
10 Feb 2020 Intelligent Talent Finder
In this article we present Intelligent Talent Finder (henceforth ITF), an AI tool developed by our team of data scientists. ITF takes candidates’ freeform resumes, parses, analyses, stores and indexes them, and then provides AI-powered methods to search through them via an intuitive web interface (see Fig. 1). ITF uses state of the art Machine Learning (ML) and Natural Language Processing (NLP) techniques to learn common patterns and different content distributions found in resumes as well as approximations of word meanings.

Figure 1: ITF Landing page
1. ITF Description
ITF is split into 3 modules as depicted in Fig. 2: Resume Parser, Resume Store and Web Viewer. Resume Parser reads unstructured data from resumes in PDF or DOCX formats with unfixed content distribution, and parses the content into semi-structured data. Then Resume Store processes this data – by using the knowledge acquired reading resumes, the data is enriched and converted into data structures that are stored in a specialized database (Solr) with advanced search capabilities. Finally Web Viewer enables the exploration of this data in multiple ways.
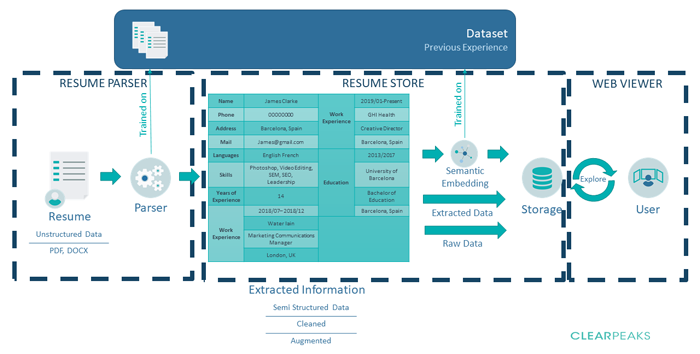
Figure 2: Simplified end-to-end diagram of the process performed by the 3 modules that compose ITF. A candidate resume is read, parsed and then pushed into a document store that can later be queried and analysed in a web browser
ITF empowers recruiters to skip tedious, repetitive steps when scanning through candidates’ resumes, and allows them to perform searches with a more intuitive approach. One could argue that scanning through a set of CVs is not a daunting task that requires AI help; this is true for organizations with few concurrent job openings and smaller sets of resumes per opening. However, as talent recruitment specialists can confirm, for a single job opening it is not uncommon to receive hundreds of resumes in response, so if you have many such job openings at the same time, you will face a potential scalability issue. It is in this context where one can easily grasp the benefits of an AI-powered tool that can assist in the overall recruitment process; because of the scalability issue described, in which organizations can easily pile up thousands of resumes for just few job openings, we took scalability as a hardcore requirement for ITF, and hence all ITF modules can run in computer clusters that can scale easily when needed.
To summarize, here are the main problems ITF tackles, and how they are solved:
- Extract meaningful information from resumes with wildly different content distributions, sections, and even languages using an AI-powered parser.
- Normalize and store this data using a scalable document store and search engine.
- Explore the data through advanced search capabilities using semantic embeddings.
- Handle asymmetrical spiking workloads and performance requirements enabled by the modular architecture of ITF.
- Provide all these services in an easy-to-use interface capable of augmenting recruiter search capabilities.
2. Ethical
Before jumping into technical details and considering the nature of ITF as a tool to select and rank human beings, it is important to state some of the ethical requirements taken into account when creating the ML models used in ITF. Actually, we believe that such ethical requirements should be taken into account for any ML model that is used to directly select and rank humans; contrary to some common beliefs, algorithms may not be fair, and without an active effort they will end up adopting the same biases that humans have, or even worse, amplifying them. We believe that ITF can have both, a positive and a negative effect on recruiting biases, so we must make a constant effort to push it towards the positive. For this reason, we apply the following techniques:
- Debiasing: This technique removes biases on the knowledge that the model acquired by reading lots of text. The objective is that attributes such as race, gender or age do not have greater impact over the other characteristics extracted from the CV. This is an extremely complicated problem, and a considerable amount of research has been carried out, such as [1,2,3]. The topic has recently been in the spotlight of major conferences such as the Association for Computational Linguistics (ACL). Experts agree that current debiasing alone might not be enough enough [4,5], so ITF also applies a much more definitive solution to avoid the model exploiting the candidate’s characteristics, based on not giving it any sensitive data in the first place, – masking all the information from sections of the resume that are not relevant. This ensures, for example, the same work experience section will be parsed exactly the same regardless of the resume it is found on.
- Interpretability: Adding a way for the model to explain its decisions, when the model shows candidates for an employment offer, it should also provide a reason for doing so: why these skills were considered more relevant than others and why this candidate appears higher.
These are the techniques we are using to ensure the model has a positive effect on the world – and we are continuously working on detecting, preventing and eliminating possible biases.
3. ITF Data Exploration
ITF provides an easy-to-use web interface, in which we can analyse the data of all the candidates stored in the system. We do so by showing the original resume on the right, and all the extracted information on the left, as can be seen in Fig. 3. At this point it is important to note that the resumes that can be seen in this article are mock CVs of fictional characters.
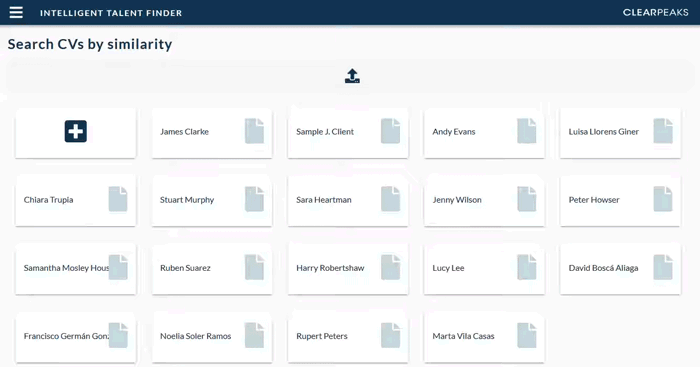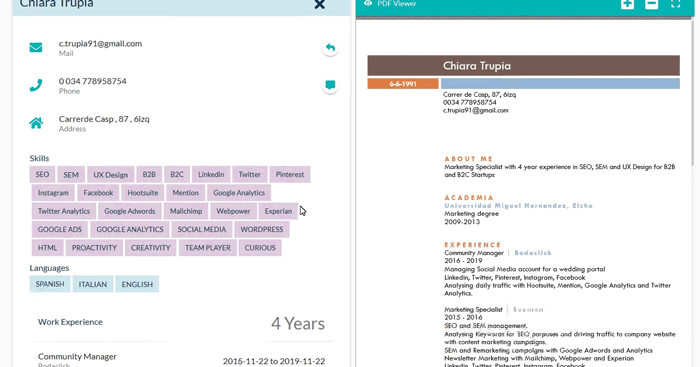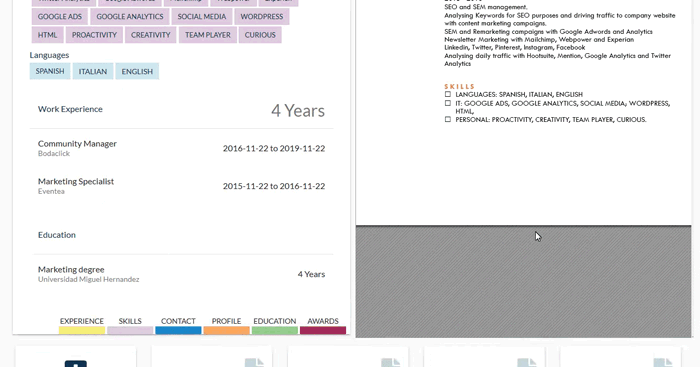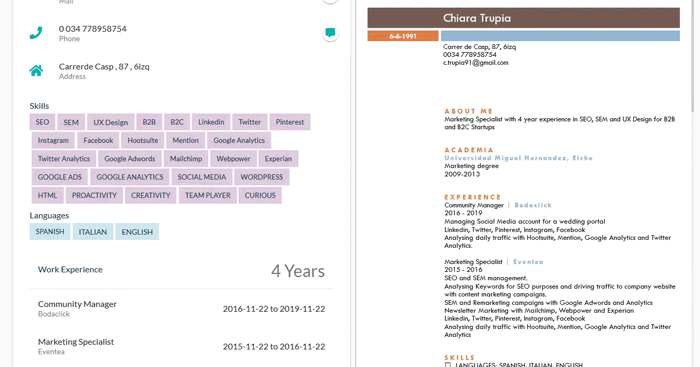
Figure 3: Example of how the resumes stored in the ITF Resume Store appear in the ITF web interface.
While this allows us to explore all the data stored in one profile, for ITF to be really useful, we need capabilities to perform searches through multiple profiles.
3.1. Top Candidates
This is the core search capability of ITF which allows us to define the candidate profile we want to retrieve by defining desired properties and filters. For example, we can specify a couple of languages, a range of years of work experience and a set of skills. Then the search engine of the ITF Resume Store will scan through the stored profiles and order them by how well they match these requirements; we can see an example of this in Fig. 4.
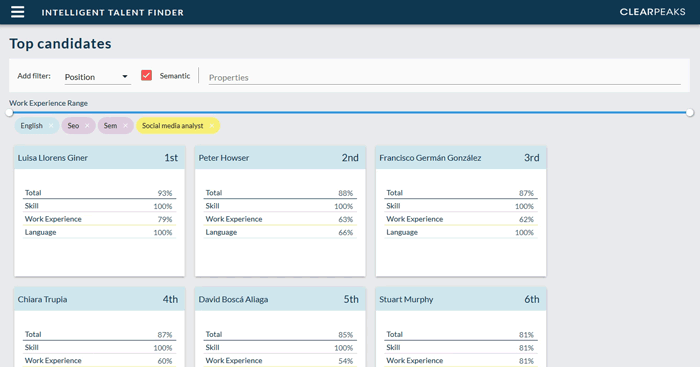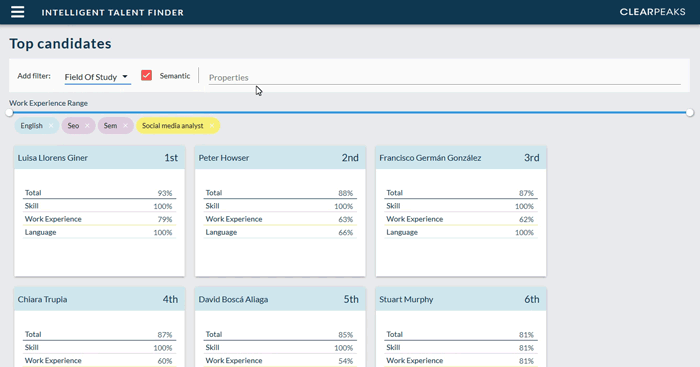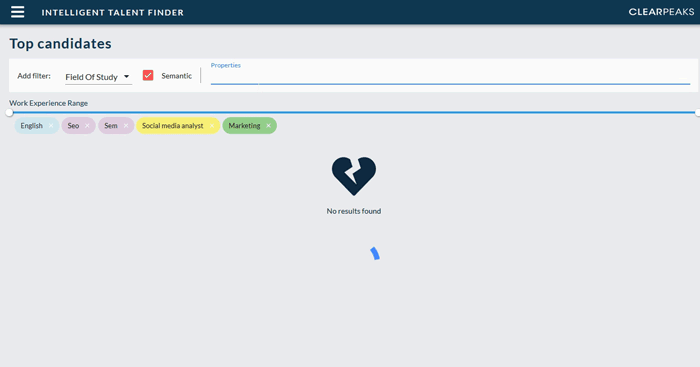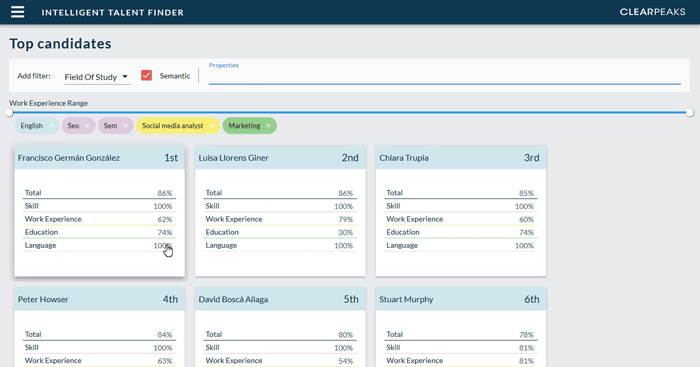
Figure 4: Example of the search engine in the ITF Resume Store sorting the candidates based on how close they match the specified search parameters. Note that adding a new search parameter (in this case to indicate our preference for candidates that studied marketing) reorders the results.
For Skills, Field of Study, Job position and Language, ITF also offers the possibility of using semantic matching, in which by using the embeddings (roughly a numerical representation of the semantic meaning of a word, sentence or token) of the words, we can obtain a match if the model believes that the concepts are close, regardless of the actual syntax of the word used. This can be more clearly seen with the example shown in Fig. 5.
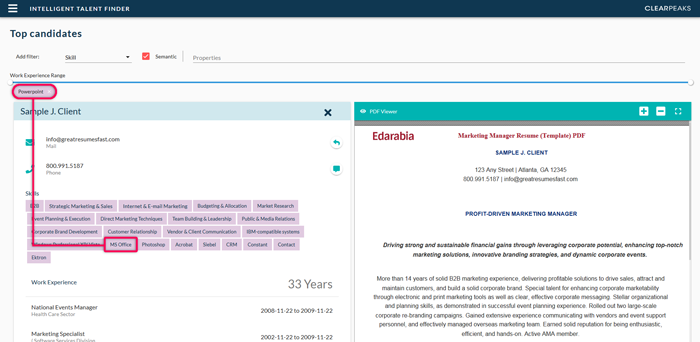
Figure 5: Example of semantic search in ITF. By searching the skill “PowerPoint” with the Semantic checkbox checked, ITF retrieves a resume that contains the skill “MS Office” because it has seen enough resumes to infer that PowerPoint is semantically related to Microsoft Office.
This functionality can always be disabled per filter basis, by unchecking the Semantic checkbox. This is important to avoid the frustration caused by the “always on spellchecker” problem where the expert user wants to do some unconventional but useful workflow and the intelligent features obstaculize it.
3.2. Job Profile Matcher
Another way to search through the candidates on ITF is to use the Job Profile Matcher. This functionality allows us to upload the resume of an ideal candidate, then the system will search through all the stored profiles to find the ones whose profile best matches the uploaded resume.
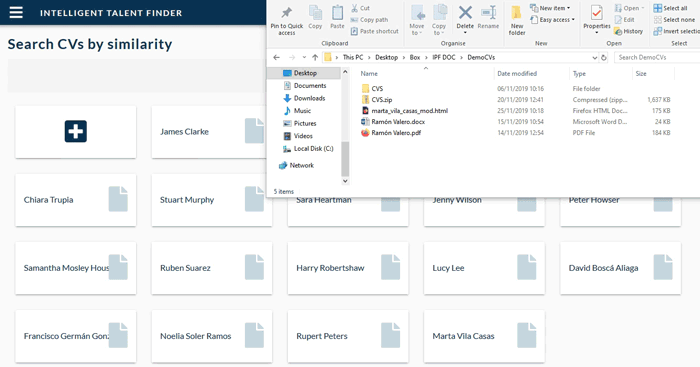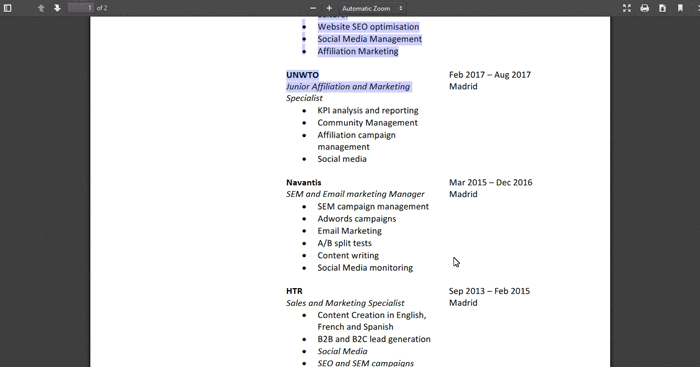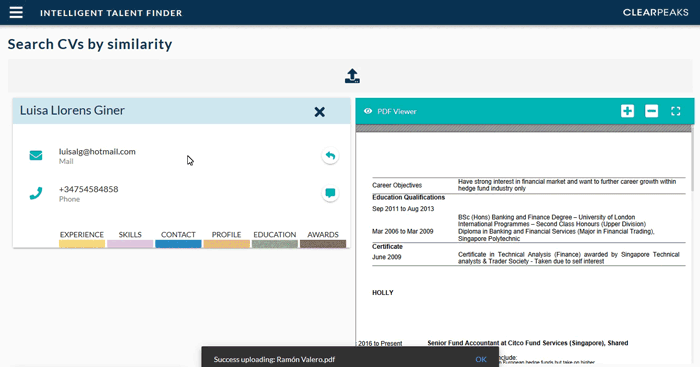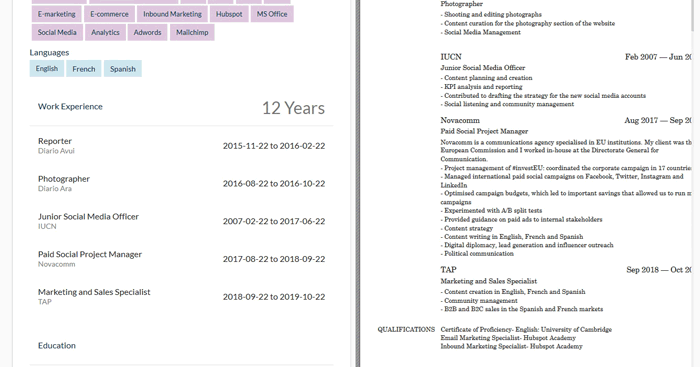
Figure 6: We use the Job Profile Matcher functionality to take a resume of someone who has worked as a reporter and SEM specialist, and ITF retrieves a profile in our system that has similar work experience and skills
The functionality can be seen in Fig. 6 and can be a useful shortcut to many common HR tasks such as easily kickstarting teams, filling unexpected vacancies, etc.
3.3. Context Search
The last search method consists of querying the raw text of all the available resumes. This search is one of the main features of Solr, one of the underlying technologies in ITF Resume Store, and it allows for query logic such as “(volunteer AND charity) OR education” as well as useful NLP features such as searching stemmed words.
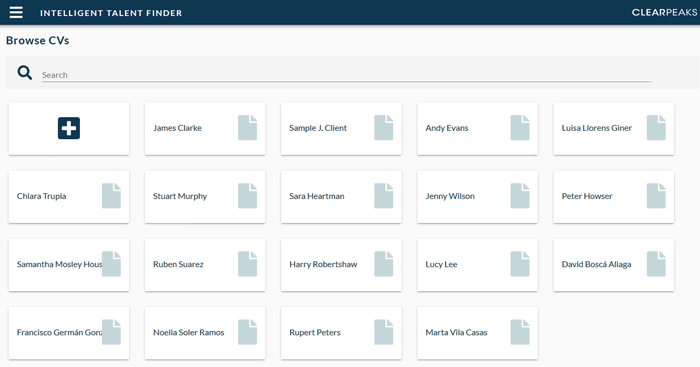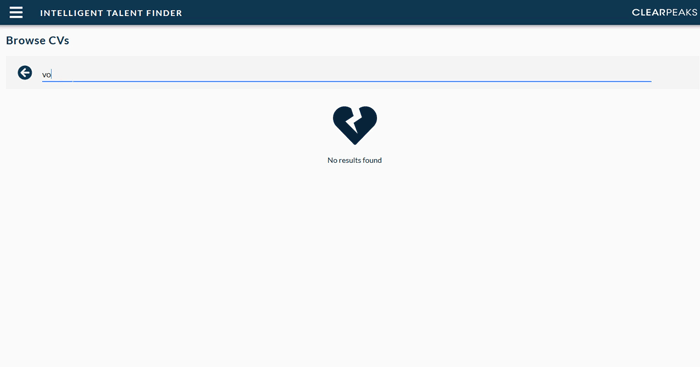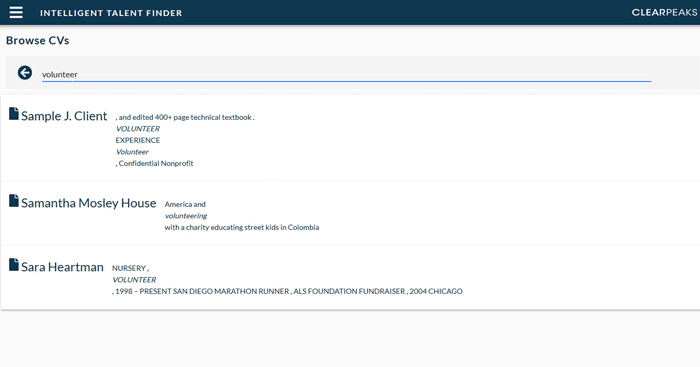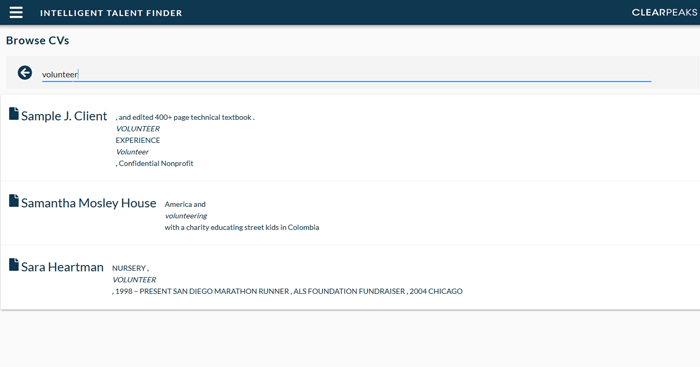
Figure 7: Context Search functionality
4. Technical Details
As a short insight into how ITF accomplishes these tasks, we now offer a quick overview of the key decisions in designing and implementing ITF.
4.1. Document pre-processing
First, ITF transforms the resume into something that can be fed into the ML model used for parsing. Note that naively taking all the text in the document as a whole would result in the model losing huge amounts of information embedded into the content distribution, so what ITF does is to split the resume into segments as the example illustrated in Fig. 8.

Figure 8: Example of two segments extracted from a resume; note that some of them may contain incomplete lines that have been split over multiples segments
Then ITF does some surgery, splitting and merging these segments to create the correct paragraphs while applying NLP pre-processing techniques such as cleaning and tokenizing.
4.2. Name Entity Recognition
With the clean tokenized data now available, we can feed the ITF model, which consists of an BiLSTM + CRF base network with additional changes to engrave expert knowledge of our problem into the architecture.
One of the most important decisions when building this model was selecting which embedding technique/model to use for transfer learning as there are several prominent choices such as BERT, ELMo, FastText or RoBERTa. Each of these methods has its own pros and consso we did exhaustive analyses, evaluating their performance, multi-language capabilities, response time and ease of finetuning. It is interesting to note that while the new fancy transformer methods did perform better and ended up being chosen, they were not so far off from some more traditional embedding techniques.
4.3. Storage
Before actually storing the data, ITF Resume Store uses the finetuned embedding model to generate the embeddings containing an approximate numerical representation of the semantic meaning of the relevant fields. This is what powers the Top Candidates semantic search capability illustrated in Fig. 5. As discussed earlier, ITF Resume Store relies on Solr to store the data. Solr is an open-source document store and search platform that comes prepared to handle semi-structured data. We have added a custom plugin that allows Solr to perform the mathematical operations required for the embedding similarity searches.
4.4. Deployment
Multiple docker containers are used to deploy ITF, enabling it to quickly scale any part or module in the system that might become a bottleneck. The Flask server is only tasked with providing the API and managing the workers, which will take on all the machine learning and other heavy lifting. An overview of the architecture can be seen in Fig. 9.
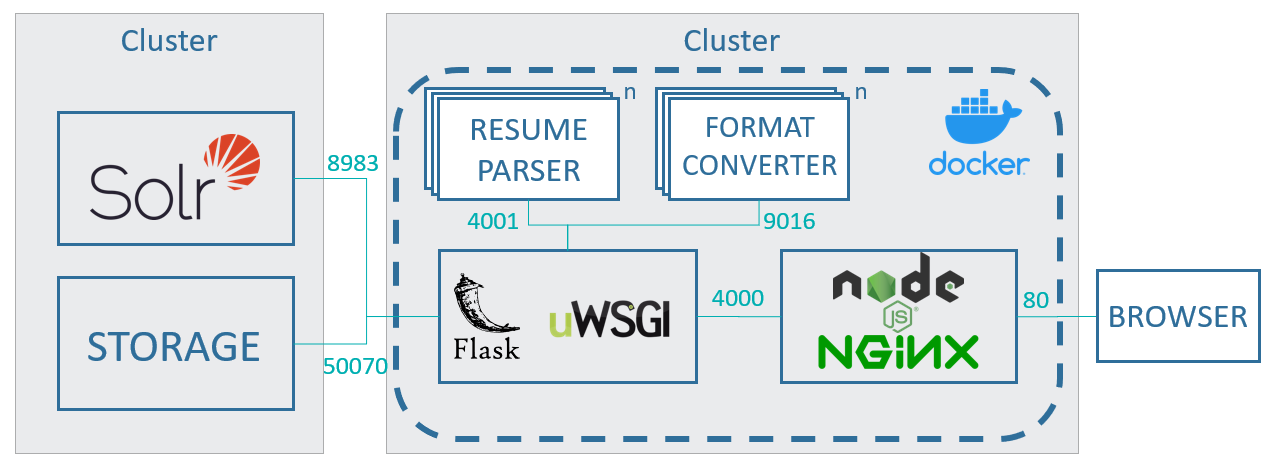
Figure 9: Architecture of ITF highlighting the main technologies used
Conclusion
In this article we took a dive into ITF and its approach to solving the resume parsing and exploration problem. ITF is based on three modules: Resume Parser, Resume Store and Web Viewer. One of the benefits of this modular architecture is that you can replace or customize any of the modules independently. For example, one may replace the existing Web Viewer for an already existing front-end framework in your organization. At ClearPeaks we are experts in AI and ML and we can assist you in customizing ITF for your needs so it can provide value to your organization. Please do not hesitate to contact us with any queries – we will be happy to help you!