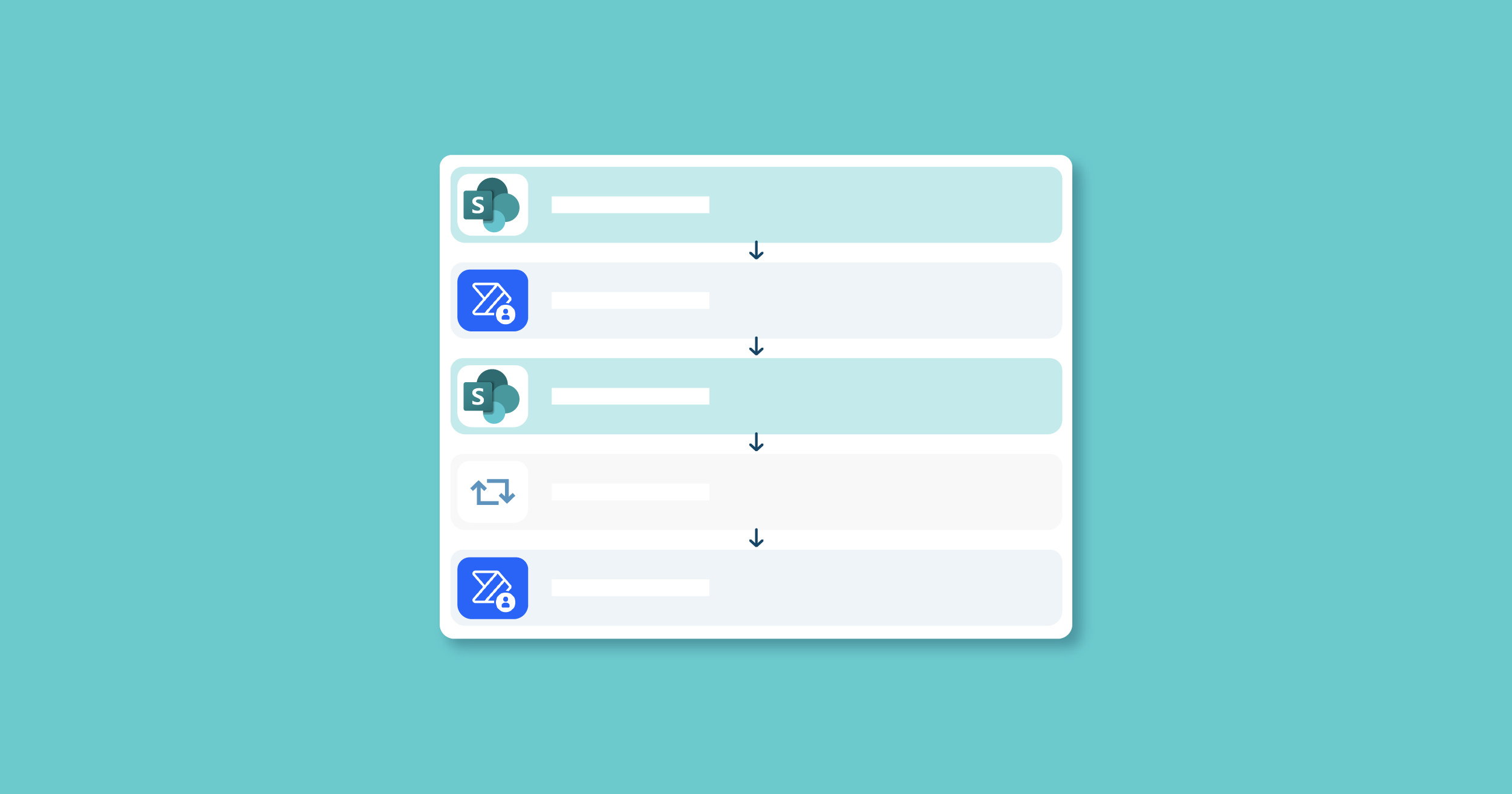
23 Feb 2023 Updating and Enhancing our Advanced SharePoint Indexer
Some time ago, we created the Advanced SharePoint Indexer, providing a more agile SharePoint browsing experience by using custom columns to tag files and folders, and by leveraging custom views to see these custom columns easily and to filter them on a small scale using the SharePoint web UI.
But we didn’t stop there – we also created an Azure Data Factory pipeline that runs an Azure Function on a daily basis to extract the metadata (including the values set for the custom columns) from all the files and folders of interest, using Python and the SharePoint API, then dumps the information in a set of CSVs. These CSVs feed a Power BI report that enables a more complete search of SharePoint using the custom tags created.
Here in ClearPeaks we call it InnoHub, and use it as a browser for all our CoolThings (cool stuff we do in our projects) and Customer Success Stories, which we store in our SharePoint library. The Power BI frontend allows for a faster and easier search of the library, simplifying our job from a sales and management point of view.
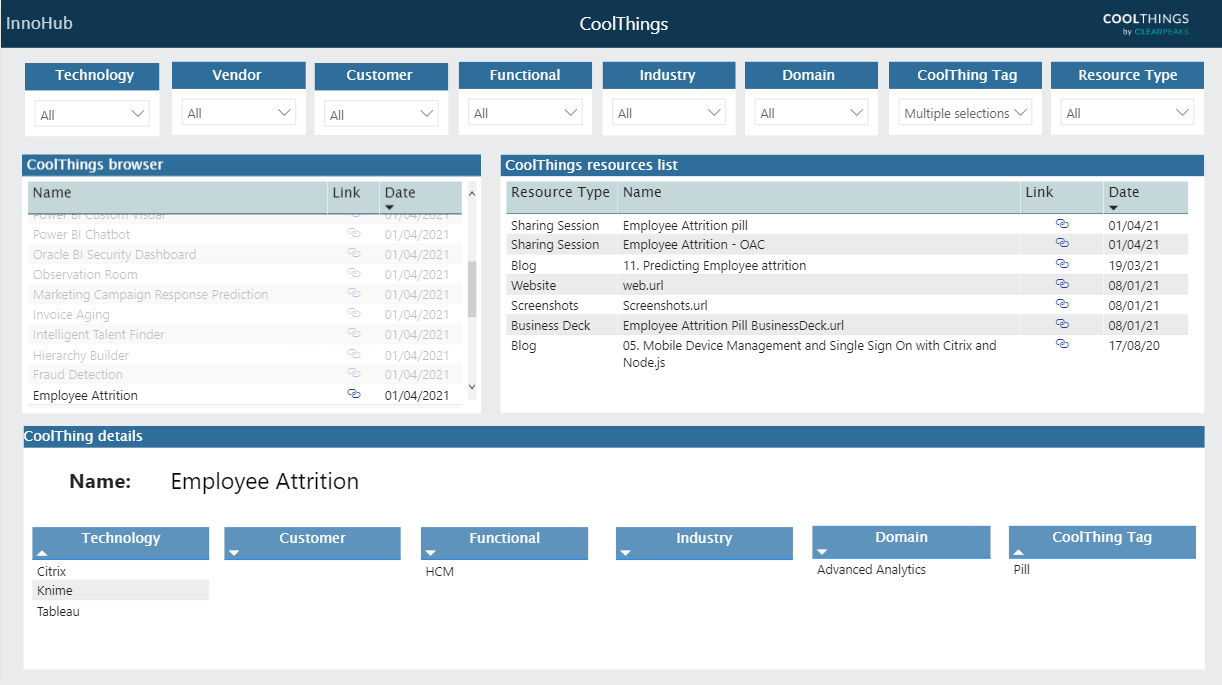
Figure 1: InnoHub – An Advanced SharePoint Indexer
We have been using the version of this SharePoint indexing tool described above in our company for some time now, but recent versions of Power Automate from Microsoft Power Platform have introduced better compatibility with SharePoint, so now we can use it to take care of metadata extraction from SharePoint. This means that we no longer need Azure Data Factory and Azure Function, thus making our solution simpler (no need for custom Python code to call the SharePoint API).
In this article, we’ll have a detailed look at how we updated our Advanced SharePoint Indexer to make it simpler, whilst also allowing for greater scalability; but first, let’s take a quick look at the previous version of our previous solution.
SharePoint Indexer V1
For further details about how our previous solution was built, we recommend you read this dedicated blog post, where we not only explain the steps followed when building it, but also show you how we implemented our InnoHub system to navigate company CoolThings and Customer Success Stories. In our updated version, we’ll keep most of the previous structure, as it was perfectly functional and without implicit limitations.

Figure 2: Custom tags
Additionally, custom views were created for the easy display and visualisation of these tags, as were custom folder content types, allowing us to extend this personalised tagging of the files to entire folders:
Figure 3: Custom folders
Now that all the data was properly tagged, we created a navigation tool to explore it through our library. Power BI was the obvious solution as we use Microsoft services.
When figuring out a system to connect to this Power BI report, we had to rule out its built-in SharePoint Online List connector, due to performance issues with large volumes of data. Instead, we decided to use an Azure Function that would periodically extract the metadata from all the interesting files, and output it into a CSV file stored in a Blob Storage container inside Azure, which Power BI can connect to.
Despite the old SharePoint Indexer still being perfectly functional and operational, it did have some limitations, mostly related to the extraction of metadata from the SharePoint library.
Drawbacks
As we mentioned before, because the SharePoint Online List Power BI connector presented performance issues with high volumes of data in the libraries, we used a pipeline from Azure Data Factory to periodically execute an Azure Function to extract the metadata from all the files (full load) into CSV files.
This system presented some drawbacks: with relatively low volumes of data, like the ones we had back then, we could handle a daily full load overnight. However, for larger volumes, processing the load takes longer and this means metadata extraction is executed less frequently. And as the Power BI report uses the output data from that Azure Function, the more time between updates, the less reliable the report becomes (as the information becomes outdated).
Another inconvenience was the use of Azure Services and custom Python code. Despite not depending on them fully, they do require some specific knowledge to build and understand, complicating the maintenance of the Advanced SharePoint Indexer.
Now let’s take a look at the solution we came up with to overcome these limitations!
SharePoint Indexer V2
As we said, with our previous solution the limitations mainly affected metadata extraction, so we opted for a cleaner and more simple method using Power Automate, from Microsoft Power Platform (the same platform as Power BI).
Power Automate was already a part of our previous solution; it was actively used to update the possible values for the custom tags in SharePoint. In fact, in the original blog post, we even mentioned the use of Power Automate as an alternative to scan the SharePoint files to generate the CSV file that would be connected to the Power BI report.
Now, thanks to recent updates, Power Automate’s new functionalities can be leveraged to move all the metadata extraction work to this very platform. In fact, by using the Power Automate built-in triggers, we can maintain and update a near real-time item list of what is located inside our SharePoint libraries.
And talking about the item list, we considered different methods for storing the data, as Power Automate offered us connectors to different services. However, some of these connectors, like those for SQL servers or Microsoft Dataverse, meant a premium version of Power Automate. Others, like those for the management of Excel tables and SharePoint lists, don’t require a premium account.

Figure 4: Actions related to updating a row, with standard and premium alternatives
In our case, we chose the SharePoint list option, as it proved to be an extremely reliable and time-effective solution, and also offered an elegant view of the list contents.
With the intended modifications in mind, let’s have a look at the capabilities of Power Automate and how we used them to maintain a near real-time list of our files.
Power Automate
Power Automate is a tool from Microsoft Power Platform for the creation and management of highly customisable flows, logical groupings of actions that together perform a task.
These flows can be scheduled, triggered manually, or triggered by an event in some of the services which Power Automate can connect to. Specifically, for our use case, we selected the triggers activated after the creation, deletion, or modification of a file (or folder) inside a SharePoint library.
These flows will keep a SharePoint list updated to the present state of every file and folder in the library, along with their properties, as any change to the elements will quickly trigger the required flow to update the list. Thanks to these triggers, we will be able to keep a near real-time registry of the files and folders in our library, thus removing the need for a daily full load with other services like Azure Data Factory and Azure Function.

Figure 5: The SharePoint triggers used
Now let’s see how they really work!
Proposed Solution
The most interesting triggers available for our specific case are “When a file is created or modified” and “When a file is deleted”, which will greatly determine the functionality of our flows.
Register (cre/mod)
For the first case, the flow will be triggered with each and every file or folder creation or modification. It’s important to know what Power Automate understands as a modification, and further on in this blog post we’ll see that essentially it implies a change in the modification date. But anyway, when the flow is triggered, it will get the properties from the involved file.
This trigger will also give us enough information to create a new item in the SharePoint list. However, there may be no need to create a new item, as the flow could have been triggered by a modification, in which case the file will already have an entry in the list.
After dealing with this differentiation, the flow will be ready to either create a new item in the SharePoint list after a file creation, or update the SharePoint list item when a file is modified:
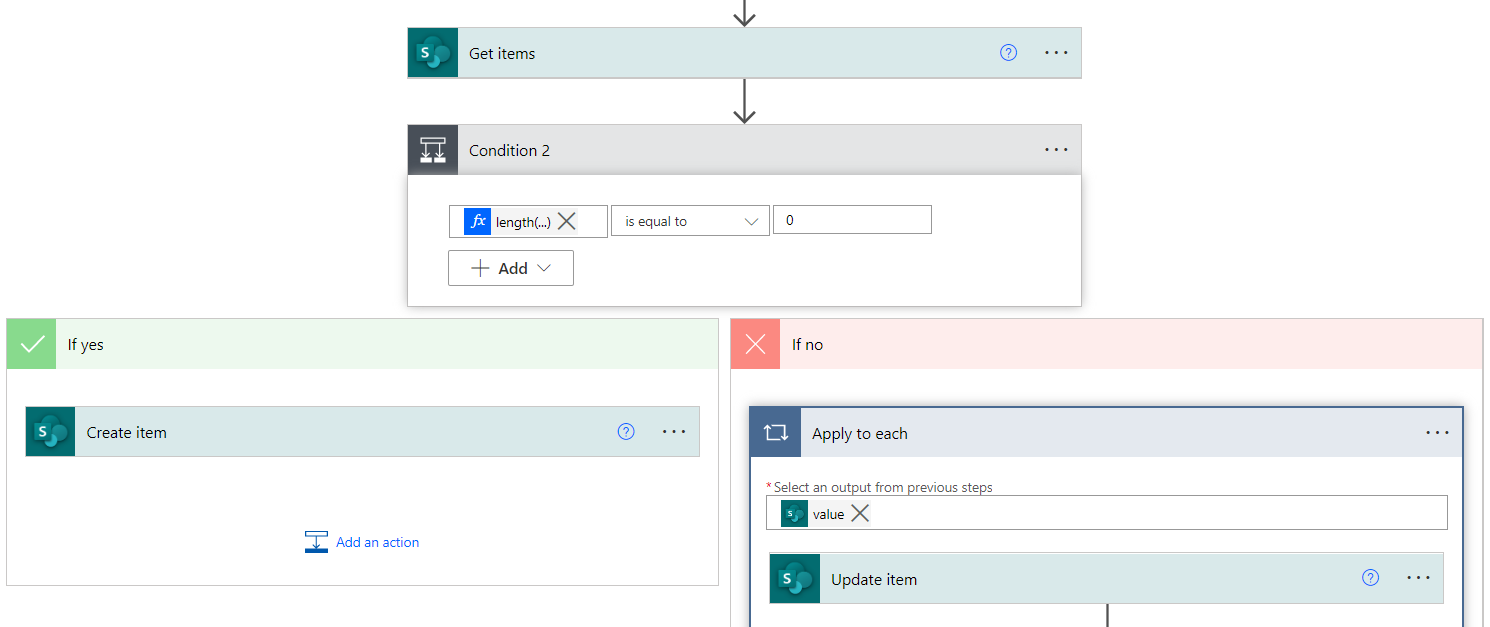
Figure 6: Discerning between the creation and modification of a file
On top of this, we’ll add a condition to ensure that the creation or modification has taken place inside a folder we are interested in (we are not indexing all of SharePoint, only some specific folders):
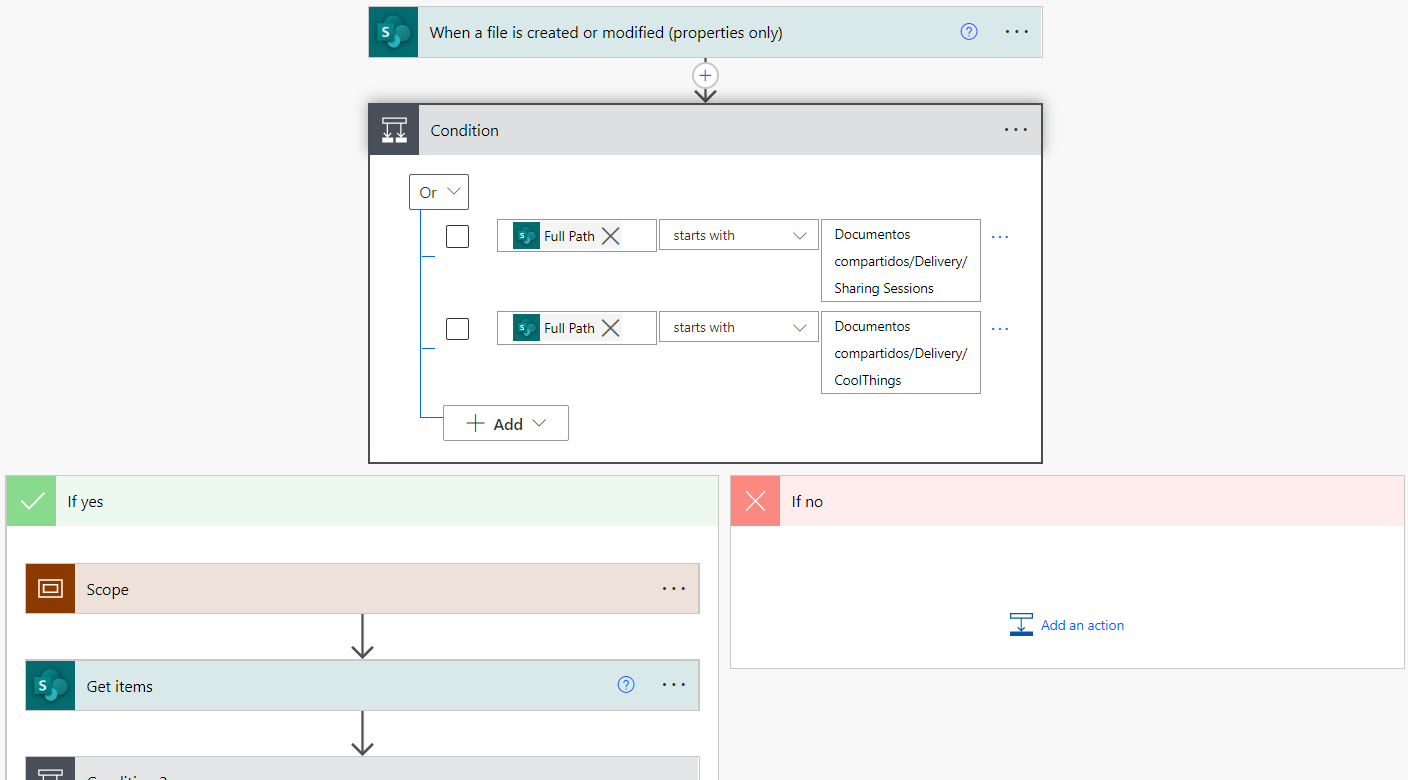
Figure 7: Folder check within the flow
Finally, the flow will also solve an issue within Power Automate that could lead to unwanted results when modifying some properties of a folder like the name, as it would only trigger the flow for the folder, and all the files inside would keep the old path.
Register (del)
There will be another flow that is triggered by the deletion of a file or folder, which will delete the SharePoint list items as they are no longer present in the SharePoint library.
As with the previous flow, recursive deletions are not supported natively, meaning that when deleting a folder, despite all the elements being deleted from the SharePoint library, only the folder will trigger the flow, and so only the folder will be deleted from the SharePoint list. To solve this problem, we used a similar approach to the creation flow, querying the list for items whose path begins with the folder’s, then deleting them:
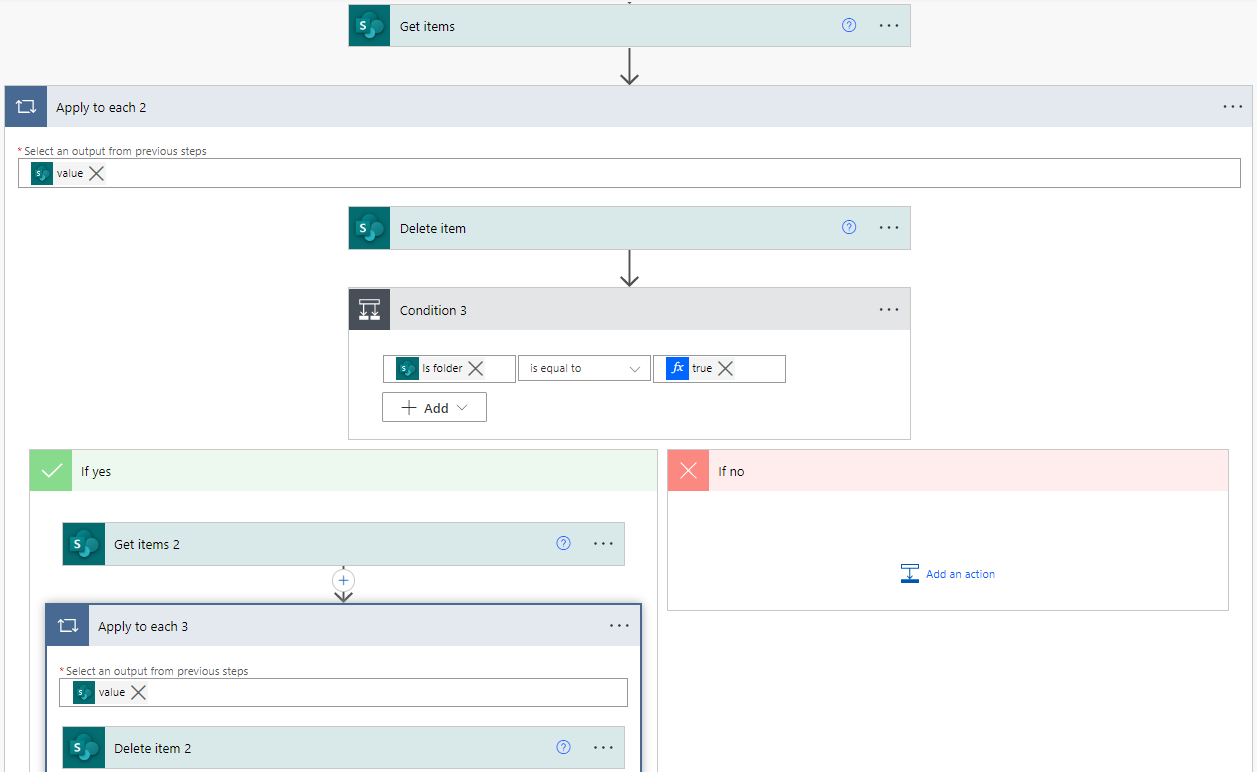
Figure 8: Core of the Register (del) flow
We have to consider the possibility of race conditions between this flow and the creation flow. We’ll look at this in the Limitations section; in a nutshell, the deletion of a folder followed by a fast reupload of the same folder could lead to the new files being added to the registry before the deletion flow has erased the old ones, and the deletion flow would not only delete the old ones, but the new ones too.
Integrity Load
Apart from the flows discussed above which are triggered by events in our SharePoint, we can also trigger flows manually or have them scheduled to run periodically without any interaction:
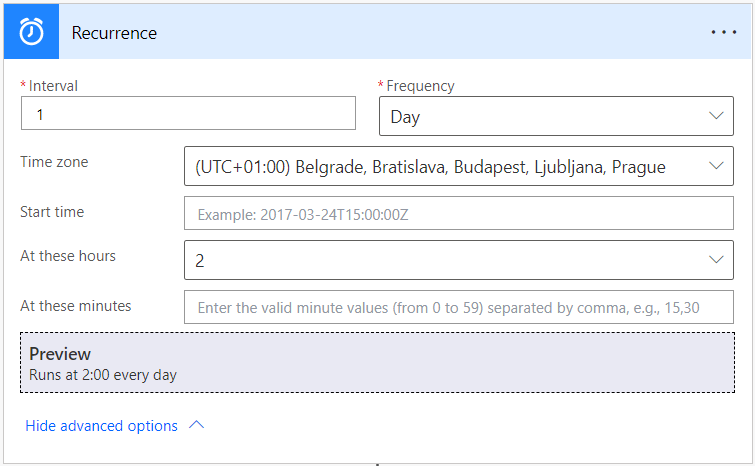
Figure 9: Power Automate Recurrence trigger
This is what we’ll do for the integrity load – this flow will be triggered periodically, and will perform a search of the monitored folders in the SharePoint library and update the SharePoint list with the current state of each file and folder, leaving a clean list without errors or imperfections. As we’ll see below, this will allow us to work around certain limitations with regards to events that do not trigger the flows to update the SharePoint list with modified items (for example when an item is moved), or with regards to possible race conditions that leave the SharePoint list in an inconsistent state.
Something worth mentioning about the integrity load is that, as we’ll see later, Power Automate has a limitation of 5k iterations per loop, meaning that for libraries with more than this number of files we will need more than a simple “Get files” command. We opted for a solution that will perform a “Get files” action first to obtain the files and folders from the first designed level, and then perform another “Get files” action pointing to the specific folder from the folders obtained. This way we will still have the 5k files iteration, but it will be moved a whole level below, solving the issue in most cases, just as in our own.
During the design process, we also came up with a couple of alternative solutions for different types of data hierarchy, but we settled with the one we’ve described as it fit most of our future cases. Finally, the integrity load flow will get the properties of each of those files, and forcedly create or update their entry in the SharePoint list:
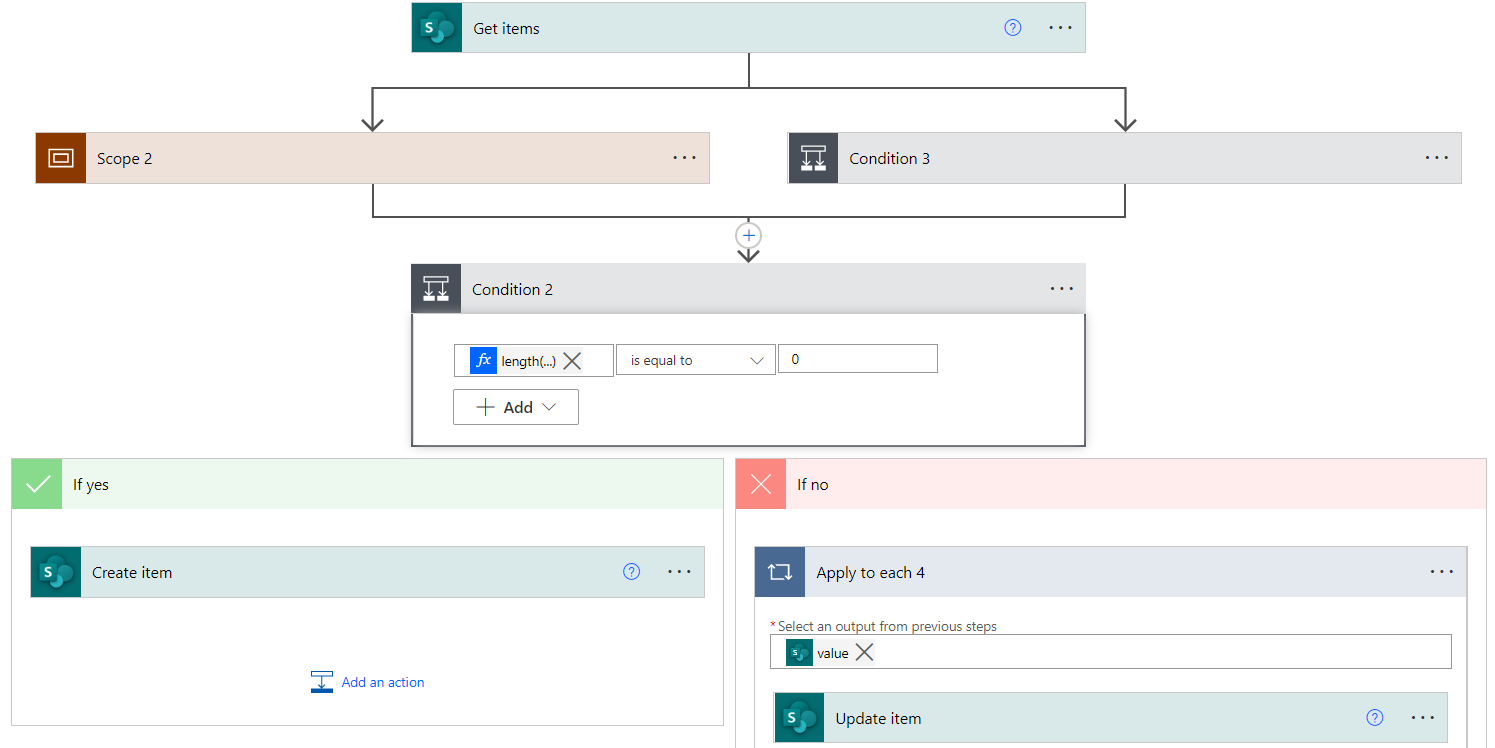
Figure 10: Core of integrity load flow
Note that this flow can be used for the initial load, as it will effectively yield a full and up-to-date list with the properties from all the files and folders available in the SharePoint library.
Talking about the list, and how to perform the initial load to an empty list, let’s see how to create a SharePoint list!
SharePoint Lists
Within a SharePoint site, we can create lists, collections of data to share and view from the Microsoft 365, Teams, or SharePoint platforms.
As these lists are highly integrated with SharePoint and most Microsoft platforms, they are easy to create through the UI in Microsoft lists (which can be found as an app in Office, or from any SharePoint site). There we can choose one of the available templates or create a blank list.
For our specific use case, we created a blank list, to which we added a column for each of the properties we wanted to keep track of (file name, ID, path, modified date, check date, link, and all the previously added custom tags). Additionally, SharePoint lists enabled us to define the allowed values for each column; from the format (string, integer, date, choice, etc.) to the special conditions like the uniqueness of the ID (eliminating the possibility of duplicate entries in our registry).
Unfortunately, there are some intrinsic drawbacks to the Power Automate service. Most of them can be solved with workarounds or creative solutions, but others are simply limitations of which we need to be aware, keeping an eye out for potential issues.
Limitations
Apart from the limitations that we’ve already seen with the flows, we will face some other complications due to the use of Power Automate, the SharePoint connector, and SharePoint functions and triggers.
Firstly, we can only perform 600 API calls per connection per minute, meaning that within all our flows, only 600 SharePoint functions can be performed per minute, limiting the maximum number of flows that can be executed simultaneously or in short periods of time. We had to think up a workaround for the initial load, the point where more files will be trying to create new elements in the list.
Additionally, due to the way Power Automate flows are built, each loop can only handle a maximum of 5k iterations (in the lowest performance tier), meaning that each file request from SharePoint libraries or each item request from the SharePoint list will only be able to retrieve a maximum of 5k elements. This is not a big problem for small sets of data, but when it comes to larger sets we need to bear this in mind, as some functionalities would require recursive loops to get over this limitation; this is the case, as mentioned above, when using “Get files”.
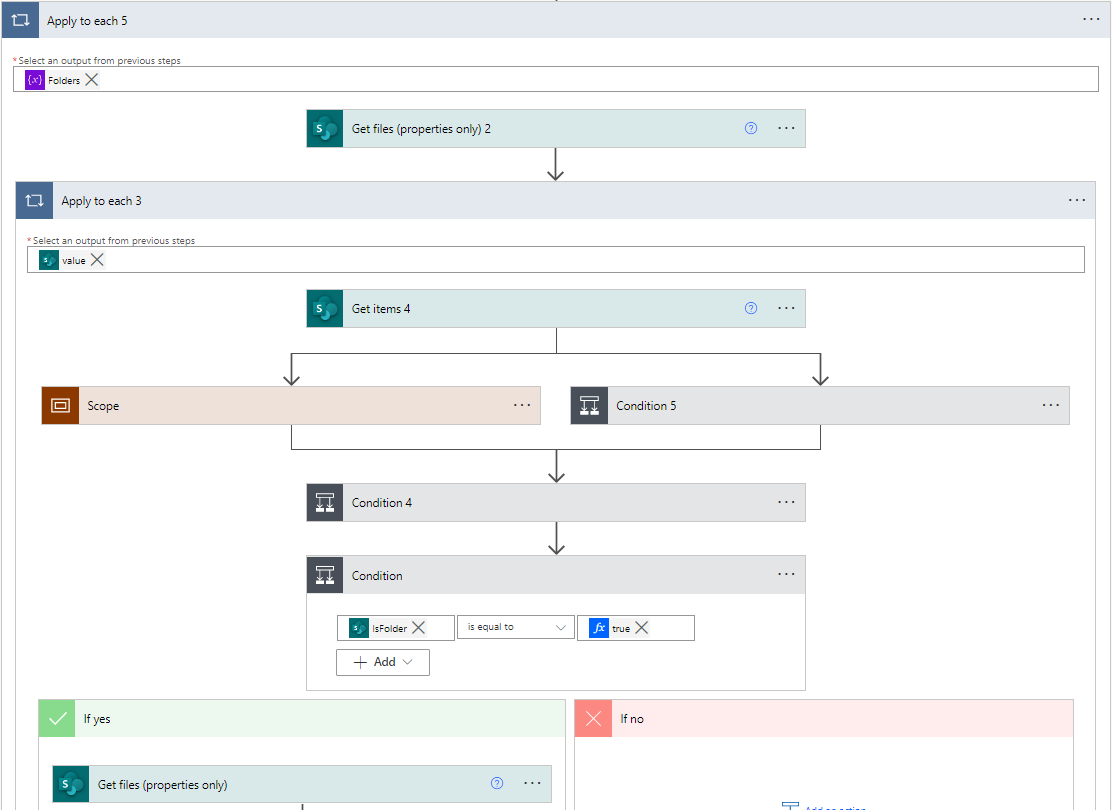
Figure 11: “Get files” inside a loop, which itself is inside a loop to get over the 5k iterations limit
Another important limitation of SharePoint triggers lies in what we understand as a modification of a file. Specifically, our flow responsible for creating and updating items from the list will be triggered when a file or folder is created or modified. However, because of this peculiarity, only those events in the file or folder that imply a change in the modification date will trigger our flow.
This implies that events like moving a file from one folder to another (as it keeps the old modification date) will not trigger our flow, leaving the path from the SharePoint list outdated. On the other hand, changing the content of a document, despite leaving all its list properties intact, will trigger the flow because it changes the modification date. As they say in their own documentation:
“When you move one or more files from one document library to another, the original file is moved from the source library to the destination library. Moving the file does not alter any custom metadata, including when the file was created and modified. Hence, this action does not trigger any flows for those file updates associated in the library where it was moved.”
As we have already pointed out, when an event triggers a flow, we are given the properties of that file, but some of these events might change the properties of more than one element. For instance, by changing the name of a folder, we also change the path to all the files it contains; or when deleting a folder, we also delete all its files. In these cases, we needed a Get items function to filter the path in the flows to retrieve the folder elements and then to apply the same logic as the triggering element (update or delete the item).
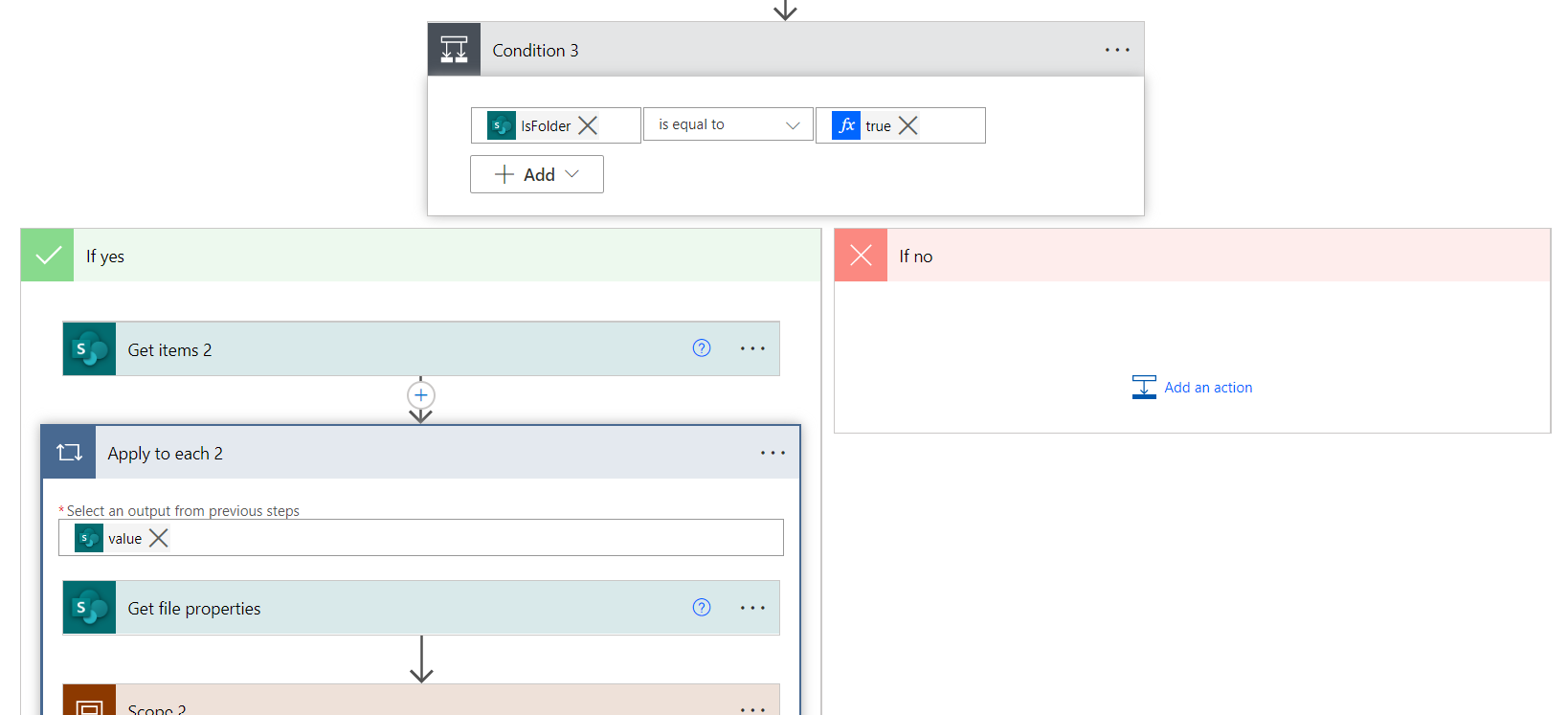
Figure 12: Workaround for folder modification
Remember that the flow triggers are only near real-time; they work by periodically scanning SharePoint for changes, and all the changes found in each scan will run simultaneously, leading to some specific problems: if we delete a folder and immediately afterwards reupload it, that specific folder will have no issues, as reuploading changes the element ID.
However, because of the limitation mentioned in the previous paragraph, our delete flow will look for elements in the list with the same path as the deleted folder, and if the new elements are added to the list before the deletion flow has finished executing, these new elements will also be deleted from the list.
This issue can be addressed by making the delete flow pause the creation flow while running, as it will prevent the items from being created while the previous ones are being deleted, or by forcing a delay in the creation flow longer than the recurrence time of the deletion trigger.
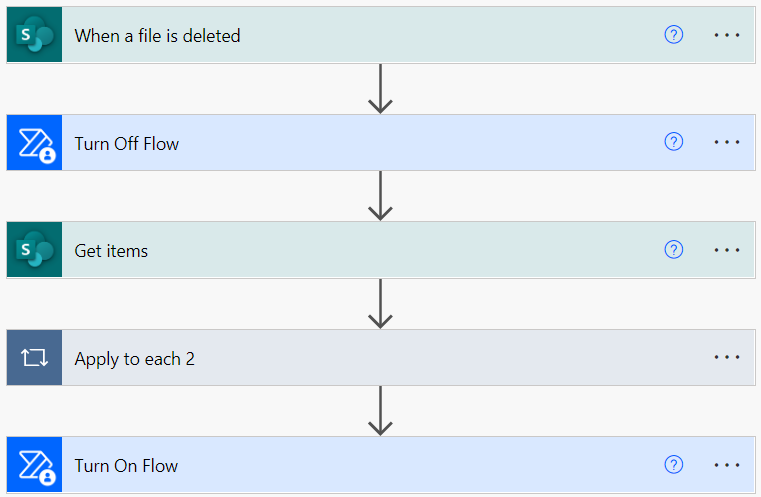
Figure 13: Creation flow being paused when deletion flow is in execution
To solve all these issues, our recommendation (and what we do internally) is to combine the SharePoint list updating provided by event triggers with the integrity load, which will fix most of the inconsistencies that might have been caused by actions that do not trigger events (like moving an item).
In our specific use case, InnoHub, we found another problem: for all the files and folders, there’s a link in the Power BI report that will lead us to the resource in the SharePoint library. However, this is not the case with blogs, where the link will lead to our website (where you are right now!). As Power Automate has no native way of retrieving that information from URL files, we had to create a workaround where we extract the content of the URL file, decode it from base64, and then extract the part that references the destination link:
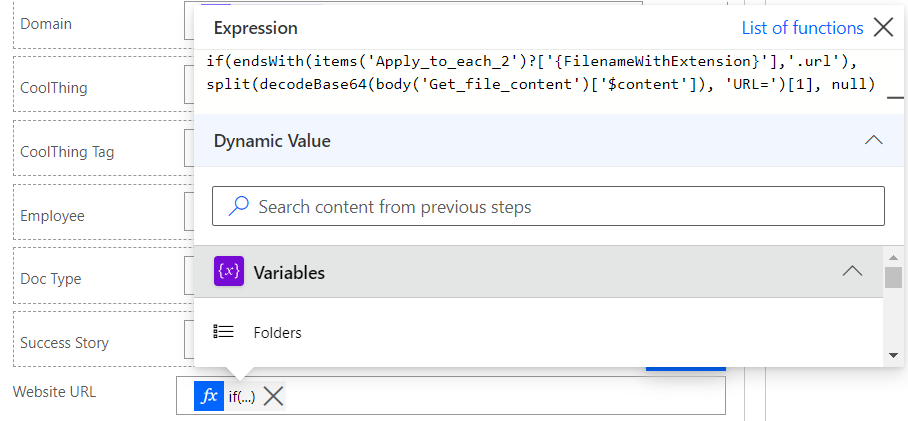
Figure 14: Expression used to obtain website URL from blog links
As we can see in this image, because of a Power Automate issue dealing with null variables, we had to use a conditional inside the same expression to add only the website URL property to links.
These expressions in Power Automate are highly capable and very useful in lots of situations, and in some cases, like ours, where we needed to decode a base64 string, it saved us from having to use an external premium action.
Power BI
Finally, we used the online SharePoint list connector inside Power BI to extract the data from the list to the report. Then the table was filtered to get rid of unnecessary information, and finally the columns were extended to adapt the table to the format that our previous report was used to retrieve data from:
Figure 15: SharePoint Online list as source for a Power BI table
There are some issues concerning the migration of data from the SharePoint list to Power BI, like dates and times (which in SharePoint are saved as UTC but are shown and exported in local time), or links to the same SharePoint site which get shrunk in the process. Nevertheless, all this can be corrected with data transformations from the Power BI side.
Conclusions
In the end, the metadata extraction performed by Power Automate will have two very differentiated advantages when compared with the previous solution.
First, Power Automate will replace the Azure services that performed the full load of the SharePoint metadata, with the integrity load flow, offering a simpler alternative, as it requires less services whilst using an easier to understand (and therefore to maintain) platform.
And finally, with the other flows (Register (cre/mod) and Register (del)) we will have access to a near real-time registry of each file with its metadata, leading to more up-to-date reports, and allowing us to run time-consuming full loads less frequently.
However, the use of Power Automate services does come with some specific limitations that have to be considered. Many of them (such as item moves or race conditions) can be fixed with periodic integrity loads, but some of them (like the 5k limitations in “Get items”) cannot, and special care needs to be taken with them.
On the Power BI side, we have seen an improvement in the simplicity of data ingestion, as it now comes from a single source rather than several individual files, maintaining functionality when compared to the previous model.
The result is a very capable and enhanced Advanced SharePoint Indexer, offering the same advantages and functionality as the previous version, whilst simplifying its structure and services, leading to an easier and faster maintenance. Additionally, with the use of the proposed event-triggered flows, the Advanced SharePoint Indexer gains near real-time capabilities to maintain an updated source more reliably.
If you think you could benefit from the Advanced SharePoint Indexer to easily search and navigate through your SharePoint libraries, don’t hesitate to contact us, and get to know the insights this service can provide in greater detail.
