run in the Integrate tab, to move the data (and for any ETL process in general).
A pipeline is a logical grouping of activities that together perform a task; it is a cloud-based ETL and data integration service that allows you to create data-driven workflows to orchestrate data movement and transformation at scale. Azure Synapse contains the same data integration engine and experiences as Azure Data Factory, allowing us to access the same functionalities (ingestion from 90+ data sources, code-free ETL with data flow activities, etc.) without leaving Azure Synapse Analytics. For more information, we have already written several blog posts mentioning Azure Data Factory, like “Is Azure Data Factory ready to take over SQL Server Integration Services?”, where its capabilities are explained.
Analysing Data
Finally, now that our data is properly located and ready, we can analyse it and extract useful information.
The analysis in the Synapse workspace can be performed with SQL pools or Apache Spark Pools. In this blog we are going to focus on SQL pools, but remember that Spark pools are also a powerful tool thanks to their ability to process in-memory, plus the added support for Spark ML in addition to Azure’s own.
There are two types of SQL pool, depending on the consumption model: dedicated or serverless. There can be any number of dedicated SQL pools, where the resources are fixed and controlled by the user. On the other hand, there will only be one serverless SQL pool per account, in the workspace, that automatically scales depending on the workload, without any fixed resources linked to it.
To access the data from linked services such as Azure Data Lake Storage Gen2, we will need to create external tables in our Synapse workspace, which (as we saw previously) are to be found in the Data tab. However, when working with SQL dedicated pools we can also store the data in internal tables, which are easily accessed with Synapse pipelines.
When storing the data internally in a dedicated SQL pool, the data is technically still located in Azure Storage (providing Azure management and security), but the main advantage when compared with external tables is the storing of the data in relational data structures, improving query performance while significantly reducing storage costs; storage is charged independently from the compute power.
A dedicated SQL pool stores a table as a clustered columnstore index by default (other types of indexes/clustering are also supported). This form of data storage achieves high data compression and great query performance on large tables; on top of that, partitioning is supported too for further optimisations.
For the querying process itself, we will use the Develop tab, where all the scripts, notebooks, and data flows within the workspace will be stored. Like in Azure Data Studio, a programme designed with querying in mind, from the Develop tab we can create and manage queries and Jupyter-like notebooks and execute them by connecting to data warehouses or pools.
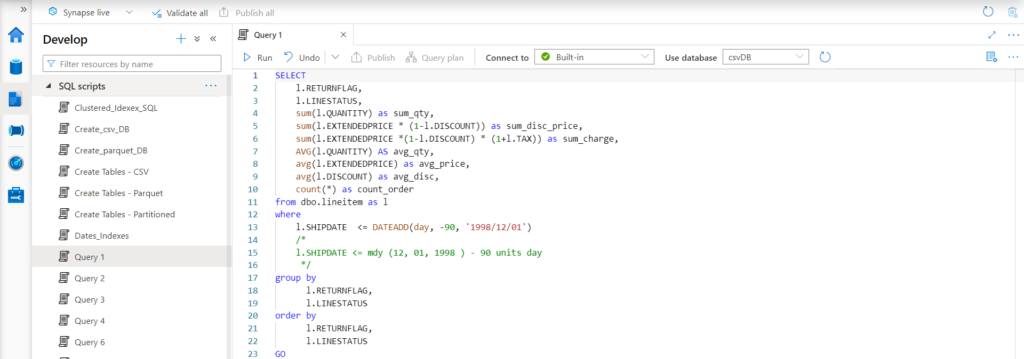
Figure 4: Azure Synapse Studio: Develop tab
At the top of the image, we can see how the editor shows the resource to which the query is connected. In this example, it is connected to Built-in, the default serverless SQL pool that comes with the Synapse workspace; note that this connection can be chosen by the user.
Additionally, Synapse also benefits from being an independent service, as it allows an additional layer of security, independent from Azure. Specifically, it works with an independent hierarchy and requires additional permissions to access its content, as well as allowing an extra encryption layer.
Before jumping forward to the hands-on example of how we used Synapse to query the TPC-H dataset, we are going to run through the steps we followed to create and configure the Azure Synapse workspace.
Configuring Synapse
We created and deployed the Azure Synapse workspace using Azure Portal. Once in the Create Synapse Workspace menu, we have to define some fields, some of which are common to all Azure resources: Subscription, Resource group, Workspace name, Region, or Tags. However, there are also some points characteristic of Azure Synapse that must be considered.
First, a Data Lake Storage Gen2 account is required. We can choose whether to create a new account or to use an existing one. This resource is used as the primary storage account for the workspace, and it holds the data and metadata associated with it.
Besides the storage account, the Synapse workspace needs an SQL server to manage the workspace SQL pools. This SQL server is automatically created when creating the Azure Synapse workspace, and the user only provides an SQL server admin login and an SQL password.
When creating the workspace, we can also set an additional encryption layer. By default, Azure encrypts the data at rest across all resources, but this second layer would be exclusive to Azure Synapse Analytics.
Serverless SQL Pool
An Azure Synapse workspace has a built-in serverless SQL pool, which acts as a query service over the data in a data lake; it needs no extra configuration to access data. Since it is serverless, there is no infrastructure to set up or to maintain. Scaling is done automatically to fit the resource requirements process, and the user only pays for the total amount of data processed, without charges for reserved resources.
Additionally, to optimise query executions, the serverless SQL pool creates statistics that are reused when, for example, we run a query twice or run two queries that have similar execution plans.
Thanks to these features, the serverless SQL pool gives us the capability to analyse large amounts of data in seconds, without the need to copy or load data into a specific store.
Dedicated SQL Pool
The Synapse dedicated SQL pool is the heir to Azure SQL data warehouse and includes all the features of enterprise data warehousing. Unlike the serverless SQL pool, there is no built-in dedicated pool, so its instances must be created and deleted by the user, and we can choose the resources it is provisioned with.
In Synapse dedicated SQL pools, these resources are measured in Data Warehousing Units – DWUs. A DWU is a bundle of CPU, memory, and IO resources. The number of DWUs determines the performance of the pool and the cost. Moreover, instead of being charged by query, by using a dedicated pool we will be charged for the time the pool has been active, regardless of the work it has done. Logically, dedicated pools can be paused and resumed to avoid unnecessary costs. For our test, we created a dedicated SQL pool of 100 DWUs.
Once the pool has been created, data can be loaded into it using the COPY statement, PolyBase with T-SQL queries, or a pipeline. This data will be stored in relational tables with columnar storage.
If we decide to use a pipeline for the data load, like Data Factory, Synapse has Copy Data, a copying tool that simplifies the process even more by asking the user what to do and building the pipeline in the background.
In terms of architecture, both the Synapse serverless and dedicated SQL pools are node-based and distribute computational data processing across multiple nodes. For detailed information about possible configurations of Azure Synapse, we highly recommend reading their documentation.
Introducing Azure SQL Database
Azure offers different shapes and forms for its SQL Server engine in the so-called Azure SQL family. The most popular shape/form, and the one we chose for our study, is probably Azure SQL Database, a fully managed platform as a service (PaaS) database engine that handles most database management functions in the Azure SQL family. For more information on the rest of the services in the Azure SQL family, check out the Microsoft documentation, and this page too, for a feature comparison of Azure SQL database vs Azure SQL managed instance.
Configuring Azure SQL Database
We created an Azure SQL database to compare it with a Synapse dedicated SQL pool; this resource was also created in the Azure portal. There are two service tiers for an Azure SQL database: the DTU-based purchasing model, where we can choose from different packages of both preconfigured compute and storage resources, or the vCore-based purchasing model, where we can choose compute and storage resources independently. More information about the service tiers for an Azure SQL database can be found on their website. If you choose the virtual cores model, the compute tier can be either dedicated, with the resources pre-allocated, or serverless, where the resources will adapt automatically to the workload.
We wanted to make a fair comparison of the Azure SQL database and the Synapse dedicated SQL pool. In an ideal scenario, with full control of the services, we would fix the amount of resources used by each. However, due to the options given at service creation and the service model of both, trying to fix the amount of resources is not possible; so what we did was to try to fix the cost (which is also rather challenging), and in particular, we tried to fix the monthly service costs. With this in mind, we created services with similar monthly costs to see which gives the best performance for our datasets and queries.
We found that for a Synapse dedicated SQL pool with 100 DWUs, the Azure SQL database that best suits our purpose is the General Purpose with serverless tier provisioned with 2 vCores and up to 390 GB of memory. Like a dedicated SQL pool, this service can be paused when it is not in use to save costs.
To determine if they have a similar monthly cost, we assumed both were online (not paused) for a whole month. Of course, the result of this comparison is limited to the used instances and used dataset and queries; it is not intended to be a full comparison – to do so we would need to test different sizings of the services, different workloads, different datasets, and different types of queries.
What’s Next?
In this blog post we have presented the new Azure flagship for data analytics, Synapse Analytics. We have seen its various components and how they can be easily accessed in the Synapse Studio. This first part of the Synapse series has focused on the configuration of its workspace, and, in particular, on the configuration of the two Synapse SQL pools we used: the serverless SQL pool and the dedicated SQL pool. We also discussed and chose an Azure SQL database that would be suitable for comparison with a Synapse dedicated SQL pool.
In our next blog post we will give you a hands-on example of how to use the two types of SQL pool in Synapse to query data from the TPC-H dataset, and we will also see how they compare with Azure SQL database.
For more information on how to use Synapse and how to exploit its functionalities, do not hesitate to get in touch with us! We will gladly assist and advise you in making the best business decision possible.
The blog series continues here.
